Évolutivité
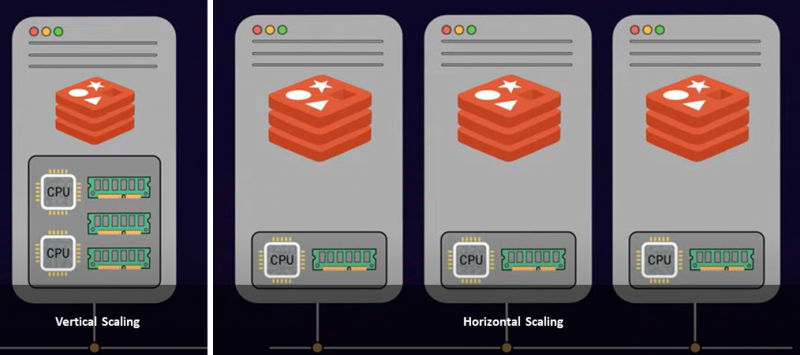
Il existe deux approches courantes pour faire évoluer un serveur : la mise à l'échelle verticale et la mise à l'échelle horizontale. La mise à l'échelle verticale ou la mise à l'échelle consiste à ajouter plus de puissance et de ressources à votre serveur, telles que plus de processeurs, de mémoire et de stockage, ce qui est coûteux. D'autre part, la mise à l'échelle horizontale ajoute plusieurs nœuds à votre pool de ressources existant. C'est ce qu'on appelle la mise à l'échelle. Ainsi, en fonction de vos limites et de vos exigences, il vous appartient d'avoir une seule instance de serveur plus grande ou de déployer plusieurs nœuds de serveur.
Supposons que vous disposiez de 100 Go de RAM et que vous ayez besoin de stocker 200 Go de données. Dans ce cas, vous avez deux choix :
- Évoluez en ajoutant plus de RAM au système
- Évoluez en ajoutant une autre instance de serveur avec 100 Go de RAM
Si vous avez atteint la limite maximale de RAM au sein de votre infrastructure, la mise à l'échelle est l'approche idéale. De plus, la mise à l'échelle augmentera considérablement le débit de la base de données.
Éclatement Redis
C'est un fait connu que Redis fonctionne sur un seul thread. Ainsi, Redis n'est pas capable d'utiliser plusieurs cœurs du processeur de votre serveur pour traiter les commandes. Par conséquent, l'ajout de plus de cœurs de processeur ne vous donne pas beaucoup de débit ou de performances avec Redis. Ce n'est pas le cas avec le partage de vos données entre plusieurs instances de serveur. L'ajout de plusieurs serveurs et la répartition de l'ensemble de données entre ceux-ci permettent le traitement parallèle des demandes des clients, ce qui augmente le débit. De plus, les performances globales peuvent augmenter de manière quasi linéaire.
Cette approche de fractionnement ou de distribution des données entre plusieurs serveurs en tenant compte de la mise à l'échelle s'appelle partitionnement . Tous les serveurs qui stockent des portions de données sont appelés fragments .
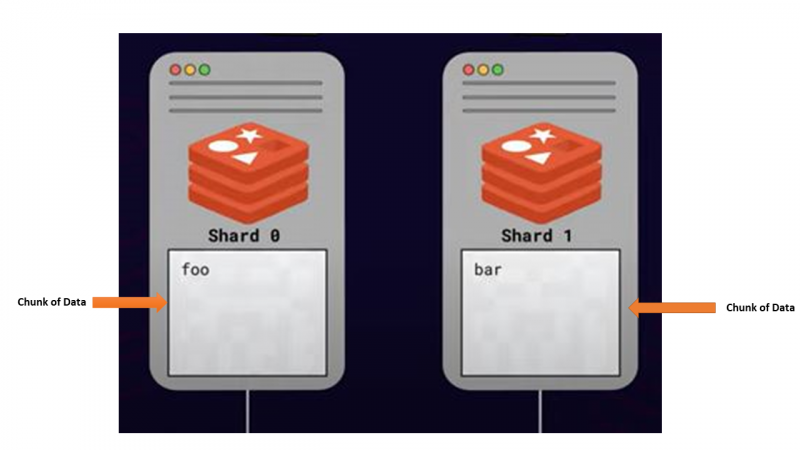
Comment se fait le sharding — Sharding algorithmique
L'une des principales préoccupations concernant le sharding était de savoir comment localiser une clé donnée parmi plusieurs nœuds Redis. Étant donné qu'une clé donnée peut être stockée dans n'importe quelle partition disponible, interroger toutes les partitions pour trouver une clé spécifique n'est pas la meilleure option. Ainsi, il devrait y avoir un moyen de mapper chaque clé à un fragment spécifique, et Redis utilise une stratégie de partitionnement algorithmique.
L'approche la plus courante consiste à calculer une valeur de hachage à l'aide du nom et du modulo de la clé Redis. Ensuite, divisez-le par les fragments Redis disponibles dans le système.
HASH_SLOT = CRC16(clé) mod 16384C'est une assez bonne solution tant que le nombre total de fragments est constant. Chaque fois que vous ajoutez une nouvelle instance de serveur Reids, la valeur résultante pour une clé donnée peut changer puisque le nombre total de fragments a augmenté. Il finira par interroger le mauvais fragment Redis. Par conséquent, vous devez suivre le processus de repartitionnement en calculant le nouveau fragment pour chaque clé et en transférant les données vers le bon serveur, ce qui est fastidieux et pas une tâche triviale si votre nombre total de fragments augmente de temps en temps.
Redis utilise une nouvelle entité logique appelée fente de hachage pour éviter ce problème. Plusieurs emplacements de hachage sont disponibles pour un fragment donné, et un seul emplacement de hachage peut contenir plusieurs clés Redis. Il y a 16384 emplacements de hachage dans un cluster de base de données Redis qui reste inchangé. La division modulo est effectuée avec le nombre d'emplacements de hachage au lieu du nombre de fragments. Il fournit la position correcte de l'emplacement de hachage pour la clé spécifiée même lorsque le nombre de fragments a augmenté. Il simplifie le processus de repartitionnement en déplaçant les emplacements de hachage d'un fragment vers le nouveau qui divise les données entre les différentes instances Redis selon les besoins.
Avantages du partage Redis
Le partage Redis offre plusieurs avantages à votre système de base de données avec des modifications minimes.
Haut débit
Étant donné que Redis est à thread unique, le traitement de plusieurs demandes client ne peut pas être traité en parallèle à l'aide de plusieurs cœurs de processeur. Ainsi, l'ajout de nouvelles partitions ou instances de serveur garantit que vous pouvez effectuer des opérations Redis en parallèle. Il augmente les opérations par seconde dans votre base de données Redis, ce qui vous donne finalement un débit élevé.
La haute disponibilité
Avec l'approche de partitionnement, le cluster Redis peut mettre en place une architecture maître-réplica qui garantit une haute disponibilité et durabilité.
Lire les répliques
Le partitionnement vous permet de conserver une copie exacte de vos données et de fournir des opérations de lecture via des instances Redis distinctes, ce qui augmente les performances de l'exécution de votre requête de lecture.
Outre ces avantages, le partitionnement peut provoquer des situations de cerveau divisé lorsque vous avez un nombre pair de fragments dans le cluster Redis. Il est donc recommandé de conserver un nombre impair de fragments dans votre cluster Redis.
Conclusion
Pour résumer, le partitionnement Redis divise les données entre plusieurs serveurs, ce qui permet une mise à l'échelle et un débit élevé pour votre base de données. Comme indiqué, Redis utilise une stratégie de partitionnement algorithmique pour diriger les demandes des clients vers la bonne partition. Cela présente certains inconvénients lorsque le nombre total de fragments augmente. Ainsi, au lieu du nombre total de fragments, Redis utilise le nombre d'emplacements de hachage pour calculer le fragment approprié. Avec l'introduction du partitionnement, les bases de données Redis offrent une haute disponibilité, un débit élevé et des performances élevées.