Syntaxe:
Il existe une variété de services fournis par Hugging Face, mais l'un de ses services largement utilisés est 'API'. L'API permet l'interaction de l'IA pré-formée et des grands modèles de langage avec différentes applications. Hugging Face fournit les API pour différents modèles, comme indiqué ci-dessous :
- Modèles de génération de texte
- Modèles de traduction
- Modèles pour l'analyse des sentiments
- Modèles pour le développement d'agents virtuels (chatbots intelligents)
- Classification et modèles de régression
Découvrons maintenant la méthode pour obtenir notre API d'inférence personnalisée de Hugging Face. Pour cela, il faut d'abord commencer par s'inscrire sur le site officiel de Hugging Face. Rejoignez cette communauté de Hugging Face en vous inscrivant à ce site Web avec vos informations d'identification.
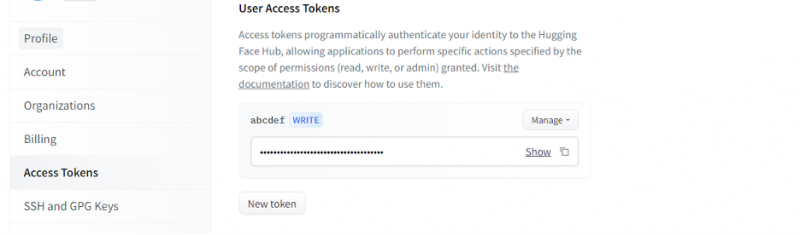
Une fois que nous avons un compte sur Hugging Face, nous devons maintenant demander l'API d'inférence. Pour demander l'API, allez dans les paramètres du compte et sélectionnez le 'Jeton d'accès'. Une nouvelle fenêtre s'ouvrira. Sélectionnez l'option 'Nouveau jeton', puis générez le jeton en fournissant d'abord le nom du jeton et son rôle en tant que 'WRITE'. Un nouveau jeton est généré. Maintenant, nous devons enregistrer ce jeton. Jusqu'à ce point, nous avons notre jeton du visage étreignant. Dans l'exemple suivant, nous verrons comment nous pouvons utiliser ce jeton pour obtenir une API d'inférence.
Exemple 1 : Comment créer un prototype avec l'API d'inférence de visage étreignant
Jusqu'à présent, nous avons discuté de la méthode pour démarrer avec Hugging Face et nous avons initialisé un jeton de Hugging Face. Cet exemple montre comment nous pouvons utiliser ce jeton nouvellement généré pour obtenir une API d'inférence pour un modèle spécifique (apprentissage automatique) et faire des prédictions à travers lui. Sur la page d'accueil de Hugging Face, sélectionnez le modèle avec lequel vous souhaitez travailler et qui correspond à votre problème. Supposons que nous voulions travailler avec la classification de texte ou le modèle d'analyse des sentiments, comme indiqué dans l'extrait suivant de la liste de ces modèles :
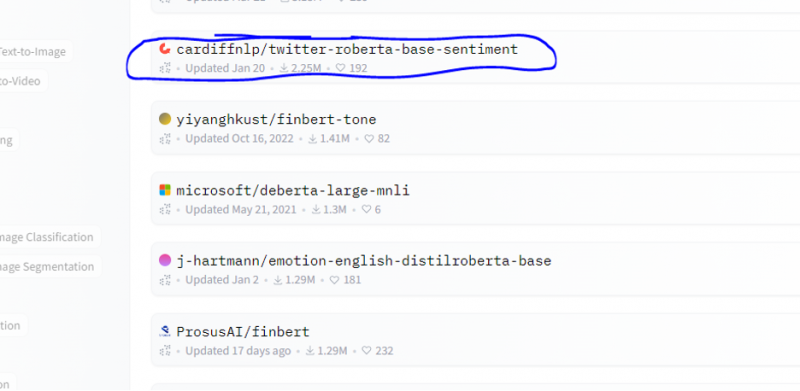
Nous choisissons le modèle d'analyse des sentiments à partir de ce modèle.
Après avoir sélectionné le modèle, sa carte de modèle apparaîtra. Cette carte de modèle contient des informations concernant les détails de formation du modèle et les caractéristiques du modèle. Notre modèle est roBERTa-base qui est formé sur les tweets 58M pour l'analyse des sentiments. Ce modèle a trois étiquettes de classe principales et il catégorise chaque entrée dans ses étiquettes de classe pertinentes.
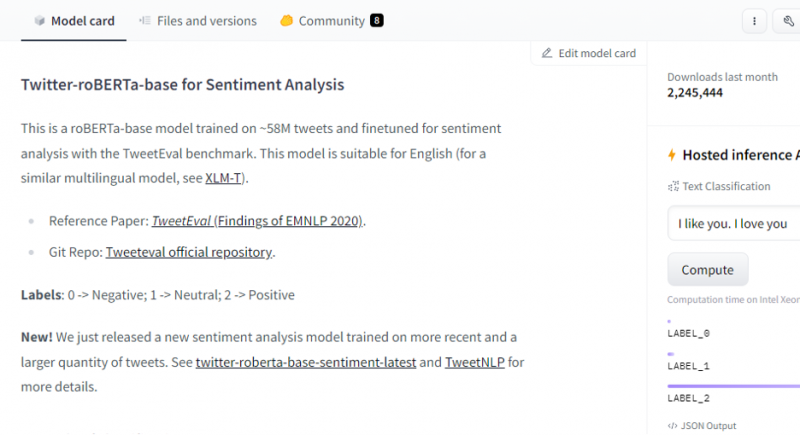
Après la sélection du modèle, si nous sélectionnons le bouton de déploiement qui est présent dans le coin supérieur droit de la fenêtre, il ouvre un menu déroulant. Dans ce menu, nous devons sélectionner l'option 'API d'inférence'.
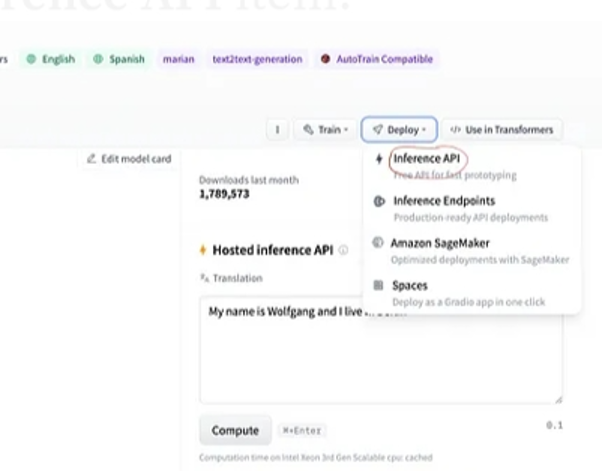
L'API d'inférence fournit ensuite une explication complète sur la façon d'utiliser ce modèle spécifique avec cette inférence et nous permet de créer rapidement le prototype du modèle d'IA. La fenêtre de l'API d'inférence affiche le code écrit dans le script Python.
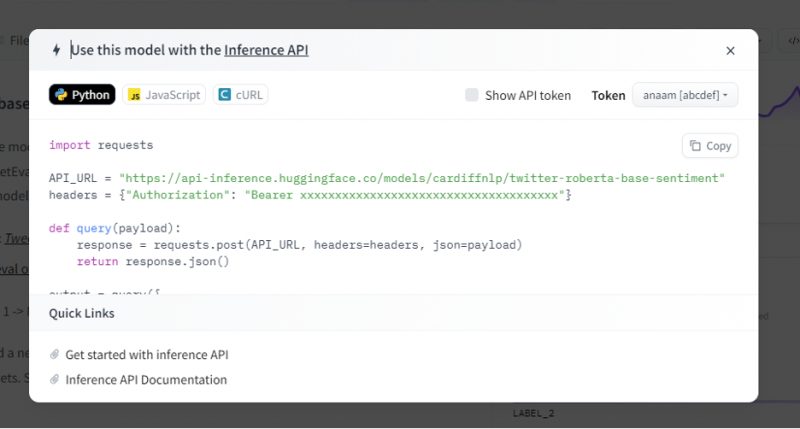
Nous copions ce code et exécutons ce code dans n'importe lequel des IDE Python. Nous utilisons Google Colab pour cela. Après avoir exécuté ce code dans le shell Python, il renvoie une sortie qui accompagne le score et la prédiction d'étiquette. Cette étiquette et ce score sont attribués en fonction de notre contribution puisque nous avons choisi le modèle « analyse des sentiments textuels ». Ensuite, l'entrée que nous donnons au modèle est une phrase positive et le modèle a été pré-entraîné sur trois classes d'étiquettes : l'étiquette 0 implique négatif, l'étiquette 1 implique neutre et l'étiquette 2 est définie sur positive. Étant donné que notre entrée est une phrase positive, la prédiction du score du modèle est supérieure aux deux autres étiquettes, ce qui signifie que le modèle a prédit la phrase comme « positive ».
importer demandesAPI_URL = 'https://api-inference.huggingface.co/models/cardiffnlp/twitter-roberta-base-sentiment'
en-têtes = { 'Autorisation' : 'Porteur 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' }
définitivement mettre en doute ( charge utile ) :
réponse = demandes. poste ( API_URL , en-têtes = en-têtes , json = charge utile )
retour réponse. json ( )
sortir = mettre en doute ( {
'contributions' : 'Je me sens bien quand tu es avec moi' ,
} )
Sortir:

Exemple 2 : modèle de synthèse par inférence
Nous suivons les mêmes étapes que celles indiquées dans l'exemple précédent et prototypons le bus de modèle de synthèse à l'aide de son API d'inférence de Hugging Face. Le modèle de résumé est un modèle pré-entraîné qui résume l'intégralité du texte que nous lui donnons en entrée. Accédez au compte Hugging Face, cliquez sur le modèle dans la barre de menu supérieure, puis choisissez le modèle pertinent pour le résumé, sélectionnez-le et lisez attentivement sa carte de modèle.
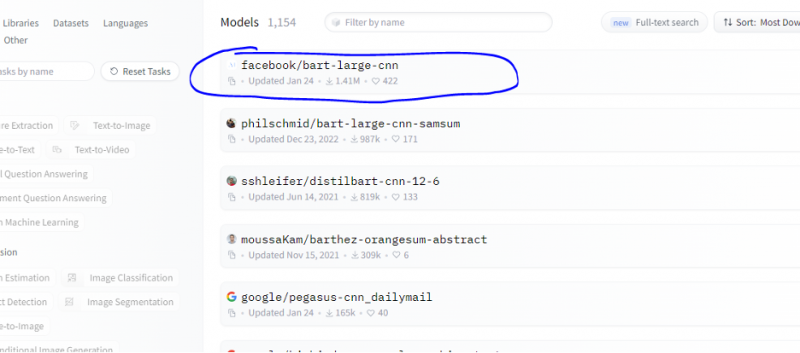
Le modèle que nous avons choisi est un modèle BART pré-formé et il est finement adapté à l'ensemble de données CNN dail mail. BART est un modèle qui ressemble le plus au modèle BERT qui a un encodeur et un décodeur. Ce modèle est efficace lorsqu'il est affiné pour les tâches de compréhension, de résumé, de traduction et de génération de texte.
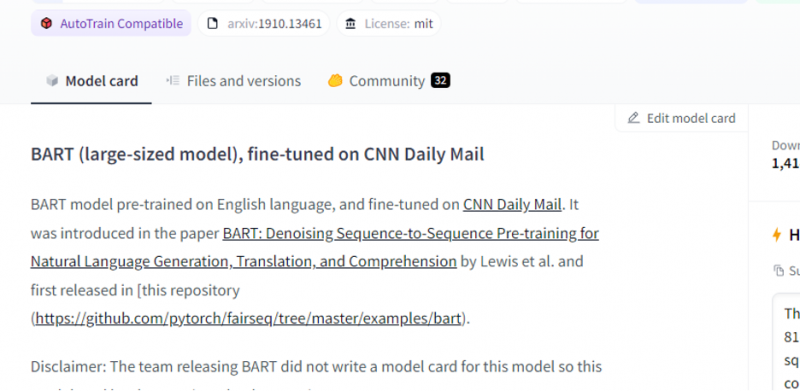
Ensuite, choisissez le bouton 'déploiement' dans le coin supérieur droit et sélectionnez l'API d'inférence dans le menu déroulant. L'API d'inférence ouvre une autre fenêtre qui contient le code et les instructions pour utiliser ce modèle avec cette inférence.
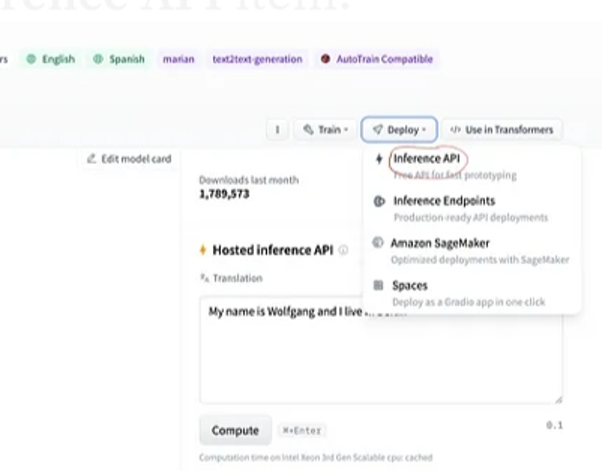
Copiez ce code et exécutez-le dans un shell Python.
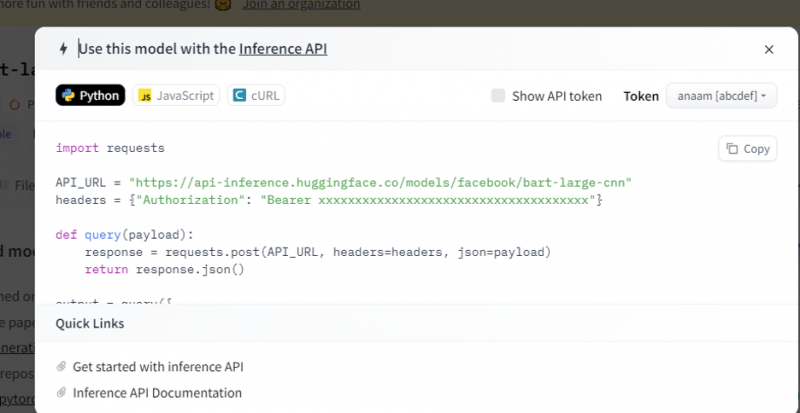
Le modèle renvoie la sortie qui est le résumé de l'entrée que nous lui avons fournie.

Conclusion
Nous avons travaillé sur l'API Hugging Face Inference et appris comment nous pouvons utiliser l'interface programmable de cette application pour travailler avec les modèles de langage pré-formés. Les deux exemples que nous avons faits dans l'article étaient principalement basés sur les modèles NLP. L'API Hugging Face peut faire des merveilles si nous voulons développer un prototype rapide en fournissant l'intégration rapide de modèles d'IA dans nos applications. En bref, Hugging Face a des solutions à tous vos problèmes, de l'apprentissage par renforcement à la vision par ordinateur.