LangChain est le cadre permettant de créer des modèles de discussion et des LLM pour obtenir des informations à partir de l'ensemble de données ou d'Internet à l'aide de l'environnement OpenAI. L'analyseur de sortie structurée est utilisé pour obtenir plusieurs champs ou réponses comme la réponse réelle et des informations supplémentaires associées. Les bibliothèques d'analyseurs de sortie peuvent être utilisées avec LangChain pour extraire des données à l'aide de modèles construits en tant que LLM ou modèles de discussion.
Cet article a démontré le processus d'utilisation de l'analyseur de sortie structurée dans LangChain.
Comment utiliser l’analyseur de sortie structurée dans LangChain ?
Pour utiliser l'analyseur de sortie structurée dans LangChain, suivez simplement ces étapes :
Étape 1 : Installer les prérequis
Démarrez le processus en installant le framework LangChain s'il n'est pas déjà installé dans votre environnement Python :
pépin installer chaîne de langue
Installez le framework OpenAI pour accéder à ses méthodes pour créer un analyseur dans LangChain :
pépin installer ouvert
Après cela, connectez-vous simplement à l’environnement OpenAI à l’aide de sa clé API pour accéder à son environnement à l’aide du « toi ' et fournissez la clé API à l'aide du ' obtenir un laissez-passer ' bibliothèque:
importez-nousimporter getpass
os.environ [ 'OPENAI_API_KEY' ] = getpass.getpass ( « Clé API OpenAI : » )

Étape 2 : Créer un schéma pour la sortie/réponse
Après avoir obtenu la connexion à OpenAI, importez simplement les bibliothèques pour créer le schéma permettant de générer la sortie :
à partir de langchain.output_parsers import StructuredOutputParser, ResponseSchemaà partir de langchain.prompts, importez PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
à partir de langchain.llms, importer OpenAI
depuis langchain.chat_models importer ChatOpenAI
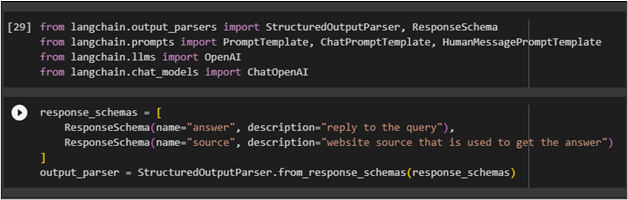
Spécifiez le schéma de la réponse conformément aux exigences afin que le modèle génère la réponse en conséquence :
réponse_schemas = [Schéma de réponse ( nom = 'répondre' , description = 'répondre à la requête' ) ,
Schéma de réponse ( nom = 'source' , description = 'source de site Web utilisée pour obtenir la réponse' )
]
output_parser = StructuredOutputParser.from_response_schemas ( réponse_schemas )
Étape 3 : Formater le modèle
Après avoir configuré le schéma pour la sortie, définissez simplement le modèle pour l'entrée en langage naturel afin que le modèle puisse comprendre les questions avant de récupérer la réponse :
format_instructions = sortie_parser.get_format_instructions ( )invite = Modèle d'invite (
modèle = 'Donnez la réponse à la question de l'utilisateur. \n {modèle} \n {requête}' ,
variables_d'entrée = [ 'requête' ] ,
variables_partielles = { 'modèle' : format_instructions }
)

Méthode 1 : utiliser le modèle de langage
Après avoir configuré les modèles de format pour les questions et réponses, construisez simplement le modèle à l'aide de la fonction OpenAI() :
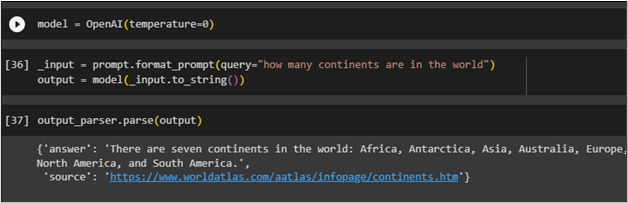
modèle = OpenAI ( température = 0 )
Définissez l'invite dans le ' requête ' variable et transmettez-la à la format_prompt() fonctionner comme entrée, puis stocker la réponse dans le « sortir 'variable :
_input = prompt.format_prompt ( requête = 'combien de continents y a-t-il dans le monde' )sortie = modèle ( _input.to_string ( ) )
Appeler le analyser() fonction avec la variable de sortie comme argument pour obtenir la réponse du modèle :
sortie_parser.parse ( sortir )
L'analyseur de sortie obtient la réponse à la requête et affiche une réponse détaillée avec le lien vers la page du site Web utilisée pour obtenir la réponse :
Méthode 2 : utiliser le modèle de chat
Pour obtenir les résultats de l'analyseur de sortie dans LangChain, utilisez le chat_model variable ci-dessous :
chat_model = ChatOpenAI ( température = 0 )
Pour comprendre l'invite, configurez le modèle d'invite pour le modèle de discussion. Ensuite, générez la réponse en fonction de l'entrée :
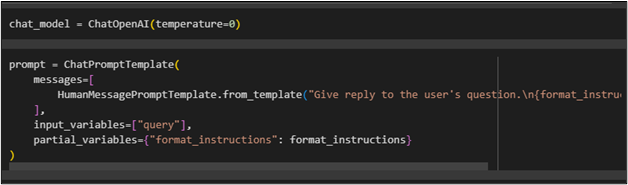
invite = ChatPromptTemplate (messages = [
HumanMessagePromptTemplate.from_template ( 'Donnez la réponse à la question de l'utilisateur. \n {format_instructions} \n {requête}' )
] ,
variables_d'entrée = [ 'requête' ] ,
variables_partielles = { 'format_instructions' : format_instructions }
)
Après cela, fournissez simplement l'entrée dans le champ ' requête ' variable puis transmettez-la à la chat_model() fonction pour obtenir la sortie du modèle :
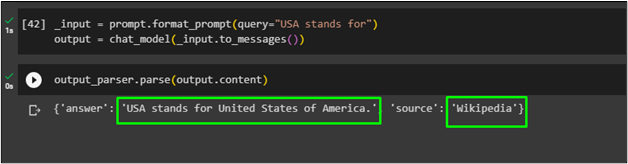
_input = prompt.format_prompt ( requête = 'USA signifie' )sortie = chat_model ( _input.to_messages ( ) )
Pour obtenir la réponse du modèle de chat, utilisez le output_parser qui stocke le résultat du « sortir 'variable :
sortie_parser.parse ( sortie.content )
Le modèle de chat affichait la réponse à la requête et le nom du site Web utilisé pour obtenir la réponse sur Internet :
Il s’agit d’utiliser un analyseur de sortie structuré dans LangChain.
Conclusion
Pour utiliser l'analyseur de sortie structurée dans LangChain, installez simplement les modules LangChain et OpenAI pour démarrer le processus. Après cela, connectez-vous à l'environnement OpenAI à l'aide de sa clé API, puis configurez les modèles d'invite et de réponse pour le modèle. L'analyseur de sortie peut être utilisé avec un modèle de langage ou un modèle de discussion. Ce guide explique l'utilisation de l'analyseur de sortie avec les deux méthodes.