Aperçu rapide
Cet article contient les sections suivantes :
- Comment utiliser un agent API asynchrone dans LangChain
- Installation de frameworks
- Environnement OpenAI
- Importation de bibliothèques
- Questions de configuration
- Méthode 1 : utilisation de l'exécution en série
- Méthode 2 : utilisation de l'exécution simultanée
- Conclusion
Comment utiliser un agent API asynchrone dans LangChain ?
Les modèles de chat effectuent plusieurs tâches simultanément, comme comprendre la structure de l'invite, ses complexités, extraire des informations et bien d'autres encore. L'utilisation de l'agent API Async dans LangChain permet à l'utilisateur de créer des modèles de discussion efficaces capables de répondre à plusieurs questions à la fois. Pour découvrir le processus d'utilisation de l'agent API Async dans LangChain, suivez simplement ce guide :
Étape 1 : Installation des frameworks
Tout d'abord, installez le framework LangChain pour récupérer ses dépendances depuis le gestionnaire de packages Python :
pip installer langchain
Après cela, installez le module OpenAI pour créer le modèle de langage comme llm et définissez son environnement :
pip installer openai
Étape 2 : Environnement OpenAI
La prochaine étape après l'installation des modules est mise en place de l'environnement en utilisant la clé API d’OpenAI et API Serper pour rechercher des données de Google :
importer toi
importer obtenir un laissez-passer
toi . environ [ 'OPENAI_API_KEY' ] = obtenir un laissez-passer . obtenir un laissez-passer ( « Clé API OpenAI : » )
toi . environ [ 'SERPER_API_KEY' ] = obtenir un laissez-passer . obtenir un laissez-passer ( « Clé API du serveur : » )
Étape 3 : Importer des bibliothèques
Maintenant que l'environnement est défini, importez simplement les bibliothèques requises comme asyncio et d'autres bibliothèques en utilisant les dépendances LangChain :
depuis chaîne de langue. agents importer initialiser_agent , charger_toolsimporter temps
importer asyncio
depuis chaîne de langue. agents importer Type d'agent
depuis chaîne de langue. llms importer OpenAI
depuis chaîne de langage. rappels . sortie standard importer StdOutCallbackHandlerStdOutCallbackHandler
depuis chaîne de langue. rappels . traceurs importer LangChainTracer
depuis aiohttp importer Session Client
Étape 4 : Questions de configuration
Définissez un ensemble de données de questions contenant plusieurs requêtes liées à différents domaines ou sujets pouvant être recherchés sur Internet (Google) :
des questions = ['Qui est le vainqueur de l'US Open en 2021' ,
'Quel âge a le petit ami d'Olivia Wilde' ,
'Qui est le vainqueur du titre mondial de Formule 1' ,
'Qui a remporté la finale féminine de l'US Open en 2021' ,
'Qui est le mari de Beyoncé et quel est son âge' ,
]
Méthode 1 : utilisation de l'exécution en série
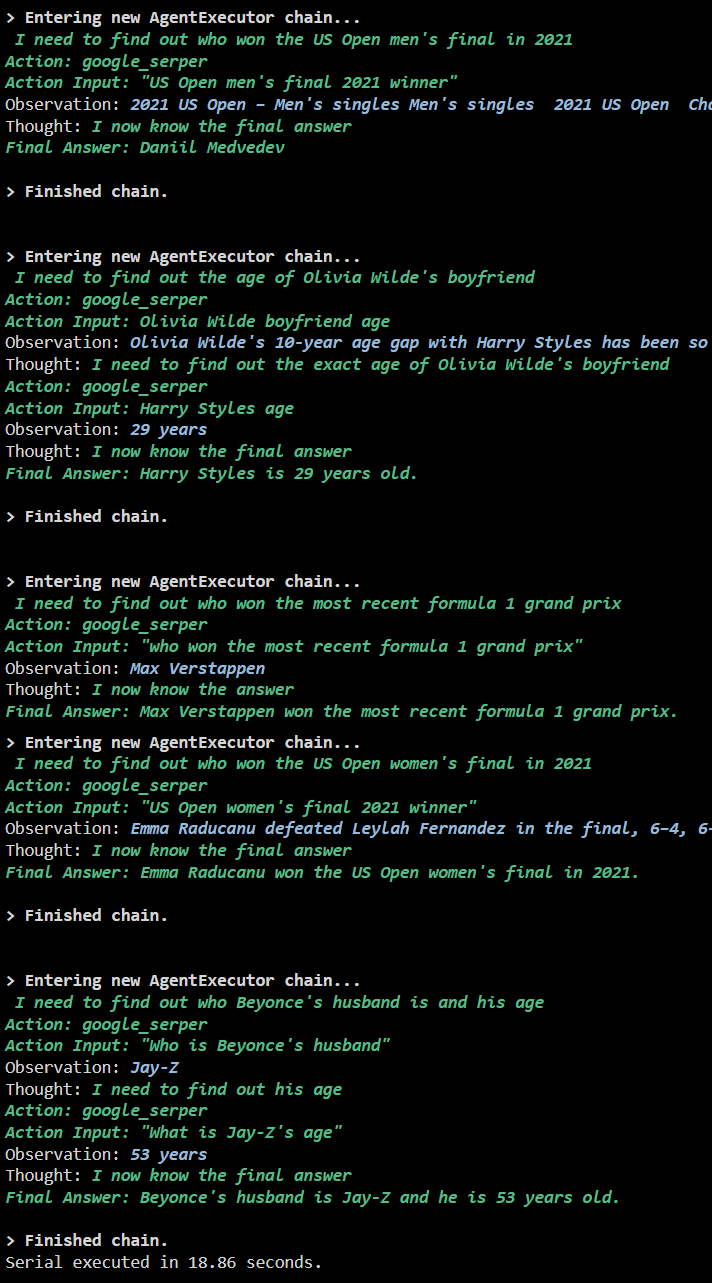
Une fois toutes les étapes terminées, exécutez simplement les questions pour obtenir toutes les réponses en utilisant l'exécution en série. Cela signifie qu'une question sera exécutée/affichée à la fois et renverra également le temps complet nécessaire pour exécuter ces questions :
llm = OpenAI ( température = 0 )outils = charger_tools ( [ 'en-tête google' , 'llm-math' ] , llm = llm )
agent = initialiser_agent (
outils , llm , agent = Type d'agent. ZERO_SHOT_REACT_DESCRIPTION , verbeux = Vrai
)
s = temps . compteur_perf ( )
#configuration du compteur de temps pour obtenir le temps utilisé pour le processus complet
pour q dans des questions:
agent. courir ( q )
écoulé = temps . compteur_perf ( ) -s
#imprimer le temps total utilisé par l'agent pour obtenir les réponses
imprimer ( F 'Série exécutée en {elapsed:0.2f} secondes.' )
Sortir
La capture d'écran suivante montre que chaque question reçoit une réponse dans une chaîne distincte et une fois la première chaîne terminée, la deuxième chaîne devient active. L'exécution en série prend plus de temps pour obtenir toutes les réponses individuellement :
Méthode 2 : utilisation de l'exécution simultanée
La méthode d'exécution simultanée prend toutes les questions et obtient leurs réponses simultanément.
llm = OpenAI ( température = 0 )outils = charger_tools ( [ 'en-tête google' , 'llm-math' ] , llm = llm )
#Configuration de l'agent à l'aide des outils ci-dessus pour obtenir des réponses simultanément
agent = initialiser_agent (
outils , llm , agent = Type d'agent. ZERO_SHOT_REACT_DESCRIPTION , verbeux = Vrai
)
#configuration du compteur de temps pour obtenir le temps utilisé pour le processus complet
s = temps . compteur_perf ( )
Tâches = [ agent. maladie ( q ) pour q dans des questions ]
attendez asyncio. rassembler ( *Tâches )
écoulé = temps . compteur_perf ( ) -s
#imprimer le temps total utilisé par l'agent pour obtenir les réponses
imprimer ( F 'Exécution simultanée en {elapsed:0.2f} secondes' )
Sortir
L'exécution simultanée extrait toutes les données en même temps et prend beaucoup moins de temps que l'exécution en série :
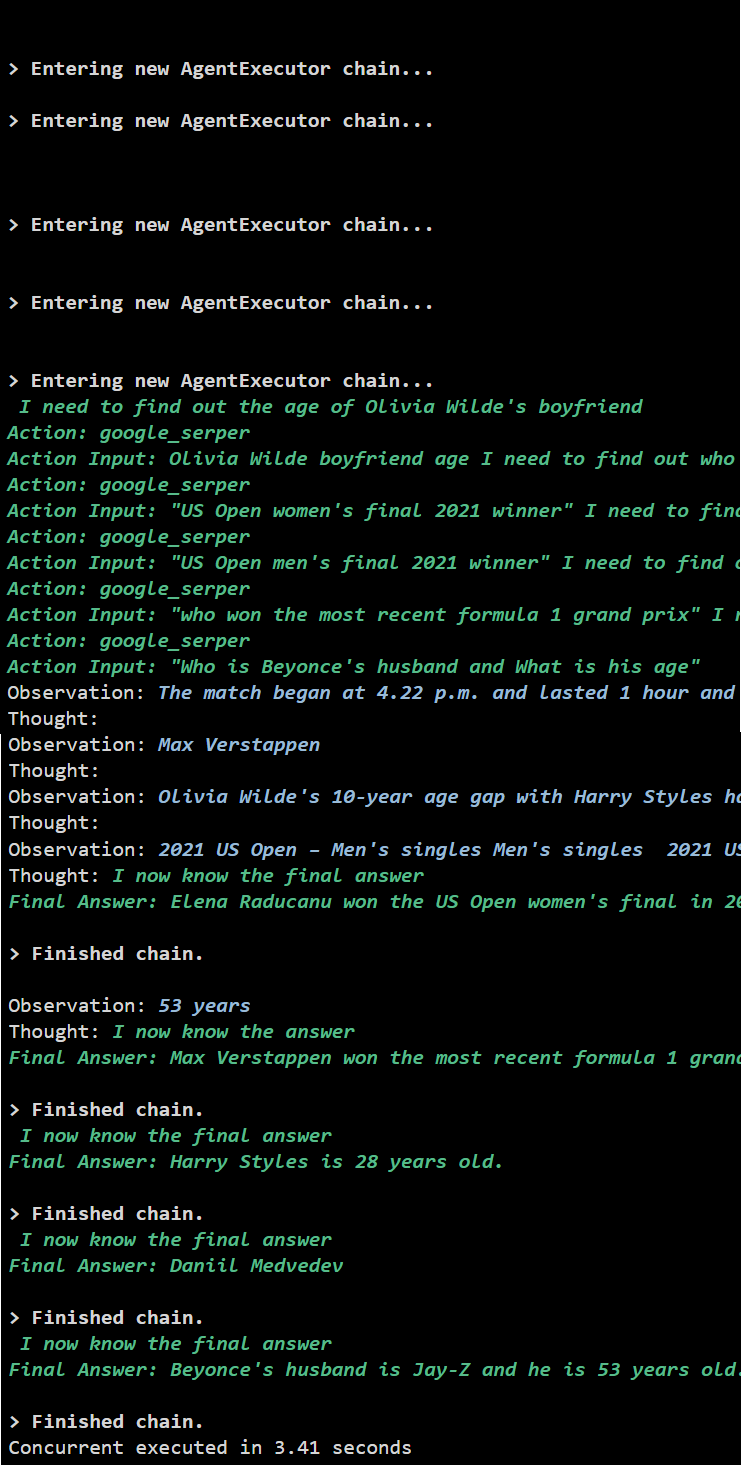
Il s’agit d’utiliser l’agent API Async dans LangChain.
Conclusion
Pour utiliser l'agent API Async dans LangChain, installez simplement les modules pour importer les bibliothèques depuis leurs dépendances pour obtenir la bibliothèque asyncio. Après cela, configurez les environnements à l'aide des clés API OpenAI et Serper en vous connectant à leurs comptes respectifs. Configurez l'ensemble des questions liées à différents sujets et exécutez les chaînes en série et simultanément pour obtenir leur temps d'exécution. Ce guide a expliqué le processus d'utilisation de l'agent API Async dans LangChain.