5.1 Introduction
Le système d'exploitation de l'ordinateur Commodore-64 est fourni avec l'ordinateur en mémoire morte (ROM). Le nombre d'emplacements d'octets de mémoire pour le Commodore-64 varie de 0000 $ à FFFF (c'est-à-dire de 000016 à FFFF16, soit 010 à 65,53510). Le système d'exploitation va de 000 $E à FFFF (soit 57,34410 à 65,53610).
Pourquoi étudier le système d'exploitation Commodore-64
Pourquoi étudier le système d'exploitation Commodore-64 aujourd'hui alors qu'il s'agissait d'un système d'exploitation d'ordinateur sorti en 1982 ? Eh bien, l'ordinateur Commodore-64 utilise l'unité centrale de traitement 6510 qui est une mise à niveau (mais pas une grosse mise à niveau) du 6502 µP.
Le 6 502 µP est encore produit aujourd’hui en grande quantité ; il ne s'agit plus des ordinateurs domestiques ou de bureau mais des appareils (appareils) électriques et électroniques. Le 6502 µP est également simple à comprendre et à utiliser par rapport aux autres microprocesseurs de son époque. En conséquence, il s’agit de l’un des meilleurs microprocesseurs (sinon le meilleur) à utiliser pour enseigner le langage assembleur.
Le 65C02 µP, toujours de la classe des microprocesseurs 6502, possède 66 instructions en langage assembleur, qui peuvent toutes être apprises même par cœur. Les microprocesseurs modernes comportent de nombreuses instructions en langage assembleur et ne peuvent pas être appris par cœur. Chaque µP possède son propre langage assembleur. Tout système d'exploitation, qu'il soit nouveau ou ancien, est en langage assembleur. Avec cela, le langage assembleur 6502 est idéal pour enseigner le système d’exploitation aux débutants. Après avoir appris un système d'exploitation, tel que celui du Commodore-64, un système d'exploitation moderne peut facilement être appris en l'utilisant comme base.
Ce n'est pas seulement l'opinion de l'auteur (moi-même). C'est une tendance croissante dans le monde. De plus en plus d'articles sont écrits sur Internet pour améliorer le système d'exploitation Commodore-64 afin de le faire ressembler à un système d'exploitation moderne. Les systèmes d'exploitation modernes sont expliqués dans le chapitre suivant le suivant.
Note : Le système d'exploitation Commodore-64 (Kernal) fonctionne toujours bien avec les périphériques d'entrée et de sortie modernes (pas tous).
Ordinateur huit bits
Dans un micro-ordinateur à huit bits tel que le Commodore 64, les informations sont stockées, transférées et manipulées sous forme de codes binaires à huit bits.
Carte mémoire
Une carte mémoire est une échelle qui divise la plage complète de mémoire en plages plus petites de différentes tailles et montre ce qui (sous-programme et/ou variable) appartient à quelle plage. Une variable est une étiquette qui correspond à une adresse mémoire particulière qui a une valeur. Les étiquettes sont également utilisées pour identifier le début des sous-programmes. Mais dans ce cas, ils sont appelés noms de sous-programmes. Un sous-programme peut simplement être appelé routine.
La carte mémoire (disposition) du chapitre précédent n'est pas suffisamment détaillée. C'est assez simple. La carte mémoire de l'ordinateur Commodore-64 peut être affichée avec trois niveaux de détails. Lorsqu'il est affiché au niveau intermédiaire, l'ordinateur Commodore-64 possède différentes cartes mémoire. La carte mémoire par défaut de l'ordinateur Commodore-64 au niveau intermédiaire est :

Fig. 5.11 Carte mémoire du Commodore-64
À cette époque, il existait un langage informatique populaire appelé BASIC. De nombreux utilisateurs d'ordinateurs devaient connaître certaines commandes minimales du langage BASIC, telles que charger un programme de la disquette (disque) vers la mémoire, exécuter (exécuter) un programme dans la mémoire et quitter (fermer) un programme. Lorsque le programme BASIC est en cours d'exécution, l'utilisateur doit saisir les données ligne par ligne. Ce n'est pas comme aujourd'hui où une application (un certain nombre de programmes forment une application) est écrite dans un langage de haut niveau avec Windows et où l'utilisateur n'a qu'à insérer les différentes données à des endroits spécialisés dans une fenêtre. Dans certains cas, utilisez une souris pour sélectionner les données précommandées. BASIC était à cette époque un langage de haut niveau, mais il est assez proche du langage assembleur.
Notez que la majeure partie de la mémoire est occupée par BASIC dans la carte mémoire par défaut. BASIC contient des commandes (instructions) qui sont exécutées par ce que l'on appelle l'interpréteur BASIC. En fait, l'interpréteur BASIC est en ROM depuis l'emplacement $A000 jusqu'à $BFFF (inclus) qui est censé être une zone RAM. Cela fait 8 Ko, c'est assez gros à l'époque ! Il se trouve en fait dans la ROM à cet endroit de toute la mémoire. Il a la même taille que le système d'exploitation, de 000 $E à FFFF (inclus). Les programmes écrits en BASIC sont également compris entre 0200 $ et BFFF $.
La RAM du programme en langage assembleur utilisateur est comprise entre 000 $ C et CFFF, soit seulement 4 Ko sur 64 Ko. Alors, pourquoi utilisons-nous ou apprenons-nous le langage assembleur ? Les nouveaux et anciens systèmes d'exploitation sont des langages d'assemblage. Le système d'exploitation du Commodore-64 est en ROM, de 000 $E à FFFF. Il est écrit dans le langage assembleur 65C02 µP (6510 µP). Il se compose de sous-programmes. Le programme utilisateur en langage assembleur doit appeler ces sous-programmes afin d'interagir avec les périphériques (périphériques d'entrée et de sortie). Comprendre le système d'exploitation Commodore-64 en langage assembleur permet à l'étudiant de comprendre les systèmes d'exploitation rapidement, de manière beaucoup moins fastidieuse. Encore une fois, à cette époque, de nombreux programmes utilisateur pour Commodore-64 étaient écrits en BASIC et non en langage assembleur. À cette époque, les langages d'assemblage étaient davantage utilisés par les programmeurs eux-mêmes à des fins techniques.
Le Kernal, orthographié K-e-r-n-a-l, est le système d'exploitation du Commodore-64. Il est livré avec l'ordinateur Commodore-64 en ROM et non sur disque (ou disquette). Le Kernal est constitué de sous-programmes. Pour accéder aux périphériques, le programme utilisateur en langage assembleur (langage machine) doit utiliser ces sous-programmes. Le Kernal ne doit pas être confondu avec le noyau qui s'écrit K-e-r-n-e-l des systèmes d'exploitation modernes, bien qu'il s'agisse presque de la même chose.
La zone mémoire de 4 Ko10 de $C000 (49,15210) à $CFFF (6324810) de la mémoire est soit RAM, soit ROM. Lorsqu’il s’agit de RAM, elle sert à accéder aux périphériques. Lorsqu'il s'agit de ROM, elle sert à imprimer les caractères sur l'écran (moniteur). Cela signifie que soit les caractères sont imprimés sur l'écran, soit les périphériques sont accessibles via l'utilisation de cette partie de la mémoire. Il existe une banque de ROM (ROM de caractères) dans l'unité système (carte mère) qui est commutée dans et hors de tout l'espace mémoire pour y parvenir. L'utilisateur peut ne pas remarquer le changement.
La zone de mémoire de 0100 $ (256 dix ) à 01FF$ (511 dix ) est la pile. Il est utilisé à la fois par le système d'exploitation et par les programmes utilisateur. Le rôle de la pile a été expliqué dans le chapitre précédent de ce cours de carrière en ligne. La zone de mémoire de 0000 $ (0 dix ) à 00FF$ (255 dix ) est utilisé par le système d'exploitation. De nombreux pointeurs y sont attribués.
Table de saut de noyau
Kernal possède des routines appelées par le programme utilisateur. Au fur et à mesure de la sortie de nouvelles versions du système d'exploitation, les adresses de ces routines ont changé. Cela signifie que les programmes utilisateur ne peuvent plus fonctionner avec les nouvelles versions du système d'exploitation. Cela ne s'est pas produit car le Commodore-64 fournissait une table de saut. La table de sauts est une liste de 39 entrées. Chaque entrée du tableau possède trois adresses (à l'exception des 6 derniers octets) qui n'ont jamais changé même avec le changement de version du système d'exploitation.
La première adresse d'une entrée possède une instruction JSR. Les deux adresses suivantes sont constituées d'un pointeur de deux octets. Ce pointeur sur deux octets est l'adresse (ou la nouvelle adresse) d'une routine réelle qui se trouve toujours dans la ROM du système d'exploitation. Le contenu du pointeur peut changer avec les nouvelles versions du système d'exploitation, mais les trois adresses de chaque entrée de la table de saut ne changent jamais. Par exemple, considérons les adresses $FF81, $FF82 et $FF83. Ces trois adresses sont destinées à la routine d'initialisation des circuits (registres) de l'écran et du clavier de la carte mère. L'adresse $FF81 contient toujours le code opération (un octet) de JSR. Les adresses $FF82 et $FF83 ont l'ancienne ou la nouvelle adresse du sous-programme (toujours dans la ROM du système d'exploitation) pour effectuer l'initialisation. À une certaine époque, les adresses $FF82 et $FF83 avaient le contenu (adresse) de $FF5B qui pourrait changer avec la prochaine version du système d'exploitation. Cependant, les adresses $FF81, $FF82 et $FF83 de la table de saut ne changent jamais.
Pour chaque entrée de trois adresses, la première adresse avec JSR possède une étiquette (nom). L'étiquette de 81 $ FF est PCINT. PCINT ne change jamais. Ainsi, pour initialiser les registres de l'écran et du clavier, le programmeur peut simplement taper « JSR PCINT » qui fonctionne pour toutes les versions du système d'exploitation Commodore-64. L'emplacement (adresse de début) du sous-programme réel, par exemple $FF5B, peut changer au fil du temps avec différents systèmes d'exploitation. Oui, il y a au moins deux instructions JSR impliquées dans le programme utilisateur qui utilise le système d'exploitation ROM. Dans le programme utilisateur, il existe une instruction JSR qui accède à une entrée de la table de sauts. À l'exception des six dernières adresses de la table de sauts, la première adresse d'une entrée dans la table de sauts possède une instruction JSR. Dans le Kernal, certains sous-programmes peuvent appeler les autres sous-programmes.
La table de saut Kernal commence à partir de 81 $ FF (inclus) et monte par groupes de trois, à l'exception des six derniers octets qui sont trois pointeurs avec des adresses d'octets inférieures : $FFFA, $FFFC et $FFFE. Toutes les routines ROM OS sont des codes réutilisables. Ainsi, l’utilisateur n’a pas besoin de les réécrire.
Schéma fonctionnel de l'unité système Commodore-64
Le schéma suivant est plus détaillé que celui du chapitre précédent :
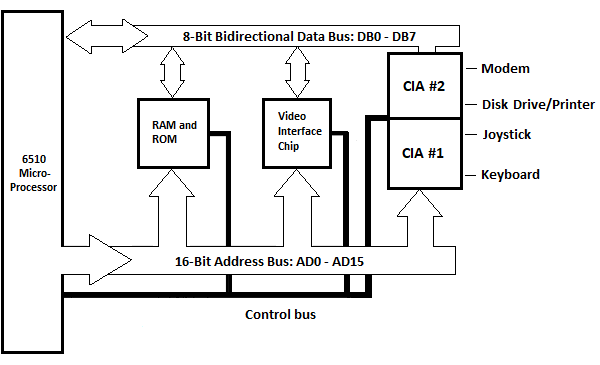
Fig. 5.12 Schéma fonctionnel de l'unité système Commodore_64
La ROM et la RAM sont affichées ici comme un seul bloc. La puce d'interface vidéo (IC) permettant de gérer les informations à l'écran, qui n'a pas été présentée dans le chapitre précédent, est présentée ici. Le bloc unique pour les périphériques d'entrée/sortie, présenté dans le chapitre précédent, est représenté ici sous forme de deux blocs : CIA #1 et CIA #2. CIA signifie Complex Interface Adapter. Chacun dispose de deux ports parallèles de huit bits (à ne pas confondre avec les ports externes sur une surface verticale de l'unité centrale) appelés port A et port B. Les CIA sont connectés à cinq périphériques externes dans cette situation. Les périphériques sont le clavier, le joystick, le lecteur de disque/imprimante et un modem. L'imprimante est connectée à l'arrière du lecteur de disque. Il existe également un circuit de dispositif d'interface sonore et un circuit de réseau logique programmable qui ne sont pas représentés.
Néanmoins, il existe une ROM de personnage qui peut être échangée avec les deux CIA lorsqu'un personnage est envoyé à l'écran et qu'il n'est pas affiché dans le schéma fonctionnel.
Les adresses RAM de $D000 à $DFFF pour les circuits d'entrée/sortie en l'absence de ROM de caractères ont la carte mémoire détaillée suivante :
| Tableau 5.11 Carte mémoire détaillée de $D000 à $DFFF |
||
|---|---|---|
| Plage de sous-adresse | Circuit | Taille (octets) |
| D000 – D3FF | VIC (Contrôleur d'interface vidéo (puce)) | 1K |
| D400 – D7FF | SID (circuit sonore) | 1K |
| D800 – DBFF | RAM couleur | 1 000 amuse-gueules |
| DC00 – DCFF | CIA #1 (Clavier, Joystick) | 256 |
| DD00 – DDFF | CIA #2 (bus série, port utilisateur/RS-232) | 256 |
| DE00 – DEF | Ouvrir l'emplacement d'E/S n°1 | 256 |
| DF00 – DFFF | Ouvrir l'emplacement d'E/S n°2 | 256 |
5.2 Les deux adaptateurs d'interface complexes
Il existe deux circuits intégrés (CI) particuliers dans l'unité système Commodore-64, et chacun d'eux est appelé adaptateur d'interface complexe. Ces deux puces servent à interfacer le clavier et d’autres périphériques au microprocesseur. A l'exception du VIC et de l'écran, tous les signaux d'entrée/sortie entre le microprocesseur et les périphériques passent par ces deux CI. Avec le Commodore-64, il n'y a pas de communication directe entre la mémoire et un périphérique. La communication entre la mémoire et tout périphérique passe par l'accumulateur du microprocesseur, parmi lesquels les adaptateurs CIA (IC). Les CI sont appelés CIA #1 et CIA #2. CIA signifie Complex Interface Adapter.
Chaque CIA dispose de 16 registres. À l'exception des registres de minuterie/compteur de la CIA, chaque registre a une largeur de 8 bits et possède une adresse mémoire. Les adresses des registres mémoire pour CIA #1 sont de $DC00 (56320 dix ) à $DC0F (56335 dix ). Les adresses des registres mémoire pour CIA #2 sont de $DD00 (56576 dix ) à $DD0F (56591 dix ). Bien que ces registres ne soient pas dans la mémoire du CI, ils en font partie. Dans la carte mémoire intermédiaire, la zone d'E/S de $D000 à $DFFF comprend les adresses CIA de $DC00 à $DC0F et de $DD00 à $DD0F. La plupart de la zone de mémoire RAM E/S de $D000 à $DFFF peut être échangée avec la banque de mémoire de la ROM de caractères pour les caractères d'écran. C'est pourquoi, lorsque les personnages sont envoyés à l'écran, les périphériques ne peuvent pas fonctionner ; bien que l'utilisateur puisse ne pas le remarquer car l'échange est rapide.
Il existe deux registres dans le CIA #1 appelés Port A et Port B. Leurs adresses sont respectivement $DC00 et $DC01. Il existe également deux registres dans la CIA #2 appelés Port A et Port B. Bien entendu, leurs adresses sont différentes ; ils sont respectivement $DD00 et $DD01.
Le port A ou le port B dans l'une ou l'autre CIA est un port parallèle. Cela signifie qu'il peut envoyer les données au périphérique en huit bits à la fois ou recevoir les données du microprocesseur en huit bits à la fois.
Un registre de direction de données (DDR) est associé au port A ou au port B. Le registre de direction des données pour le port A de la CIA #1 (DDRA1) se trouve à l'emplacement d'octet mémoire de $DC02. Le registre de direction des données pour le port B du CIA #1 (DDRB1) se trouve à l'emplacement d'octet mémoire de $DC03. Le registre de direction des données pour le port A du CIA #2 (DDRA2) se trouve à l'emplacement d'octet mémoire de $DD02. Le registre de direction des données pour le port B du CIA #2 (DDRB2) se trouve à l'emplacement d'octet mémoire de $DD03.
Désormais, chaque bit du port A ou du port B peut être défini par le registre de direction des données correspondant comme étant l'entrée ou la sortie. L'entrée signifie que les informations vont du périphérique au microprocesseur via une CIA. La sortie signifie que les informations vont du microprocesseur au périphérique via une CIA.
Si une cellule d'un port (registre) doit être entrée, le bit correspondant dans le registre de direction des données est 0. Si une cellule d'un port (registre) doit être sortie, le bit correspondant dans le registre de direction des données est 1. Dans la plupart des cas, les 8 bits d'un port sont programmés pour être soit une entrée, soit une sortie. Lorsque l'ordinateur est sous tension, le port A est programmé pour la sortie et le port B est programmé pour l'entrée. Le code suivant fait du port CIA #1 A une sortie et du port CIA #1 B une entrée :
MDL #$FF
STA DDRA1 ; $DC00 est dirigé par $DC02
MDL #00$
STA DDRB1 ; $DC01 est dirigé par $DC03
DDRA1 est l'étiquette (nom de la variable) de l'emplacement de l'octet de mémoire de $DC02, et DDRB1 est l'étiquette (nom de la variable) de l'emplacement de l'octet de mémoire de $DC03. La première instruction charge 11111111 dans l'accumulateur du µP. La deuxième instruction copie cela dans le registre de direction des données du port A du CIA no. 1. La troisième instruction charge 00000000 dans l’accumulateur du µP. La quatrième instruction copie ceci dans le registre de direction des données du port B du CIA no. 1. Ce code se trouve dans l'un des sous-programmes du système d'exploitation qui effectue cette initialisation au démarrage de l'ordinateur.
Chaque CIA dispose d'une ligne de demande de service d'interruption vers le microprocesseur. Celui de la CIA #1 va au IRQ broche du µP. Celui de la CIA #2 va au INM broche du µP. Rappelez-vous que INM est d'une priorité plus élevée que IRQ .
5.3 Programmation en langage d'assemblage de clavier
Il n'y a que trois interruptions possibles pour le Commodore-64 : IRQ , BRK et INM . Le pointeur de la table de saut pour IRQ se trouve aux adresses $FFFE et $FFFF dans la ROM (système d'exploitation) ce qui correspond à un sous-programme encore dans l'OS (ROM). Le pointeur de la table de saut pour BRK se trouve aux adresses $FFFC et $FFFD dans le système d'exploitation, ce qui correspond à un sous-programme toujours dans le système d'exploitation (ROM). Le pointeur de la table de saut pour INM se trouve aux adresses $FFFA et $FFFB dans l'OS ce qui correspond à un sous-programme toujours dans l'OS (ROM). Pour le IRQ , il y a en fait deux sous-programmes. Ainsi, l'interruption logicielle (instruction) BRK possède son propre pointeur de table de sauts. Le pointeur de la table de saut pour IRQ mène au code qui décide si c'est l'interruption matérielle ou l'interruption logicielle qui est engagée. S'il s'agit d'une interruption matérielle, la routine pour IRQ est appelé. S'il s'agit de l'interruption logicielle (BRK), la routine pour BRK est appelée. Dans l'une des versions du système d'exploitation, le sous-programme pour IRQ est à $EA31 et le sous-programme pour BRK est à $FE66. Ces adresses sont inférieures à 81 $ FF, ce ne sont donc pas des entrées de table de saut et elles peuvent changer avec la version du système d'exploitation. Il y a trois routines intéressantes dans ce sujet : celle qui vérifie s'il s'agit d'une touche enfoncée ou d'un BRK, celle qui est à $FE43, et celle qui peut également changer avec la version du système d'exploitation.
L'ordinateur Commodore-64 ressemble à une énorme machine à écrire (vers le haut) sans la section d'impression (tête et papier). Le clavier est connecté au CIA #1. Le CIA #1 scanne automatiquement le clavier tous les 1/60 de seconde sans aucune interférence de programmation, par défaut. Ainsi, tous les 1/60 de seconde, la CIA #1 envoie un IRQ au µP. Il n'y a qu'un seul IRQ pin au µP qui vient uniquement de la CIA #1. La seule broche d'entrée de INM du µP, qui est différent de IRQ , provient uniquement de la CIA #2 (voir l'illustration suivante). BRK est en fait une instruction en langage assembleur codée dans un programme utilisateur.
Ainsi, tous les 1/60 de seconde, le IRQ la routine pointée par $FFFE et $FFFF est appelée. La routine vérifie si une touche est enfoncée ou si l'instruction BRK est rencontrée. Si une touche est enfoncée, la routine permettant de gérer la pression sur la touche est appelée. S'il s'agit d'une instruction BRK, la routine pour gérer BRK est appelée. Si ce n’est ni l’un ni l’autre, rien ne se passe. Ni l'un ni l'autre ne peut se produire, mais la CIA n°1 envoie IRQ au µP tous les 1/60 de seconde.
La file d'attente du clavier, également connue sous le nom de tampon du clavier, est une plage d'emplacements d'octets de RAM allant de 0 277 $ à 0 280 $ inclusivement ; 1010 octets en tout. Il s'agit d'un tampon Premier entré, premier sorti. Cela signifie que le premier personnage arrivé est le premier à partir. Un caractère d'Europe occidentale prend un octet.
Ainsi, même si le programme ne consomme aucun caractère lorsqu'une touche est enfoncée, le code de la touche va dans ce tampon (file d'attente). Le tampon continue d'être rempli jusqu'à ce qu'il y ait dix caractères. Tout caractère pressé après le dixième caractère n’est pas enregistré. Il est ignoré jusqu'à ce qu'au moins un caractère soit extrait (consommé) de la file d'attente. La table de sauts comporte une entrée pour un sous-programme qui transmet le premier caractère de la file d'attente au microprocesseur. Cela signifie qu'il prend le premier caractère qui entre dans la file d'attente et le place dans l'accumulateur du µP. Le sous-programme de table de saut pour ce faire s'appelle GETIN (pour Get-In). Le premier octet de l'entrée de trois octets dans la table de sauts est étiqueté GETIN (adresse $FFE4). Les deux octets suivants sont le pointeur (adresse) qui pointe vers la routine réelle dans la ROM (OS). Il est de la responsabilité du programmeur d’appeler cette routine. Sinon, le tampon du clavier restera plein et toutes les touches récemment enfoncées seront ignorées. La valeur qui entre dans l'accumulateur est la valeur ASCII de clé correspondante.
Comment les codes clés entrent-ils dans la file d’attente en premier lieu ? Il existe une routine de table de saut appelée SCNKEY (pour scan key). Cette routine peut être appelée à la fois par logiciel et par matériel. Dans ce cas, il est appelé par un circuit électronique (physique) dans le microprocesseur lorsque le signal électrique IRQ est faible. La manière exacte dont cela se fait n’est pas abordée dans ce cours de carrière en ligne.
Le code permettant d'obtenir le premier code clé du tampon du clavier dans l'accumulateur A n'est qu'une seule ligne :
MONTEZ
Si le tampon du clavier est vide, 00 $ est placé dans l'accumulateur. N'oubliez pas que le code ASCII pour zéro n'est pas 00 $ ; c'est 30 $. 00 $ signifie Null. Dans un programme, il peut y avoir un moment où le programme doit attendre une pression sur une touche. Le code pour cela est :
ATTENDRE JSR GETIN
CMP #$00
ATTENDRE GRENOUILLE
Dans la première ligne, « WAIT » est une étiquette qui identifie l'adresse RAM dans laquelle l'instruction JSR est placée (saisie). GETIN est également une adresse. C'est l'adresse du premier des trois octets correspondants dans la table de sauts. L'entrée GETIN, ainsi que toutes les entrées de la table de sauts (à l'exception des trois dernières), se composent de trois octets. Le premier octet de l'entrée est l'instruction JSR. Les deux octets suivants sont l'adresse du corps du sous-programme GETIN réel qui est toujours dans la ROM (OS) mais en dessous de la table de sauts. Ainsi, l'entrée indique de passer au sous-programme GETIN. Si la file d'attente du clavier n'est pas vide, GETIN place le code clé ASCII de la file d'attente First-In-First-Out dans l'accumulateur. Si la file d'attente est vide, Null ($00) est mis dans l'accumulateur.
La deuxième instruction compare la valeur de l'accumulateur avec 00 $. S'il vaut 00 $, cela signifie que la file d'attente du clavier est vide, et l'instruction CMP envoie 1 au flag Z du registre d'état du processeur (simplement appelé registre d'état). Si la valeur dans A n'est pas 00 $, l'instruction CMP envoie 0 au drapeau Z du registre d'état.
La troisième instruction qui est « BEQ WAIT » renvoie le programme à la première instruction si l'indicateur Z du registre d'état est 1. Les première, deuxième et troisième instructions sont exécutées de manière répétée dans l'ordre jusqu'à ce qu'une touche du clavier soit enfoncée. . Si aucune touche n’est enfoncée, le cycle se répète indéfiniment. Un segment de code comme celui-ci est normalement écrit avec un segment de code de timing qui quitte la boucle après un certain temps si aucune touche n'est enfoncée (voir la discussion suivante).
Note : Le clavier est le périphérique d'entrée par défaut et l'écran est le périphérique de sortie par défaut.
5.4 Canal, numéro de périphérique et numéro de fichier logique
Les périphériques que ce chapitre utilise pour expliquer le système d'exploitation Commodore-64 sont le clavier, l'écran (moniteur), le lecteur de disque avec disquette, l'imprimante et le modem qui se connecte via l'interface RS-232C. Pour que la communication ait lieu entre ces appareils et l'unité centrale (microprocesseur et mémoire), un canal doit être établi.
Un canal se compose d'un tampon, d'un numéro de périphérique, d'un numéro de fichier logique et éventuellement d'une adresse secondaire. L'explication de ces termes est la suivante :
Un tampon
Notez dans la section précédente que lorsqu'une touche est enfoncée, son code doit être placé dans un emplacement d'octet dans la RAM parmi une série de dix emplacements consécutifs. Cette série de dix emplacements constitue le tampon du clavier. Chaque périphérique d'entrée ou de sortie (périphérique) possède une série d'emplacements consécutifs dans la RAM appelés tampon.
Numéro d'appareil
Avec le Commodore-64, tout périphérique reçoit un numéro d'appareil. Le tableau suivant présente les différents appareils et leurs numéros :
| Tableau 5.41 Numéros d'appareil Commodore 64 et leurs appareils |
|
|---|---|
| Nombre | Appareil |
| 0 | Clavier |
| 1 | Lecteur de bande |
| 2 | Interface RS 232C vers par ex. un modem |
| 3 | Écran |
| 4 | Imprimante n°1 |
| 5 | Imprimante n°2 |
| 6 | Traceur n°1 |
| 7 | Traceur #2 |
| 8 | Disque |
| 9 ¦ ¦ ¦ 30 |
De 8 (inclus) jusqu'à 22 périphériques de stockage supplémentaires |
Il existe deux types de ports pour un ordinateur. Un type est externe, sur la surface verticale de l'unité centrale. L'autre type est interne. Ce port interne est un registre. Le Commodore-64 possède quatre ports internes : le port A et le port B pour CIA 1 et le port A et le port B pour CIA 2. Il existe un port externe pour le Commodore-64, appelé port série. Les appareils portant le numéro 3 vers le haut sont connectés au port série. Ils sont connectés en guirlande (l'un connecté derrière l'autre), chacun étant identifiable par son numéro d'appareil. Les appareils portant le numéro 8 vers le haut sont généralement les périphériques de stockage.
Note : Le périphérique d'entrée par défaut est le clavier avec le numéro de périphérique 0. Le périphérique de sortie par défaut est l'écran avec le numéro de périphérique 3.
Numéro de dossier logique
Un numéro de fichier logique est un numéro attribué à un périphérique (périphérique) dans l'ordre dans lequel il est ouvert pour y accéder. Ils vont de 010 à 255 dix .
Adresse secondaire
Imaginez que deux fichiers (ou plusieurs fichiers) soient ouverts sur le disque. Pour différencier ces deux fichiers, les adresses secondaires sont utilisées. Les adresses secondaires sont des nombres qui varient d'un appareil à l'autre. La signification de 3 comme adresse secondaire pour une imprimante est différente de la signification de 3 comme adresse secondaire pour un lecteur de disque. La signification dépend de fonctionnalités telles que le moment où un fichier est ouvert en lecture ou le moment où un fichier est ouvert en écriture. Les nombres secondaires possibles vont de 0 dix à 15 dix pour chaque appareil. Pour de nombreux appareils, le chiffre 15 est utilisé pour envoyer des commandes.
Note : Le numéro de périphérique est également appelé adresse de périphérique et le numéro secondaire est également appelé adresse secondaire.
Identification d'une cible périphérique
Pour la carte mémoire Commodore par défaut, les adresses mémoire de $0200 à $02FF (page 2) sont utilisées uniquement par le système d'exploitation en ROM (Kernal) et non par le système d'exploitation plus le langage BASIC. Bien que BASIC puisse toujours utiliser les emplacements via le système d'exploitation ROM.
Le modem et l'imprimante sont deux cibles périphériques différentes. Si deux fichiers sont ouverts depuis le disque, ce sont deux cibles différentes. Avec la carte mémoire par défaut, il existe trois tables (listes) consécutives qui peuvent être considérées comme une seule grande table. Ces trois tableaux contiennent la relation entre les numéros de fichiers logiques, les numéros de périphérique et les adresses secondaires. Avec cela, un canal spécifique ou une cible d'entrée/sortie devient identifiable. Les trois tables sont appelées tables de fichiers. Les adresses RAM et ce qu'elles ont sont :
$0259 — $0262 : Tableau avec étiquette, LAT, contenant jusqu'à dix numéros de fichiers logiques actifs.
$0263 — $026C : Tableau avec étiquette, FAT, contenant jusqu'à dix numéros d'appareil correspondants.
$026D — $0276 : Table avec étiquette, SAT, de dix adresses secondaires correspondantes.
Ici, « - » signifie « à » et un nombre prend un octet.
Le lecteur peut se demander : « Pourquoi le tampon de chaque périphérique n'est-il pas inclus dans l'identification d'un canal ? » Eh bien, la réponse est qu'avec le Commodore-64, chaque périphérique externe (périphérique) possède une série fixe d'octets dans la RAM (carte mémoire). Sans aucun canal ouvert, leurs positions sont toujours présentes dans la mémoire. Le tampon du clavier, par exemple, est fixé entre 0 277 $ et 0 280 $ (inclus) pour la carte mémoire par défaut.
Les sous-programmes Kernal SETLFS et SETNAM
SETLFS et SETNAM sont des routines Kernal. Un canal peut être considéré comme un fichier logique. Pour qu'un canal soit ouvert, le numéro de fichier logique, le numéro de périphérique et une adresse secondaire facultative doivent être produits. Un nom de fichier facultatif (texte) peut également être nécessaire. La routine SETLFS configure le numéro de fichier logique, le numéro de périphérique et une adresse secondaire facultative. Ces chiffres sont mis dans leurs tableaux respectifs. La routine SETNAM définit un nom de chaîne pour le fichier qui peut être obligatoire pour un canal et facultatif pour un autre canal. Il s'agit d'un pointeur (adresse sur deux octets) dans la mémoire. Le pointeur pointe vers le début de la chaîne (nom) qui peut se trouver à un autre endroit de la mémoire. Le nom de la chaîne commence par un octet ayant la longueur de la chaîne, suivi du texte (nom). Le nom fait au maximum seize octets (longs).
Pour appeler la routine SETLFS, le programme utilisateur doit sauter (JSR) à l'adresse $FFBA de la table de saut du système d'exploitation en ROM pour la carte mémoire par défaut. N'oubliez pas qu'à l'exception des six derniers octets de la table de sauts, chaque entrée se compose de trois octets. Le premier octet est l'instruction JSR, qui passe ensuite au sous-programme, commençant à l'adresse des deux octets suivants. Pour appeler la routine SETNAM, le programme utilisateur doit sauter (JSR) à l'adresse $FFBD de la table de saut de l'OS en ROM. L'utilisation de ces deux routines est présentée dans la discussion suivante.
5.5 Ouverture d'un canal, ouverture d'un fichier logique, fermeture d'un fichier logique et fermeture de tous les canaux d'E/S
Un canal se compose d'une mémoire tampon, d'un numéro de fichier logique, d'un numéro de périphérique (adresse de périphérique) et d'une adresse secondaire facultative (un numéro). Un fichier logique (une abstraction) identifié par un numéro de fichier logique peut faire référence à un périphérique tel qu'une imprimante, un modem, un lecteur de disque, etc. Chacun de ces différents périphériques doit avoir des numéros de fichier logique différents. Il existe de nombreux fichiers sur le disque. Un fichier logique peut également faire référence à un fichier particulier du disque. Ce fichier particulier possède également un numéro de fichier logique différent de celui des périphériques tels que l'imprimante ou le modem. Le numéro de fichier logique est donné par le programmeur. Il peut s'agir de n'importe quel nombre compris entre 010 ($00) et 25510 ($FF).
La routine du système d'exploitation SETLFS
La routine OS SETLFS à laquelle on accède en sautant (JSR) vers la table de saut OS ROM à $FFBA configure le canal. Il doit mettre le numéro de fichier logique dans la table de fichiers qui est LAT ($0259 — $0262). Il doit mettre le numéro de périphérique correspondant dans la table de fichiers qui est FAT ($0263 — $026C). Si l'accès au fichier (appareil) nécessite un numéro secondaire, il doit mettre l'adresse secondaire (numéro) correspondante dans la table de fichiers qui est SAT ($026D — $0276).
Pour fonctionner, le sous-programme SETLFS doit obtenir le numéro de fichier logique de l'accumulateur µP ; il doit obtenir le numéro de périphérique à partir du registre µP X. Si le canal le souhaite, il doit obtenir l'adresse secondaire du registre µP Y.
Le numéro de fichier logique est décidé par le programmeur. Les numéros de fichiers logiques qui font référence à différents appareils sont différents. Maintenant, avant d'appeler la routine SETLFS, le programmeur doit mettre le numéro du fichier logique dans l'accumulateur µP. Le numéro de l'appareil est lu à partir d'un tableau (document) comme dans le tableau 5.41. Le programmeur devrait également devoir inscrire le numéro de l'appareil dans le registre µP X. Le fournisseur d'un périphérique tel qu'une imprimante, un lecteur de disque, etc. fournit les adresses secondaires possibles et leur signification pour le périphérique. Si le canal a besoin d'une adresse secondaire, le programmateur doit l'obtenir à partir du document fourni avec l'appareil (périphérique). Si l'adresse secondaire (numéro) est nécessaire, le programmeur doit la mettre dans le registre µP Y avant d'appeler le sous-programme SETLFS. S'il n'est pas nécessaire d'avoir une adresse secondaire, le programmeur doit mettre le numéro $FF dans le registre µP Y avant d'appeler le sous-programme SETLFS.
Le sous-programme SETLFS est appelé sans aucun argument. Ses arguments sont déjà dans les trois registres du 6502 µP. Après avoir mis les numéros appropriés dans les registres, la routine est appelée dans le programme simplement avec ce qui suit sur une ligne séparée :
JSR SETLFS
La routine place les différents nombres de manière appropriée dans leurs tables de fichiers.
La routine OS SETNAM
La routine OS SETNAM est accessible en sautant (JSR) vers la table de saut OS ROM à $FFBD. Toutes les destinations n'ont pas de noms de fichiers. Pour ceux qui ont des destinations (comme les fichiers sur le disque), le nom du fichier doit être configuré. Supposons que le nom du fichier est « mydocum », composé de 7 octets sans les guillemets. Supposons que ce nom se trouve aux emplacements de 101 $ C à 107 $ C (inclus) et que la longueur de 07 $ se trouve à l'emplacement de 100 $ C. L'adresse de début des caractères de la chaîne est $C101. L'octet inférieur de l'adresse de départ est $01 et l'octet supérieur est $C1.
Avant d'appeler la routine SETNAM, le programmeur doit mettre le nombre $07 (longueur de la chaîne) dans l'accumulateur µP. L'octet inférieur de l'adresse de début de chaîne de $01 est placé dans le registre µP X. L'octet supérieur de l'adresse de début de chaîne de $C1 est placé dans le registre µP Y. Le sous-programme est appelé simplement avec ce qui suit :
JSR SETNAM
La routine SETNAM associe les valeurs des trois registres au canal. Les valeurs n'ont pas besoin de rester dans les registres après cela. Si le canal n'a pas besoin d'un nom de fichier, le programmeur doit mettre 00 $ dans l'accumulateur µP. Dans ce cas, les valeurs présentes dans les registres X et Y sont ignorées.
La routine OS OPEN
La routine OS OPEN est accessible en sautant (JSR) vers la table de saut OS ROM à $FFC0. Cette routine utilise le numéro de fichier logique, le numéro de périphérique (et le tampon), une adresse secondaire possible et un nom de fichier possible, pour fournir une connexion entre l'ordinateur Commodore et le fichier dans le périphérique externe ou le périphérique externe lui-même.
Cette routine, comme toutes les autres routines Commodore OS ROM, ne prend aucun argument. Bien qu'il utilise les registres µP, aucun des registres n'a dû être préchargé avec des arguments (valeurs) pour cela. Pour le coder, tapez simplement ce qui suit après l'appel de SETLFS et SETNAM :
JSR OUVERT
Des erreurs peuvent survenir avec la routine OPEN. Par exemple, le fichier peut ne pas être trouvé en lecture. Lorsqu'une erreur se produit, la routine échoue et place le numéro d'erreur correspondant dans l'accumulateur µP, et définit l'indicateur de retenue (à 1) du registre d'état µP. Le tableau suivant fournit les numéros d'erreur et leur signification :
| Tableau 5.51 Numéros d'erreur du noyau et leurs significations pour la routine OS ROM OPEN |
||
|---|---|---|
| Numéro d'erreur | Description | Exemple |
| 1 | TROP DE FICHIERS | OUVERT lorsque dix fichiers sont déjà ouverts |
| 2 | FICHIER OUVERT | OUVERT 1,3 : OUVERT 1,4 |
| 3 | FICHIER NON OUVERT | IMPRIMER#5 sans OUVRIR |
| 4 | FICHIER INTROUVABLE | CHARGEMENT « NONEXISTENF »,8 |
| 5 | APPAREIL NON PRÉSENT | OUVERT 11,11 : IMPRIMER#11 |
| 6 | PAS DE FICHIER D'ENTRÉE | OUVRIR « SEQ,S,W » : GET#8,X$ |
| 7 | PAS DE FICHIER DE SORTIE | OUVERT 1,0 : IMPRIMER#1 |
| 8 | NOM DE FICHIER MANQUANT | CHARGEMENT '',8 |
| 9 | APPAREIL ILLÉGAL NO. | CHARGER « PROGRAMME »,3 |
Ce tableau est présenté d'une manière que le lecteur est susceptible de voir dans de nombreux autres endroits.
La routine OS CHKIN
La routine OS CHKIN est accessible en sautant (JSR) vers la table de saut OS ROM à $FFC6. Après avoir ouvert un fichier (fichier logique), il faut décider si l'ouverture est en entrée ou en sortie. La routine CHKIN fait de l'ouverture un canal d'entrée. Cette routine doit lire le numéro de fichier logique à partir du registre µP X. Le programmeur doit donc mettre le numéro de fichier logique dans le registre X avant d'appeler cette routine. On l'appelle simplement ainsi :
JSR CHKIN
La routine OS CHKOUT
La routine OS CHKOUT est accessible en sautant (JSR) vers la table de saut OS ROM à $FFC9. Après avoir ouvert un fichier (fichier logique), il faut décider si l'ouverture est en entrée ou en sortie. La routine CHKOUT fait de l'ouverture un canal de sortie. Cette routine doit lire le numéro de fichier logique à partir du registre µP X. Le programmeur doit donc mettre le numéro de fichier logique dans le registre X avant d'appeler cette routine. On l'appelle simplement ainsi :
JSR CHKOUT
La routine OS CLOSE
La routine OS CLOSE est accessible en sautant (JSR) vers la table de saut OS ROM à $FFC3. Une fois qu'un fichier logique est ouvert et que les octets sont transmis, le fichier logique doit être fermé. La fermeture du fichier logique libère le tampon de l'unité système pour qu'il soit utilisé par un autre fichier logique qui doit encore être ouvert. Les paramètres correspondants dans les trois tables de fichiers sont également supprimés. L'emplacement RAM pour le nombre de fichiers ouverts est décrémenté de 1.
Lorsque l'ordinateur est mis sous tension, le matériel du microprocesseur et des autres puces principales (circuits intégrés) de la carte mère est réinitialisé. Ceci est suivi par l'initialisation de certains emplacements de mémoire RAM et de certains registres dans certaines puces de la carte mère. Dans le processus d'initialisation, l'emplacement mémoire d'octets de l'adresse $0098 dans la page zéro est indiqué avec l'étiquette NFILES ou LDTND, selon la version du système d'exploitation. Pendant que l'ordinateur fonctionne, cet emplacement d'un octet de 8 bits contient le nombre de fichiers logiques ouverts et l'index d'adresse de début des trois tables de fichiers consécutives. Autrement dit, cet octet possède le nombre de fichiers ouverts qui est décrémenté de 1 lorsque le fichier logique est fermé. Lorsque le fichier logique est fermé, l'accès au périphérique terminal (de destination) ou au fichier réel sur le disque n'est plus possible.
Afin de fermer un fichier logique, le programmeur doit mettre le numéro de fichier logique dans l'accumulateur µP. Il s'agit du même numéro de fichier logique que celui utilisé lors de l'ouverture du fichier. La routine CLOSE en a besoin pour fermer ce fichier particulier. Comme les autres routines du système d'exploitation ROM, la routine CLOSE ne prend pas d'argument, bien que la valeur utilisée à partir de l'accumulateur soit en quelque sorte un argument. La ligne d’instructions du langage assembleur est simplement :
FERMETURE JSR
Les sous-programmes (routines) du langage assembleur 6502 personnalisés ou prédéfinis ne prennent pas d'arguments. Cependant, les arguments arrivent de manière informelle en mettant les valeurs que le sous-programme utilisera dans les registres du microprocesseur.
La routine CLRCHN
La routine OS CLRCHN est accessible en sautant (JSR) vers la table de saut OS ROM à $FFCC. CLRCHN signifie CLeaR CANAL. Lorsqu'un fichier logique est fermé, ses paramètres de numéro de fichier logique, de numéro de périphérique et d'éventuelle adresse secondaire sont supprimés. Ainsi, le canal du fichier logique est effacé.
Le manuel indique que la routine OS CLRCHN efface tous les canaux ouverts et restaure les numéros de périphérique par défaut et autres valeurs par défaut. Cela signifie-t-il que le numéro d'appareil d'un périphérique peut être modifié ? Eh bien, pas tout à fait. Lors de l'initialisation du système d'exploitation, l'emplacement de l'octet de l'adresse $0099 est indiqué avec l'étiquette DFLTI pour contenir le numéro de périphérique d'entrée actuel lorsque l'ordinateur fonctionne. Le Commodore-64 ne peut accéder qu'à un seul périphérique à la fois. Lors de l'initialisation du système d'exploitation, l'emplacement de l'octet de l'adresse $009A est indiqué avec l'étiquette DFLTO pour contenir le numéro de périphérique de sortie actuel lorsque l'ordinateur fonctionne.
Lorsque le sous-programme CLRCHN est appelé, il définit la variable DFLTI sur 0 ($00), qui est le numéro de périphérique d'entrée par défaut (clavier). Il définit la variable DFLTO sur 3 ($03), qui est le numéro de périphérique de sortie par défaut (écran). Les autres variables du numéro de périphérique sont également réinitialisées. C'est le sens de la réinitialisation (ou de la restauration) des périphériques d'entrée/sortie à la normale (valeurs par défaut).
Le manuel Commodore-64 indique qu'après l'appel de la routine CLRCHN, les fichiers logiques ouverts restent ouverts et peuvent toujours transmettre les octets (données). Cela signifie que la routine CLRCHN ne supprime pas les entrées correspondantes dans les tables de fichiers. Le nom CLRCHN est plutôt ambigu quant à sa signification.
5.6 Envoi du personnage à l'écran
Le circuit intégré (IC) principal permettant de gérer l'affichage des caractères et des graphiques à l'écran est appelé contrôleur d'interface vidéo (puce) qui est abrégé en VIC dans le Commodore-64 (en fait VIC II pour VIC version 2). Pour qu'une information (valeurs) apparaisse à l'écran, elle doit passer par VIC II avant d'atteindre l'écran.
L'écran se compose de 25 lignes et 40 colonnes de cellules de caractères. Cela fait 40 x 25 = 1000 caractères affichables à l'écran. Le VIC II lit les 1 000 emplacements d'octets consécutifs de la mémoire RAM correspondants pour les caractères. L’ensemble de ces 1 000 emplacements constitue ce que l’on appelle la mémoire d’écran. Ce qui entre dans ces 1000 emplacements, ce sont les codes de caractères. Pour le Commodore-64, les codes de caractères sont différents des codes ASCII.
Un code de caractère n'est pas un modèle de caractère. Il existe également ce que l'on appelle la ROM de caractères. La ROM de caractères se compose de toutes sortes de modèles de caractères, dont certains correspondent aux modèles de caractères du clavier. La ROM des caractères est différente de la mémoire de l'écran. Lorsqu'un caractère doit être affiché sur l'écran, le code du caractère est envoyé à une position parmi les 1000 positions de la mémoire de l'écran. À partir de là, le motif correspondant est sélectionné dans la ROM de caractères qui doit être affichée à l'écran. Le choix du modèle correct dans la ROM de caractères à partir d'un code de caractère est effectué par VIC II (matériel).
De nombreux emplacements mémoire entre $D000 et $DFFF ont deux objectifs : ils sont utilisés pour gérer les opérations d'entrée/sortie autres que l'écran ou utilisés comme ROM de caractères pour l'écran. Deux blocs de mémoire sont concernés. L’un est la RAM et l’autre la ROM pour la ROM de caractères. L'échange des banques pour gérer soit les entrées/sorties, soit les motifs de caractères (ROM de caractères) se fait par logiciel (routine de l'OS en ROM de $F000 à $FFFF).
Note : Le VIC possède des registres qui sont adressés avec des adresses de l'espace mémoire comprises entre $D000 et $DFFF.
La routine CHROUT
La routine OS CHROUT est accessible en sautant (JSR) vers la table de saut OS ROM à $FFD2. Cette routine, lorsqu'elle est appelée, prend l'octet que le programmeur a mis dans l'accumulateur µP et l'imprime sur l'écran où se trouve le curseur. Le segment de code pour imprimer le caractère « E », par exemple, est :
LDA #$05
CHROUT
Le 0516 n'est pas le code ASCII pour « E ». Le Commodore-64 a ses propres codes de caractères pour l'écran où 05 $ signifie « E ». Le numéro #$05 est placé dans la mémoire de l'écran avant que VIC ne l'envoie à l'écran. Ces deux lignes de codage doivent apparaître après la configuration du canal, l'ouverture du fichier logique et l'appel de la routine CHKOUT pour la sortie. Le code complet est :
; Canal de configuration
LDA #40 $ ; numéro de fichier logique
LDX #$03 ; le numéro d'appareil pour l'écran est 03 $
LDY #$FF ; pas d'adresse secondaire
JSR SETLFS ; canal de configuration proprement dit
; pas de SETNAM car l'écran n'a pas besoin de nom
;
; Ouvrir le fichier logique
JSR OUVERT
; Définir le canal pour la sortie
LDX #40 $ ; numéro de fichier logique
JSR CHKOUT
;
; Caractère de sortie à l'écran
LDA #$05
JSR CHROUT
; Fermer le fichier logique
LDA #40$
FERMETURE JSR
L'ouverture doit être fermée avant l'exécution d'un autre programme. Supposons que l'utilisateur de l'ordinateur tape un caractère sur le clavier lorsqu'il est prévu. Le programme suivant imprime un caractère du clavier à l'écran :
; Canal de configuration
LDA #40 $ ; numéro de fichier logique
LDX #$03 ; le numéro d'appareil pour l'écran est 03 $
LDY #$FF ; pas d'adresse secondaire
JSR SETLFS ; canal de configuration proprement dit
; pas de SETNAM car l'écran n'a pas besoin de nom
;
; Ouvrir le fichier logique
JSR OUVERT
; Définir le canal pour la sortie
LDX #40 $ ; numéro de fichier logique
JSR CHKOUT
;
; Saisir un caractère à partir du clavier
ATTENDEZ JSR GETIN ; met 00 $ dans A si la file d'attente du clavier est vide
CMP #$00 ; Si 00 $ est allé à A, alors Z vaut 1 avec la comparaison
BEQ ATTENDRE ; GETIN à nouveau de la file d'attente si 0 est allé à l'accumulateur
BNE PRNSCRN ; aller à PRNSCRN si Z vaut 0, car A n'a plus 00 $
; Caractère de sortie à l'écran
PRNSCRN JSR CHROUT ; envoyer le caractère dans A à l'écran
; Fermer le fichier logique
LDA #40$
FERMETURE JSR
Note : WAIT et PRNSCRN sont les étiquettes qui identifient les adresses. L'octet du clavier qui arrive dans l'accumulateur µP est un code ASCII. Le code correspondant qui sera envoyé à l'écran par le Commodore-64 doit être différent. Ceci n'est pas pris en compte dans le programme précédent par souci de simplicité.
5.7 Envoi et réception d'octets pour le lecteur de disque
Il existe deux adaptateurs d'interface complexe dans l'unité centrale (carte mère) du Commodore-64 appelés VIA #1 et CIA #2. Chaque CIA dispose de deux ports parallèles appelés port A et port B. Il y a un port externe sur la surface verticale à l'arrière de l'unité système Commodore-64 qui est appelé port série. Ce port possède 6 broches, dont une pour les données. Les données entrent ou sortent de l'unité système en série, un bit à la fois.
Huit bits parallèles du port interne A du CIA #2, par exemple, peuvent sortir de l'unité système via le port série externe après avoir été convertis en données série par un registre à décalage dans le CIA. Les données série de huit bits du port série externe peuvent entrer dans le port interne A du CIA #2 après avoir été converties en données parallèles par un registre à décalage dans le CIA.
L'unité centrale Commodore-64 (unité de base) utilise un lecteur de disque externe avec une disquette. Une imprimante peut être connectée à ce lecteur de disque en guirlande (connectant des périphériques en série sous forme de chaîne). Le câble de données du lecteur de disque est connecté au port série externe de l'unité centrale Commodore-64. Cela signifie qu'une imprimante connectée en série est également connectée au même port série. Ces deux appareils sont identifiés par deux numéros d'appareil différents (généralement 8 et 4, respectivement).
L'envoi ou la réception des données pour le lecteur de disque suit la même procédure que celle décrite précédemment. C'est-à-dire:
- Définition du nom du fichier logique (numéro) qui est le même que celui du fichier disque réel à l'aide de la routine SETNAM.
- Ouverture du fichier logique à l'aide de la routine OPEN.
- Décider s'il s'agit d'une entrée ou d'une sortie à l'aide de la routine CHKOUT ou CHKIN.
- Envoi ou réception des données à l'aide de l'instruction STA et/ou LDA.
- Fermeture du fichier logique à l'aide de la routine CLOSE.
Le fichier logique doit être fermé. La fermeture du fichier logique ferme effectivement ce canal particulier. Lors de la configuration du canal pour le lecteur de disque, le numéro de fichier logique est décidé par le programmeur. Il s'agit d'un nombre compris entre 00 $ et $FF (inclus). Il ne doit pas s'agir d'un numéro qui a déjà été choisi pour un autre appareil (ou un fichier réel). Le numéro de périphérique est 8 s'il n'y a qu'un seul lecteur de disque. L'adresse secondaire (numéro) est obtenue à partir du manuel du lecteur de disque. Le programme suivant utilise 2. Le programme écrit la lettre « E » (ASCII) dans un fichier du disque appelé « mydoc.doc ». Ce nom est supposé commencer à l'adresse mémoire $C101. Ainsi, l'octet inférieur de $01 doit être dans le registre X et l'octet supérieur de $C1 doit être dans le registre Y avant que la routine SETNAM ne soit appelée. Le registre A doit également avoir le numéro $09 avant que la routine SETNAM ne soit appelée.
; Canal de configuration
LDA #40 $ ; numéro de fichier logique
LDX #$08 ; numéro de périphérique pour le premier lecteur de disque
LDY #$02 ; adresse secondaire
JSR SETLFS ; canal de configuration proprement dit
;
; Le fichier dans le lecteur de disque a besoin d'un nom (déjà en mémoire)
LDA #$09
LDX #$01
LDY#$C1
JSR SETNAM
; Ouvrir le fichier logique
JSR OUVERT
; Définir le canal pour la sortie
LDX #40 $ ; numéro de fichier logique
JSR CHKOUT ; pour l'écriture
;
; Caractère de sortie sur le disque
LDA #45$
JSR CHROUT
; Fermer le fichier logique
LDA #40$
FERMETURE JSR
Afin de lire un octet du disque dans le registre µP Y, répétez le programme précédent avec les modifications suivantes : Au lieu de « JSR CHKOUT ; pour l'écriture', utilisez 'JSR CHKIN ; à lire'. Remplacez le segment de code par « ; Afficher les caractères sur le disque » avec ce qui suit :
; Caractère d'entrée à partir du disque
JSR CHRIS
La routine OS CHRIN est accessible en sautant (JSR) vers la table de saut OS ROM à $FFCF. Cette routine, lorsqu'elle est appelée, récupère un octet d'un canal déjà configuré comme canal d'entrée et le place dans le registre µP A. La routine GETIN ROM OS peut également être utilisée à la place de CHRIN.
Envoi d'un octet à l'imprimante
L'envoi d'un octet à l'imprimante s'effectue de la même manière que l'envoi d'un octet à un fichier sur le disque.
5.8 La routine OS SAVE
La routine OS SAVE est accessible en sautant (JSR) vers la table de saut OS ROM à $FFD8. La routine OS SAVE dans la ROM enregistre (vide) une section de la mémoire sur le disque en tant que fichier (avec un nom). L'adresse de début de la section dans la mémoire doit être connue. L'adresse de fin de la section doit également être connue. L'octet inférieur de l'adresse de début est placé dans la page zéro de la RAM à l'adresse $002B. L'octet supérieur de l'adresse de départ est placé dans l'emplacement mémoire d'octet suivant à l'adresse $002C. À la page zéro, l'étiquette TXTTAB fait référence à ces deux adresses, bien que TXTTAB désigne en réalité l'adresse $002B. L'octet inférieur de l'adresse de fin est placé dans le registre µP X. L'octet supérieur de l'adresse de fin plus 1 est placé dans le registre µP Y. Le registre µP A prend la valeur de 2 milliards de dollars pour TXTTAB (002 milliards de dollars). Avec cela, la routine SAVE peut être appelée avec ce qui suit :
SAUVEGARDER JSR
La section de la mémoire à sauvegarder peut être un programme en langage assembleur ou un document. Un exemple de document peut être une lettre ou un essai. Pour utiliser la routine de sauvegarde, la procédure suivante doit être suivie :
- Configurez le canal à l’aide de la routine SETLFS.
- Définissez le nom du fichier logique (numéro) qui est le même que celui du fichier disque réel à l'aide de la routine SETNAM.
- Ouvrez le fichier logique à l'aide de la routine OPEN.
- Créez-en un fichier pour la sortie en utilisant CHKOUT.
- Ici se trouve le code de sauvegarde du fichier qui se termine par « JSR SAVE ».
- Fermez le fichier logique à l'aide de la routine CLOSE.
Le programme suivant enregistre un fichier qui commence à partir des emplacements mémoire de $C101 à $C200 :
; Canal de configuration
LDA #40 $ ; numéro de fichier logique
LDX #$08 ; numéro de périphérique pour le premier lecteur de disque
LDY #$02 ; adresse secondaire
JSR SETLFS ; canal de configuration proprement dit
;
; Nom du fichier dans le lecteur de disque (déjà en mémoire à 301 $C)
LDA #$09 ; longueur du nom du fichier
LDX #$01
LDY#$C3
JSR SETNAM
; Ouvrir le fichier logique
JSR OUVERT
; Définir le canal pour la sortie
LDX #40 $ ; numéro de fichier logique
JSR CHKOUT ; pour écrire
;
; Fichier de sortie sur disque
LDA #$01
STA 2 milliards de dollars ; TXTTAB
LDA #$C1
STA $2C
LDX #00$
LDY#$C2
MDL #2 milliards de dollars
SAUVEGARDER JSR
; Fermer le fichier logique
LDA #40$
FERMETURE JSR
Notez qu'il s'agit d'un programme qui enregistre une autre section de la mémoire (pas la section du programme) sur le disque (disquette pour Commodore-64).
5.9 La routine OS LOAD
La routine OS LOAD est accessible en sautant (JSR) vers la table de saut OS ROM à $FFD5. Lorsqu'une section (grande zone) de la mémoire est enregistrée sur le disque, elle est enregistrée avec un en-tête qui a l'adresse de début de la section dans la mémoire. Le sous-programme OS LOAD charge les octets d'un fichier dans la mémoire. Avec cette opération LOAD, la valeur de l'accumulateur doit être 010 ($00). Pour que l'opération LOAD lise l'adresse de début dans l'en-tête du fichier sur le disque et place les octets du fichier dans la RAM à partir de cette adresse, l'adresse secondaire du canal doit être 1 ou 2 (le programme suivant utilise 2). Cette routine renvoie l'adresse plus 1 de l'emplacement RAM le plus élevé chargé. Cela signifie que l'octet de poids faible de la dernière adresse du fichier en RAM plus 1 est mis dans le registre µP X, et l'octet de poids fort de la dernière adresse du fichier en RAM plus 1 est mis dans le registre µP Y.
Si le chargement échoue, le registre µP A contient le numéro d'erreur (éventuellement 4, 5, 8 ou 9). Le drapeau C du registre d'état du microprocesseur est également activé (fait 1). Si le chargement réussit, la dernière valeur du registre A n'est pas importante.
Désormais, dans le chapitre précédent de ce cours de carrière en ligne, la première instruction du programme en langage assembleur se trouve à l'adresse dans la RAM à laquelle le programme a démarré. Il n’est pas nécessaire que ce soit comme ça. Cela signifie que la première instruction d'un programme ne doit pas nécessairement se trouver au début du programme dans la RAM. L'instruction de démarrage d'un programme peut se trouver n'importe où dans le fichier de la RAM. Il est conseillé au programmeur d'étiqueter cette instruction de démarrage en langage assembleur avec START. Avec cela, une fois le programme chargé, il est réexécuté (exécuté) avec l'instruction en langage assembleur suivante :
DÉBUT JSR
«JSR START» se trouve dans le programme en langage assembleur qui charge le programme à exécuter. Un langage assembleur qui charge un autre fichier de langage assembleur et exécute le fichier chargé a la procédure de code suivante :
- Définissez le canal à l'aide de la routine SETLFS.
- Définissez le nom du fichier logique (numéro) qui est le même que celui du fichier disque réel à l'aide de la routine SETNAM.
- Ouvrez le fichier logique à l'aide de la routine OPEN.
- Faites-en le fichier à saisir à l'aide du CHKIN.
- Le code de chargement du fichier va ici et se termine par « JSR LOAD ».
- Fermez le fichier logique à l'aide de la routine CLOSE.
Le programme suivant charge un fichier à partir du disque et l'exécute :
; Canal de configuration
LDA #40 $ ; numéro de fichier logique
LDX #$08 ; numéro de périphérique pour le premier lecteur de disque
LDY #$02 ; adresse secondaire
JSR SETLFS ; canal de configuration proprement dit
;
; Nom du fichier dans le lecteur de disque (déjà en mémoire à 301 $C)
LDA #$09 ; longueur du nom du fichier
LDX #$01
LDY #$C3
JSR SETNAM
; Ouvrir le fichier logique
JSR OUVERT
; Définir le canal pour l'entrée
LDX #40 $ ; numéro de fichier logique
JSR CHKIN ; à lire
;
; Fichier d'entrée à partir du disque
MDL #00$
CHARGEMENT JSR
; Fermer le fichier logique
LDA #40$
FERMETURE JSR
; Démarrer le programme chargé
DÉBUT JSR
5.10 Le modem et la norme RS-232
Le modem est un appareil (périphérique) qui convertit les bits de l'ordinateur en signaux audio électriques correspondants à transmettre sur la ligne téléphonique. À la réception, il y a un modem avant un ordinateur récepteur. Ce deuxième modem convertit les signaux audio électriques en bits pour l'ordinateur récepteur.
Un modem doit être connecté à un ordinateur via un port externe (sur la surface verticale de l'ordinateur). La norme RS-232 fait référence à un type particulier de connecteur qui connectait (autrefois) un modem à l'ordinateur. En d’autres termes, de nombreux ordinateurs avaient autrefois un port externe qui était un connecteur RS-232 ou un connecteur compatible RS-232.
L'unité système Commodore-64 (ordinateur) possède un port externe sur sa surface verticale arrière appelé port utilisateur. Ce port utilisateur est compatible RS-232. Un périphérique modem peut y être connecté. Le Commodore-64 communique avec un modem via ce port utilisateur. Le système d'exploitation ROM du Commodore-64 dispose de sous-programmes pour communiquer avec un modem appelés routines RS-232. Ces routines ont des entrées dans la table de sauts.
Débit en bauds
L'octet de huit bits provenant de l'ordinateur est converti en une série de huit bits avant d'être envoyé au modem. L'inverse se fait du modem vers l'ordinateur. Le débit en bauds est le nombre de bits transmis par seconde, en série.
Fond de mémoire
Le terme « bas de la mémoire » ne fait pas référence à l'emplacement de l'octet de mémoire de l'adresse $0000. Il fait référence à l'emplacement RAM le plus bas où l'utilisateur peut commencer à placer ses données et ses programmes. Par défaut, il s'agit de 0 800 $. Rappelez-vous de la discussion précédente qu'un grand nombre d'emplacements entre $0800 et $BFFF sont utilisés par le langage informatique BASIC et ses programmeurs (utilisateurs). Seuls les emplacements d'adresse $C000 à $CFFF sont réservés aux programmes et aux données en langage assembleur ; cela représente 4 Ko sur les 64 Ko de la mémoire.
Haut de la mémoire
À l'époque, lorsque les clients achetaient les ordinateurs Commodore-64, certains n'étaient pas livrés avec tous les emplacements de mémoire. Ces ordinateurs avaient une ROM avec leur système d'exploitation allant de 000 $ E à FFFF. Ils avaient de la RAM de 0000 $ à une limite, qui n'est pas DFFF $, à côté de 000 $ E. La limite était inférieure à $DFFF et cette limite est appelée « Haut de la mémoire ». Ainsi, le haut de la mémoire ne fait pas référence à l'emplacement $FFFF.
Tampons Commodore-64 pour la communication RS-232
Tampon de transmission
Le tampon pour la transmission RS-232 (sortie) occupe 256 octets du haut de la mémoire vers le bas. Le pointeur de ce tampon de transmission est étiqueté ROBUF. Ce pointeur se trouve à la page zéro avec les adresses $00F9 suivies de $00FA. ROBUF identifie en fait $00F9. Ainsi, si l'adresse de début du tampon est $BE00, l'octet inférieur de $BE00, qui est $00, se trouve à l'emplacement $00F9 et l'octet supérieur de $BE00, qui est $BE, est à l'emplacement $00FA. emplacement.
Tampon de réception
Le tampon pour recevoir les octets RS-232 (entrée) prend 256 octets à partir du bas du tampon de transmission. Le pointeur de ce tampon de réception est étiqueté RIBUF. Ce pointeur se trouve à la page zéro avec les adresses $00F7 suivies de $00F8. RIBUF identifie en fait $00F7. Ainsi, si l'adresse de début du tampon est $BF00, l'octet inférieur de $BF00, qui est $00, se trouve à l'emplacement $00F7 et l'octet supérieur de $BF00, qui est $BF, est à l'emplacement $00F8. emplacement. Ainsi, 512 octets du haut de la mémoire sont utilisés comme tampon RAM RS-232 total.
Canal RS-232
Lorsqu'un modem est connecté au port utilisateur (externe), la communication avec le modem est uniquement une communication RS-232. La procédure pour avoir un canal RS-232 complet est presque la même que dans la discussion précédente, mais avec une différence importante : le nom du fichier est un code et non une chaîne dans la mémoire. Le code $0610 est un bon choix. Cela signifie un débit en bauds de 300 bits/sec et quelques autres paramètres techniques. De plus, il n’y a pas d’adresse secondaire. Notez que le numéro de périphérique est 2. La procédure pour configurer un canal RS-232 complet est la suivante :
- Définition du canal à l'aide de la routine SETLFS.
- Définition du nom du fichier logique, $0610.
- Ouverture du fichier logique à l'aide de la routine OPEN.
- Ce qui en fait le fichier à sortir à l'aide de CHKOUT ou le fichier à saisir à l'aide de CHKIN.
- Envoi des octets uniques avec CHROUT ou réception des octets uniques avec GETIN.
- Fermeture du fichier logique à l'aide de la routine CLOSE.
La routine OS GETIN est accessible en sautant (JSR) vers la table de saut OS ROM à $FFE4. Cette routine, lorsqu'elle est appelée, prend l'octet qui est envoyé dans le tampon du récepteur et le place (renvoie) dans l'accumulateur µP.
Le programme suivant envoie l'octet « E » (ASCII) au modem connecté au port utilisateur compatible RS-232 :
; Canal de configuration
LDA #40 $ ; numéro de fichier logique
LDX #$02 ; numéro d'appareil pour RS-232
LDY #$FF ; pas d'adresse secondaire
JSR SETLFS ; canal de configuration proprement dit
;
; Le nom du RS-232 est un code, par ex. 0610 $
LDA #$02 ; la longueur du code est de 2 octets
LDX #10$
LDY#$06
JSR SETNAM
;
; Ouvrir le fichier logique
JSR OUVERT
; Définir le canal pour la sortie
LDX #40 $ ; numéro de fichier logique
JSR CHKOUT
;
; Caractères de sortie vers RS-232, par ex. modem
LDA #45$
JSR CHROUT
; Fermer le fichier logique
LDA #40$
FERMETURE JSR
Pour recevoir un octet, le code est très similaire, sauf que « JSR CHKOUT » est remplacé par « JSR CHKIN » et :
LDA #45$
JSR CHROUT
est remplacé par « JSR GETIN » et le résultat est placé dans le registre A.
L'envoi ou la réception continue d'octets se fait respectivement par une boucle pour l'envoi ou la réception de segments de code.
Notez que l'entrée et la sortie avec le Commodore sont similaires dans la plupart des cas, à l'exception du clavier où certaines routines ne sont pas appelées par le programmeur, mais elles sont appelées par le système d'exploitation.
5.11 Comptage et chronométrage
Considérons la séquence de compte à rebours qui est :
2, 1, 0
Il s'agit d'un compte à rebours de 2 à 0. Considérons maintenant la séquence de compte à rebours répétitive :
2, 1, 0, 2, 1, 0, 2, 1, 0, 2, 1, 0
Il s’agit du compte à rebours répété de la même séquence. La séquence est répétée quatre fois. Quatre fois signifie que le timing est 4. Dans une séquence, cela compte. Répéter la même séquence est une question de timing.
Il y a deux adaptateurs d'interface complexe dans l'unité centrale du Commodore-64. Chaque CIA dispose de deux circuits compteur/minuterie nommés Timer A (TA) et Timer B (TB). Le circuit de comptage n'est pas différent du circuit de chronométrage. Le compteur ou minuterie du Commodore-64 fait référence à la même chose. En fait, l’un ou l’autre fait essentiellement référence à un registre de 16 bits qui compte toujours jusqu’à 0 aux impulsions de l’horloge système. Différentes valeurs peuvent être définies dans le registre 16 bits. Plus la valeur est grande, plus le compte à rebours jusqu'à zéro est long. Chaque fois qu'une des minuteries dépasse zéro, le IRQ un signal d'interruption est envoyé au microprocesseur. Lorsque le comptage dépasse zéro, on parle de sous-dépassement.
Selon la façon dont le circuit de minuterie est programmé, une minuterie peut fonctionner en mode ponctuel ou en mode continu. Avec l'illustration précédente, le mode unique signifie « faire 2, 1, 0 » et s'arrêter pendant que les impulsions de l'horloge continuent. Le mode continu ressemble à « 2, 1, 0, 2, 1, 0, 2, 1, 0, 2, 1, 0, etc. » qui continue avec les impulsions d'horloge. Cela signifie que lorsqu'il dépasse zéro, si aucune instruction n'est donnée, la séquence de compte à rebours se répète. Le plus grand nombre est généralement bien supérieur à 2.
Le minuteur A (TA) du CIA #1 génère IRQ à intervalles réguliers (durées) pour entretenir le clavier. En fait, c'est en fait tous les 1/60 de seconde par défaut. IRQ est envoyé au microprocesseur tous les 1/60 de seconde. C'est seulement quand IRQ est envoyé qu'un programme peut lire une valeur de clé dans la file d'attente du clavier (tampon). N'oubliez pas que le microprocesseur n'a qu'une seule broche pour le IRQ signal. Le microprocesseur n'a également qu'une seule broche pour le INM signal. Le signal ¯NMI envoyé au microprocesseur provient toujours du CIA #2.
Le registre temporisateur 16 bits possède deux adresses mémoire : une pour l'octet inférieur et une pour l'octet supérieur. Chaque CIA dispose de deux circuits de minuterie. Les deux CIA sont identiques. Pour CIA #1, les adresses des deux timers sont : DC04 et DC05 pour TA et DC06 et DC07 pour TB. Pour CIA #2, les adresses des deux timers sont : DD04 et DD05 pour TA et DD06 et DD07 pour TB.
Supposons que le nombre 25510 doive être envoyé au temporisateur TA de la CIA #2 pour le compte à rebours. 25510 = 00000000111111112 est sur seize bits. 00000000111111112 = 000FFF est en hexadécimal. Dans ce cas, $FF est envoyé au registre à l'adresse $DD04, et $00 est envoyé au registre à l'adresse $DD05 – petite endianité. Le segment de code suivant envoie le numéro au registre :
MDL #$FF
ETAT $DD04
MDL #00$
ETAT $DD05
Bien que les registres d'une CIA aient des adresses RAM, ils se trouvent physiquement dans la CIA et la CIA est un circuit intégré distinct de la RAM ou de la ROM.
Ce n'est pas tout! Lorsque le minuteur a reçu un numéro pour le compte à rebours, comme avec le code précédent, le compte à rebours ne démarre pas. Le décompte commence lorsqu'un octet de huit bits a été envoyé dans le registre de contrôle correspondant pour la minuterie. Le premier bit de cet octet pour le registre de contrôle indique si le décompte doit démarrer ou non. Une valeur de 0 pour ce premier bit signifie l'arrêt du décompte, tandis qu'une valeur de 1 signifie le démarrage du décompte. De plus, l'octet doit indiquer si le compte à rebours est en mode one shot (ponctuel) ou en mode d'exécution libre (mode continu). Le mode One-Shot compte à rebours et s'arrête lorsque la valeur du registre de minuterie devient zéro. Avec le mode de fonctionnement libre, le compte à rebours se répète après avoir atteint 0. Le quatrième bit (index 3) de l'octet envoyé au registre de contrôle indique le mode : 0 signifie mode de fonctionnement libre et 1 signifie mode one-shot.
Un nombre approprié pour commencer à compter en mode one shot est 000010012 = 09 $ en hexadécimal. Un nombre approprié pour commencer à compter en mode d'exécution libre est 000000012 = 01 $ en hexadécimal. Chaque registre temporisé possède son propre registre de contrôle. Dans CIA #1, le registre de contrôle du temporisateur A a l'adresse RAM de DC0E16 et le registre de contrôle du temporisateur B a l'adresse RAM de DC0F16. Dans CIA #2, le registre de contrôle du temporisateur A a l'adresse RAM de DD0E16 et le registre de contrôle du temporisateur B a l'adresse RAM de DD0F16. Pour commencer le décompte du nombre de seize bits dans TA de CIA #2, en mode one-shot, utilisez le code suivant :
LDA #$09
STA $DD0E
Pour commencer le décompte du nombre de seize bits dans TA de CIA #2, en mode d'exécution libre, utilisez le code suivant :
LDA #$01
STA $DD0E
5.12 Le IRQ et INM Demandes
Le microprocesseur 6502 possède le IRQ et INM lignes (épingles). La CIA #1 et la CIA #2 ont chacune le droit IRQ broche pour le microprocesseur. Le IRQ la broche du CIA #2 est connectée au INM broche du µP. Le IRQ la broche du CIA #1 est connectée au IRQ broche du µP. Ce sont les deux seules lignes d'interruption qui connectent le microprocesseur. Alors le IRQ l'épingle de la CIA #2 est la INM source et peut également être considérée comme la ligne ¯NMI.
La CIA n°1 dispose de cinq sources immédiates possibles pour générer le IRQ signal pour le µP. La CIA #2 a la même structure que la CIA #1. Ainsi, la CIA #2 a cette fois les mêmes cinq sources immédiates possibles pour générer le signal d'interruption, qui est la INM signal. Rappelez-vous que lorsque le µP reçoit le INM signal, s'il gère le IRQ demande, il la suspend et gère le INM demande. Lorsqu'il a fini de gérer le INM demande, il reprend alors le traitement de la IRQ demande.
CIA #1 est normalement connecté en externe au clavier et à un appareil de jeu tel qu'un joystick. Le clavier utilise davantage le port A du CIA #1 que le port B. La console de jeu utilise davantage le port B du CIA #1 que son port A. Le CIA #2 est normalement connecté en externe au lecteur de disque (en série avec l'imprimante). et le modem. Le lecteur de disque utilise davantage le port A du CIA #2 (bien que via le port série externe) que son port B. Le modem (RS-232) utilise davantage le port B du CIA #2 que son port A.
Avec tout cela, comment l'unité centrale sait-elle ce qui cause le IRQ ou INM interrompre? CIA #1 et CIA #2 ont cinq sources immédiates d'interruption. Si le signal d'interruption vers le µP est INM , la source est l'une des cinq sources immédiates de la CIA #2. Si le signal d'interruption vers le µP est IRQ , la source est l'une des cinq sources immédiates de la CIA #1.
La question suivante est : « Comment l’unité système fait-elle la différence entre les cinq sources immédiates de chaque CIA ? » Chaque CIA possède un registre de huit bits appelé registre de contrôle d'interruption (ICR). L'ICR dessert les deux ports de la CIA. Le tableau suivant montre la signification des huit bits du registre de contrôle d'interruption, en commençant par le bit 0 :
| Tableau 5.13 Registre de contrôle des interruptions |
|
|---|---|
| Indice de bits | Signification |
| 0 | Mise à 1 (effectuée 1) par débordement du temporisateur A |
| 1 | Réglé par sous-dépassement du temporisateur B |
| 2 | Régler quand l'horloge de l'heure est égale à l'alarme |
| 3 | Définir lorsque le port série est plein |
| 4 | Défini par un périphérique externe |
| 5 | Non utilisé (fait 0) |
| 6 | Non utilisé (fait 0) |
| 7 | Défini lorsque l'un des cinq premiers bits est défini |
Comme le montre le tableau, chacune des sources immédiates est représentée par l'un des cinq premiers bits. Ainsi, lorsque le signal d'interruption est reçu au µP, le code doit être exécuté pour lire le contenu du registre de contrôle d'interruption afin de connaître la source exacte de l'interruption. L'adresse RAM de l'ICR de la CIA #1 est DC0D16. L'adresse RAM de l'ICR du CIA #2 est DD0D16. Pour lire (retourner) le contenu de l'ICR du CIA #1 vers l'accumulateur µP, tapez l'instruction suivante :
LDA$DC0D
Pour lire (retourner) le contenu de l'ICR du CIA #2 vers l'accumulateur µP, tapez l'instruction suivante :
LDA $DD0D
5.13 Programme en arrière-plan piloté par interruption
Le clavier interrompt normalement le microprocesseur tous les 1/60 de seconde. Imaginez qu'un programme est en cours d'exécution et qu'il atteint une position lui permettant d'attendre une touche du clavier avant de pouvoir continuer avec les segments de code ci-dessous. Supposons que si aucune touche n'est enfoncée sur le clavier, le programme effectue uniquement une petite boucle en attendant une touche. Imaginez que le programme est en cours d'exécution et attend juste une touche du clavier juste après l'émission de l'interruption du clavier. À ce stade, l'ensemble de l'ordinateur s'arrête indirectement et ne fait rien d'autre que la boucle d'attente. Imaginez qu'une touche du clavier soit enfoncée juste avant le prochain numéro de la prochaine interruption clavier. Cela signifie que l’ordinateur n’a rien fait pendant environ un soixantième de seconde ! Cela fait longtemps pour qu'un ordinateur ne fasse rien, même à l'époque du Commodore-64. L'ordinateur aurait pu faire autre chose pendant cette période (durée). Il existe de nombreuses durées de ce type dans un programme.
Un deuxième programme peut être écrit pour fonctionner pendant de telles durées « d'inactivité ». On dit qu'un tel programme fonctionne en arrière-plan du programme principal (ou premier). Un moyen simple de procéder consiste simplement à forcer une gestion modifiée des interruptions BRK lorsqu'une touche est attendue du clavier.
Pointeur pour l’instruction BRK
Aux emplacements consécutifs de la RAM des adresses $0316 et $0317 se trouve le pointeur (vecteur) pour la routine d'instruction BRK réelle. Le pointeur par défaut est placé là lorsque l'ordinateur est allumé par le système d'exploitation en ROM. Ce pointeur par défaut est une adresse qui pointe toujours vers le gestionnaire d'instructions BRK par défaut dans la ROM du système d'exploitation. Le pointeur est une adresse de 16 bits. L'octet inférieur du pointeur est placé à l'emplacement d'octet de l'adresse $0306 et l'octet supérieur du pointeur est placé à l'emplacement d'octet $0317.
Un deuxième programme peut être écrit de telle sorte que lorsque le système est « inactif », certains codes du deuxième programme soient exécutés par le système. Cela signifie que le deuxième programme doit être composé de sous-programmes. Lorsque le système est « inactif » et attend une touche du clavier, un sous-programme suivant pour le deuxième programme est exécuté. L’interaction humaine avec l’ordinateur est lente par rapport au fonctionnement de l’unité centrale.
Il est facile de résoudre ce problème : Chaque fois que l'ordinateur doit attendre une touche du clavier, insérez une instruction BRK dans le code et remplacez le pointeur en $0316 (et $0317) par le pointeur du sous-programme suivant de la seconde ( programme personnalisé). De cette façon, les deux programmes fonctionneraient sur une durée qui n'est pas beaucoup plus longue que celle du programme principal qui s'exécute seul.
5.14 Assemblage et compilation
L'assembleur remplace toutes les étiquettes par des adresses. Un programme en langage assembleur est normalement écrit pour démarrer à une adresse particulière. Le résultat de l'assembleur (après assemblage) est appelé le « code objet » avec tout en binaire. Ce résultat est le fichier exécutable si le fichier est un programme et non un document. Un document n'est pas exécutable.
Une application se compose de plusieurs programmes (en langage assembleur). Il existe généralement un programme principal. La situation ici ne doit pas être confondue avec celle des programmes en arrière-plan pilotés par interruption. Tous les programmes ici sont des programmes de premier plan, mais il existe un premier programme ou programme principal.
Un compilateur est nécessaire à la place de l'assembleur lorsqu'il existe plusieurs programmes de premier plan. Le compilateur assemble chacun des programmes en un code objet. Cependant, il y aurait un problème : certains segments de code se chevaucheraient car les programmes sont probablement écrits par des personnes différentes. La solution du compilateur est de décaler tous les programmes qui se chevauchent sauf le premier sur l'espace mémoire, afin que les programmes ne se chevauchent pas. Désormais, lorsqu'il s'agit de stocker des variables, certaines adresses de variables se chevauchent toujours. La solution ici est de remplacer les adresses qui se chevauchent par les nouvelles adresses (sauf pour le premier programme) afin qu'elles ne se chevauchent plus. De cette manière, les différents programmes s'inséreront dans les différentes portions (zones) de la mémoire.
Avec tout cela, il est possible qu’une routine d’un programme appelle une routine d’un autre programme. Ainsi, le compilateur effectue la liaison. La liaison fait référence au fait d'avoir l'adresse de début d'un sous-programme dans un programme, puis de l'appeler dans un autre programme ; qui font tous deux partie de la demande. Pour cela, les deux programmes doivent utiliser la même adresse. Le résultat final est un gros code objet avec tout en binaire (bits).
5.15 Sauvegarde, chargement et exécution d'un programme
Un langage assembleur est normalement écrit dans un programme éditeur (qui peut être fourni avec le programme assembleur). Le programme éditeur indique où commence et se termine le programme dans la mémoire (RAM). La routine Kernal SAVE de la ROM du système d'exploitation du Commodore-64 peut enregistrer un programme en mémoire sur le disque. Il vide simplement la section (bloc) de la mémoire qui peut contenir son appel d'instruction sur le disque. Il est conseillé d'avoir l'instruction appelante à SAVE, séparée du programme en cours de sauvegarde, de sorte que lorsque le programme est chargé dans la mémoire à partir du disque, il ne se sauvegarde pas à nouveau lors de son exécution. Charger un programme en langage assembleur à partir du disque est un autre type de défi car un programme ne peut pas se charger tout seul.
Un programme ne peut pas se charger depuis le disque jusqu'à l'endroit où il commence et se termine dans la RAM. À l'époque, le Commodore-64 était normalement équipé d'un interprète BASIC pour exécuter les programmes en langage BASIC. Lorsque la machine (ordinateur) est allumée, elle s'installe avec l'invite de commande : PRÊT. À partir de là, les commandes ou instructions BASIC peuvent être saisies en appuyant sur la touche « Entrée » après la saisie. La commande (instruction) BASIC pour charger un fichier est :
CHARGER 'nom de fichier',8,1
La commande commence par le mot réservé BASIC qui est LOAD. Ceci est suivi d'un espace, puis du nom du fichier entre guillemets doubles. Le numéro d'appareil 8 est suivi et précédé d'une virgule. L'adresse secondaire du disque qui est 1 est suivie, précédée d'une virgule. Avec un tel fichier, l'adresse de départ du programme en langage assembleur se trouve dans l'en-tête du fichier sur le disque. Lorsque le BASIC a fini de charger le programme, la dernière adresse RAM plus 1 du programme est renvoyée. Le mot « renvoyé » signifie ici que l'octet inférieur de la dernière adresse plus 1 est placé dans le registre µP X, et l'octet supérieur de la dernière adresse plus 1 est placé dans le registre µP Y.
Après avoir chargé le programme, il doit être exécuté (exécuté). L'utilisateur du programme doit connaître l'adresse de début d'exécution dans la mémoire. Encore une fois, un autre programme BASIC est nécessaire ici. C'est la commande SYS. Après avoir exécuté la commande SYS, le programme en langage assembleur s'exécutera (et s'arrêtera). Pendant l'exécution, si une saisie est nécessaire à partir du clavier, le programme en langage assembleur doit l'indiquer à l'utilisateur. Une fois que l'utilisateur a saisi les données sur le clavier et appuyé sur la touche « Entrée », le programme en langage assembleur continuera à s'exécuter en utilisant la saisie au clavier sans interférence de l'interpréteur BASIC.
En supposant que l'adresse RAM de début d'exécution (en cours d'exécution) du programme en langage assembleur est C12316, C123 est converti en base dix avant de l'utiliser avec la commande SYS. La conversion de C12316 en base dix est la suivante :
Ainsi, la commande BASIC SYS est :
SYS 49443
5.16 Démarrage pour Commodore-64
Le démarrage du Commodore-64 se compose de deux phases : la phase de réinitialisation du matériel et la phase d'initialisation du système d'exploitation. Le système d'exploitation est le Kernal en ROM (et non sur un disque). Il y a une ligne de réinitialisation (en fait RES ) qui se connecte à une broche à 6502 µP, et au même nom de broche dans tous les vaisseaux spéciaux tels que le CIA 1, le CIA 2 et le VIC II. Dans la phase de réinitialisation, grâce à cette ligne, tous les registres du µP et des puces spéciales sont réinitialisés à 0 (mis à zéro pour chaque bit). Ensuite, par le matériel du microprocesseur, le pointeur de pile et le registre d'état du processeur reçoivent leurs valeurs initiales dans le microprocesseur. Le compteur de programme est alors donné avec la valeur (adresse) aux emplacements $FFFC et $FFFD. Rappelons que le compteur de programme contient l'adresse de l'instruction suivante. Le contenu (adresse) conservé ici concerne le sous-programme qui démarre l'initialisation du logiciel. Jusqu'à présent, tout est fait par le matériel du microprocesseur. L'ensemble de la mémoire n'est pas touché à cette phase. La phase suivante d'initialisation commence alors.
L'initialisation est effectuée par certaines routines du système d'exploitation ROM. L'initialisation consiste à donner les valeurs initiales ou par défaut à certains registres dans les puces spéciales. L'initialisation commence en donnant les valeurs initiales ou par défaut à certains registres dans les puces spéciales. IRQ , par exemple, doit commencer à émettre tous les 1/60 de seconde. Ainsi, son timer correspondant dans CIA #1 doit être réglé sur sa valeur par défaut.
Ensuite, le Kernal effectue un test de RAM. Il teste chaque emplacement en envoyant un octet à l'emplacement et en le relisant. S’il y a une différence, au moins cet emplacement est mauvais. Kernal identifie également le haut et le bas de la mémoire et définit les pointeurs correspondants dans la page 2. Si le haut de la mémoire est $DFFF, $FF est placé à l'emplacement $0283 et $DF est placé à l'emplacement d'octet $0284. Les 0283 $ et 0284 $ portent le label HIRAM. Si le bas de la mémoire est 0800 $, 00 $ est placé à l'emplacement 0281 $ et 08 $ est placé à l'emplacement 0282 $. Les 0281 $ et 0282 $ portent le label LORAM. Le test de RAM commence en fait à partir de 0300 $ jusqu'au sommet de la mémoire (RAM).
Enfin, les vecteurs d'entrée/sortie (pointeurs) sont définis sur leurs valeurs par défaut. Le test de RAM commence en fait à partir de 0300 $ jusqu'au sommet de la mémoire (RAM). Cela signifie que la page 0, la page 1 et la page 2 sont initialisées. La page 0, en particulier, contient de nombreux pointeurs OS ROM et la page 2 contient de nombreux pointeurs BASIC. Ces pointeurs sont appelés variables. N'oubliez pas que la page 1 est la pile. Les pointeurs sont appelés variables car ils ont des noms (étiquettes). À ce stade, la mémoire de l'écran (moniteur) est effacée. Cela signifie envoyer le code de 20 $ pour l'espace (qui s'avère être le même que le code ASCII de 20 $) aux 1 000 emplacements de l'écran RAM. Enfin, le Kernal démarre l'interpréteur BASIC pour afficher l'invite de commande BASIC qui est READY en haut du moniteur (écran).
5.17 Problèmes
Il est conseillé au lecteur de résoudre tous les problèmes d'un chapitre avant de passer au chapitre suivant.
- Écrivez un code en langage assembleur qui fait de tous les bits du port CIA #2 A une sortie et du port CIA #2 B une entrée.
- Écrivez un code de langage assembleur 6502 qui attend une touche du clavier jusqu'à ce qu'elle soit enfoncée.
- Écrivez un programme en langage assembleur 6502 qui envoie le caractère «E» à l'écran du Commodore-64.
- Écrivez un programme en langage assembleur 6502 qui prend un caractère du clavier et l'envoie à l'écran du Commodore-64, en ignorant le code clé et le timing.
- Écrivez un programme en langage assembleur 6502 qui reçoit un octet de la disquette Commodore-64.
- Écrivez un programme en langage assembleur 6502 qui enregistre un fichier sur la disquette Commodore-64.
- Écrivez un programme en langage assembleur 6502 qui charge un fichier programme à partir de la disquette Commodore-64 et le démarre.
- Écrivez un programme en langage assembleur 6502 qui envoie l'octet «E» (ASCII) au modem connecté au port utilisateur compatible RS-232 du Commodore-64.
- Expliquez comment le comptage et le chronométrage sont effectués dans l'ordinateur Commodore-64.
- Expliquez comment l'unité système Commodore-64 peut identifier 10 sources différentes de demandes d'interruption immédiate, y compris les demandes d'interruption non masquables.
- Expliquez comment un programme d'arrière-plan peut s'exécuter avec un programme de premier plan sur l'ordinateur Commodore-64.
- Expliquez brièvement comment les programmes en langage assembleur peuvent être compilés en une seule application pour l'ordinateur Commodore-64.
- Expliquez brièvement le processus de démarrage de l'ordinateur Commodore-64.