Le multitraitement est comparable au multithreading. Cependant, il se différencie en ce que nous ne pouvons exécuter qu'un seul thread à la fois en raison du GIL utilisé pour le threading. Le multitraitement est le processus d'exécution séquentielle d'opérations sur plusieurs cœurs de processeur. Les threads ne peuvent pas fonctionner en parallèle. Cependant, le multitraitement nous permet d'établir les processus et de les exécuter simultanément sur différents cœurs de processeur. La boucle, telle que la boucle for, est l'un des langages de script les plus utilisés. Répétez le même travail en utilisant diverses données jusqu'à ce qu'un critère, tel qu'un nombre prédéterminé d'itérations, soit atteint. La boucle accomplit chaque itération une par une.
Exemple 1 : Utilisation de la boucle For dans le module de multitraitement Python
Dans cet exemple, nous utilisons la boucle for et le processus de classe du module de multitraitement Python. Nous commençons par un exemple très simple afin que vous puissiez comprendre rapidement le fonctionnement de la boucle for de multitraitement Python. Utilisant une interface comparable au module de threading, le multiprocessing packs la création de processus.
En utilisant les sous-processus plutôt que les threads, le package de multitraitement fournit à la fois la concurrence locale et distante, évitant ainsi le verrouillage global de l'interpréteur. Utilisez une boucle for, qui peut être un objet chaîne ou un tuple, pour itérer en continu dans une séquence. Cela fonctionne moins comme le mot-clé vu dans d'autres langages de programmation et plus comme une méthode itérative trouvée dans d'autres langages de programmation. En démarrant un nouveau multitraitement, vous pouvez exécuter une boucle for qui exécute une procédure simultanément.
Commençons par implémenter le code pour l'exécution du code en utilisant l'outil 'spyder'. Nous pensons que 'spyder' est également le meilleur pour exécuter Python. Nous importons un processus de module de multitraitement que le code exécute. Le multitraitement dans le concept Python appelé 'classe de processus' crée un nouveau processus Python, lui donne une méthode pour exécuter du code et donne à l'application parente un moyen de gérer l'exécution. La classe Process contient les procédures start() et join(), toutes deux cruciales.
Ensuite, nous définissons une fonction définie par l'utilisateur appelée 'func'. Puisqu'il s'agit d'une fonction définie par l'utilisateur, nous lui donnons un nom de notre choix. Dans le corps de cette fonction, nous passons la variable 'subject' comme argument et la valeur 'maths'. Ensuite, nous appelons la fonction 'print()', en passant l'instruction 'Le nom du sujet commun est' ainsi que son argument 'sujet' qui contient la valeur. Ensuite, à l'étape suivante, nous utilisons le 'if name== _main_', qui vous empêche d'exécuter le code lorsque le fichier est importé en tant que module et ne vous permet de le faire que lorsque le contenu est exécuté en tant que script.
La section de condition par laquelle vous commencez peut être considérée dans la plupart des cas comme un emplacement pour fournir le contenu qui ne doit être exécuté que lorsque votre fichier s'exécute en tant que script. Ensuite, nous utilisons l'argument sujet et y stockons certaines valeurs qui sont 'science', 'anglais' et 'ordinateur'. Le processus reçoit alors le nom 'process1[]' à l'étape suivante. Ensuite, nous utilisons le 'process(target=func)' pour appeler la fonction dans le processus. La cible est utilisée pour appeler la fonction, et nous enregistrons ce processus dans la variable 'P'.
Ensuite, nous utilisons le 'process1' pour appeler la fonction 'append()' qui ajoute un élément à la fin de la liste que nous avons dans la fonction 'func'. Comme le processus est stocké dans la variable 'P', nous passons 'P' à cette fonction comme argument. Enfin, nous utilisons la fonction 'start ()' avec 'P' pour démarrer le processus. Après cela, nous exécutons à nouveau la méthode en fournissant l'argument 'sujet' et en utilisant 'pour' dans le sujet. Ensuite, en utilisant 'process1' et la méthode 'add()' une fois de plus, nous commençons le processus. Le processus s'exécute ensuite et la sortie est renvoyée. La procédure est alors invitée à se terminer en utilisant la technique 'join()'. Les processus qui n'appellent pas la procédure 'join()' ne se termineront pas. Un point crucial est que le paramètre de mot-clé 'args' doit être utilisé si vous souhaitez fournir des arguments tout au long du processus.
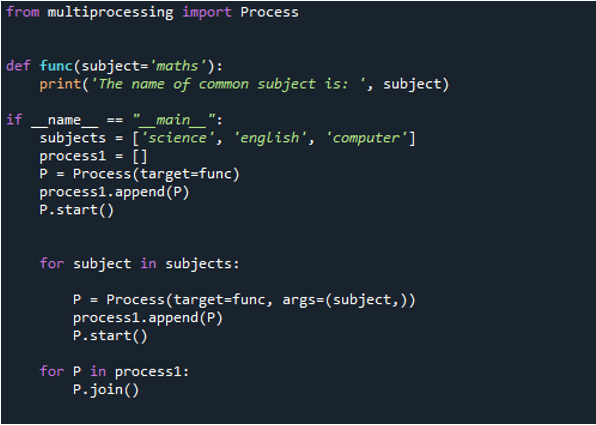
Maintenant, vous pouvez voir dans la sortie que l'instruction est affichée en premier en passant la valeur du sujet 'maths' que nous passons dans la fonction 'func' car nous l'appelons d'abord en utilisant la fonction 'process'. Ensuite, on utilise la commande « append() » pour avoir des valeurs qui étaient déjà dans la liste qui est ajoutée à la fin. Ensuite, « science », « informatique » et « anglais » ont été présentés. Mais, comme vous pouvez le voir, les valeurs ne sont pas dans le bon ordre. En effet, ils le font dès que la procédure est terminée et signalent leur message.
Exemple 2 : Conversion d'une boucle For séquentielle en boucle For parallèle multitraitement
Dans cet exemple, la tâche de boucle de multitraitement est exécutée séquentiellement avant d'être convertie en une tâche de boucle for parallèle. Vous pouvez parcourir des séquences telles qu'une collection ou une chaîne dans l'ordre dans lequel elles se produisent à l'aide des boucles for.
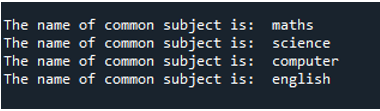
Maintenant, commençons à implémenter le code. Tout d'abord, nous importons 'sommeil' du module de temps. En utilisant la procédure 'sleep()' dans le module time, vous pouvez suspendre l'exécution du thread appelant aussi longtemps que vous le souhaitez. Ensuite, nous utilisons 'random' du module random, définissons une fonction avec le nom 'func', et passons le mot-clé 'argu'. Ensuite, nous créons une valeur aléatoire en utilisant 'val' et la définissons sur 'random'. Ensuite, nous bloquons pendant une petite période en utilisant la méthode 'sleep ()' et passons 'val' en paramètre. Ensuite, pour transmettre un message, nous exécutons la méthode 'print()', en passant les mots 'ready' et le mot-clé 'arg' en paramètre, ainsi que 'created' et en passant la valeur en utilisant 'val'.
Enfin, nous utilisons 'flush' et le réglons sur 'True'. L'utilisateur peut décider de tamponner ou non la sortie à l'aide de l'option flush dans la fonction d'impression de Python. La valeur par défaut de ce paramètre, False, indique que la sortie ne sera pas mise en mémoire tampon. La sortie s'affiche sous la forme d'une série de lignes se succédant si vous la définissez sur true. Ensuite, nous utilisons le 'if name== main' pour sécuriser les points d'entrée. Ensuite, nous exécutons le travail de manière séquentielle. Ici, nous définissons la plage sur '10', ce qui signifie que la boucle se termine après 10 itérations. Ensuite, nous appelons la fonction 'print()', lui transmettons l'instruction d'entrée 'ready' et utilisons l'option 'flush=True'.
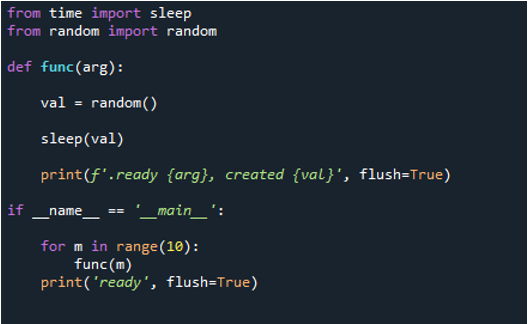
Vous pouvez maintenant voir que lorsque nous exécutons le code, la boucle entraîne l'exécution de la fonction '10' fois. Il itère 10 fois, en commençant à l'index zéro et en terminant à l'index neuf. Chaque message contient un numéro de tâche qui est un numéro de fonction que nous transmettons en tant qu''arg' et un numéro de création.
Cette boucle séquentielle est maintenant transformée en une boucle for parallèle multitraitement. Nous utilisons le même code, mais nous allons vers des bibliothèques et des fonctions supplémentaires pour le multitraitement. Par conséquent, nous devons importer le processus du multitraitement, comme nous l'avons expliqué précédemment. Ensuite, nous créons une fonction appelée « func » et passons le mot-clé « arg » avant d'utiliser « val=random » pour obtenir un nombre aléatoire.
Ensuite, après avoir appelé la méthode 'print ()' pour afficher un message et donné le paramètre 'val' pour retarder un peu la période, nous utilisons la fonction 'if name = main' pour sécuriser les points d'entrée. Sur quoi, nous créons un processus et appelons la fonction dans le processus en utilisant 'process' et passons le 'target = func'. Ensuite, on passe le « func », « arg », on passe la valeur « m », et on passe la plage « 10 » ce qui signifie que la boucle termine la fonction après « 10 » itérations. Ensuite, nous démarrons le processus en utilisant la méthode 'start ()' avec 'process'. Ensuite, nous appelons la méthode 'join()' pour attendre l'exécution du processus et terminer tout le processus après.
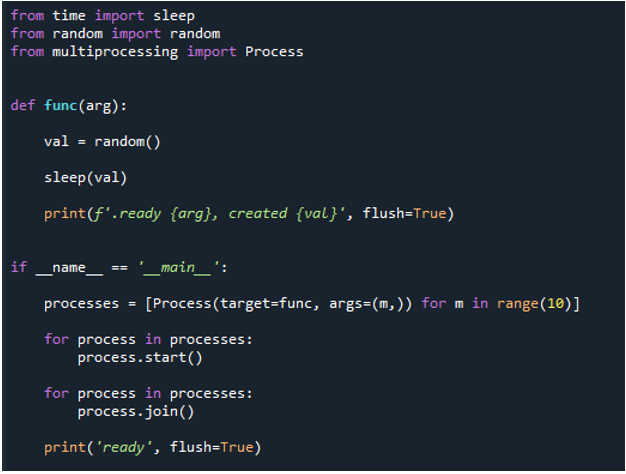
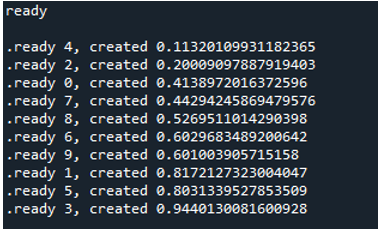
Par conséquent, lorsque nous exécutons le code, les fonctions appellent le processus principal et commencent leur exécution. Ils sont cependant effectués jusqu'à ce que toutes les tâches soient accomplies. Nous pouvons le voir parce que chaque tâche est effectuée simultanément. Il rapporte son message dès qu'il est terminé. Cela signifie que bien que les messages soient dans le désordre, la boucle se termine une fois que les '10' itérations sont terminées.
Conclusion
Nous avons couvert la boucle for de multitraitement Python dans cet article. Nous avons également présenté deux illustrations. La première illustration montre comment utiliser une boucle for dans la bibliothèque de multitraitement de boucles de Python. Et la deuxième illustration montre comment transformer une boucle for séquentielle en une boucle for multitraitement parallèle. Avant de construire le script pour le multitraitement Python, nous devons importer le module de multitraitement.