Syntaxe
df [ ( cond_1 ) & ( cond_2 ) ]Exemple 01
Nous faisons ces codes sur l'application 'Spyder' et utiliserons l'opérateur 'ET' dans nos conditions dans 'pandas' ici. Comme nous faisons les codes pandas, nous devons d'abord importer les 'pandas en tant que pd' et obtiendrons sa méthode en mettant juste 'pd' dans notre code. Ensuite, nous générons un dictionnaire avec le nom 'Cond', et les données que nous insérons ici sont 'A1', 'A2' et 'A3' sont les noms de colonne, et nous ajoutons '1, 2 et 3' dans le ' A1', dans 'A2' il y a '2, 6 et 4' et le dernier 'A3', contient '3, 4 et 5'.
Ensuite, nous allons créer le DataFrame de ce dictionnaire en utilisant le 'pd.DataFrame' ici. Cela renverra le DataFrame des données de dictionnaire ci-dessus. Nous le rendons également en fournissant le 'print ()' ici, et après cela, nous appliquons certaines conditions et utilisons également l'opérateur '&' dans cette condition. La première condition ici est que 'A1 >= 1', puis nous mettons l'opérateur '&' et plaçons une autre condition qui est 'A2 < 5'. Lorsque nous exécutons ceci, il renverra le résultat si 'A1 >=1' et aussi 'A2 < 5'. Si les deux conditions sont satisfaites ici, alors il affichera le résultat, et si l'une d'entre elles n'est pas satisfaite ici, alors il n'affichera aucune donnée.
Il vérifie les colonnes 'A1' et 'A2' du DataFrame, puis renvoie le résultat. Le résultat est affiché à l'écran car nous utilisons l'instruction « print () ».
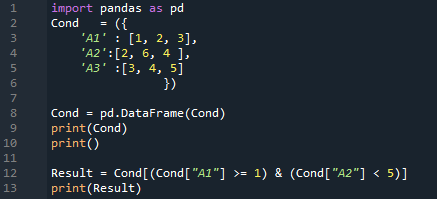
Le résultat est là. Il affiche toutes les données que nous avons insérées dans le DataFrame puis vérifie les deux conditions. Il renvoie les lignes dans lesquelles 'A1 >=1' et aussi 'A2 < 5'. Nous obtenons deux lignes dans cette sortie car les deux conditions sont satisfaites sur deux lignes.
Exemple 02
Dans cet exemple, nous créons directement le DataFrame après avoir importé les 'pandas as pd'. Le DataFrame 'Team' est créé ici, avec les données contenant quatre colonnes. La première colonne est ici la colonne « équipes » dans laquelle on met « A, A, B, B, B, B, C, C ». Ensuite, la colonne à côté des 'équipes' est 'score', dans laquelle nous insérons '25, 12, 15, 14, 19, 23, 25 et 29'. Après cela, la colonne que nous avons est 'Out', et nous y ajoutons également des données comme '5, 7, 7, 9, 12, 9, 9 et 4'. Notre dernière colonne ici est la colonne 'rebonds' qui contient également des données numériques, à savoir '11, 8, 10, 6, 6, 5, 9 et 12'.
Le DataFrame est terminé ici, et maintenant nous devons imprimer ce DataFrame, donc pour cela, nous plaçons le 'print ()' ici. Nous voulons obtenir des données spécifiques à partir de ce DataFrame, nous définissons donc certaines conditions ici. Nous avons ici deux conditions, et nous ajoutons l'opérateur 'ET' entre ces conditions, de sorte qu'il ne renverra que les conditions qui satisferont les deux conditions. La première condition que nous avons ajoutée ici est le 'score> 20' puis placez l'opérateur '&' et l'autre condition qui est 'Out == 9'.
Ainsi, il filtrera les données où le score de l'équipe est inférieur à 20 et leurs outs sont également de 9. Il les filtre et ignore le reste, qui ne satisfera pas les deux conditions ou l'une d'entre elles. Nous affichons également les données qui satisfont aux deux conditions, nous avons donc utilisé la méthode 'print ()'.
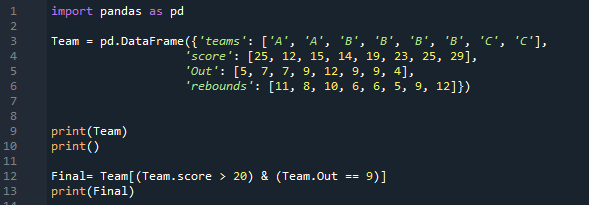
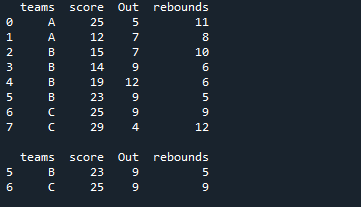
Seules deux lignes satisfont aux deux conditions, que nous avons appliquées à ce DataFrame. Il filtre uniquement les lignes dans lesquelles le score est supérieur à 20, et aussi, leurs sorties sont 9 et les affiche ici.
Exemple 03
Dans nos codes ci-dessus, nous insérons simplement les données numériques dans notre DataFrame. Maintenant, nous mettons des données de chaîne dans ce code. Après avoir importé les 'pandas en tant que pd', nous passons à la construction d'un DataFrame 'Membre'. Il contient quatre colonnes uniques. Le nom de la première colonne ici est 'Nom', et nous insérons les noms des membres, qui sont 'Alliés, Bills, Charles, David, Ethen, George et Henry'. La colonne suivante est nommée 'Emplacement' ici, et elle a 'Amérique. Canada, Europe, Canada, Allemagne, Dubaï et Canada ». La colonne 'Code' contient 'W, W, W, E, E, E et E'. Nous ajoutons également les 'points' des membres ici comme '11, 6, 10, 8, 6, 5 et 12'. Nous rendons le DataFrame 'Membre' avec l'utilisation de la méthode 'print ()'. Nous avons spécifié certaines conditions dans ce DataFrame.
Ici, nous avons deux conditions, et en ajoutant l'opérateur 'ET' entre elles, il ne renverra que les conditions qui satisfont aux deux conditions. Ici, la première condition que nous avons introduite est « Location == Canada », suivie de l'opérateur « & », et la deuxième condition, « points <= 9 ». Il obtient ces données du DataFrame dans lequel les deux conditions sont satisfaites, puis nous avons placé 'print ()' qui affiche les données dans lesquelles les deux conditions sont vraies.
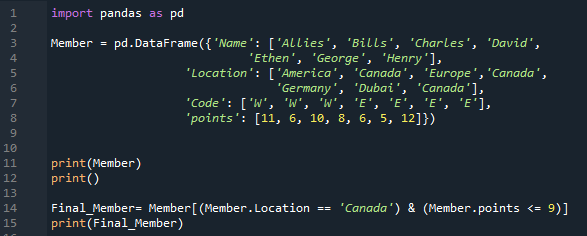
Ci-dessous, vous pouvez remarquer que deux lignes sont extraites du DataFrame et affichées. Dans les deux rangées, l'emplacement est « Canada » et les points sont inférieurs à 9.
Exemple 04
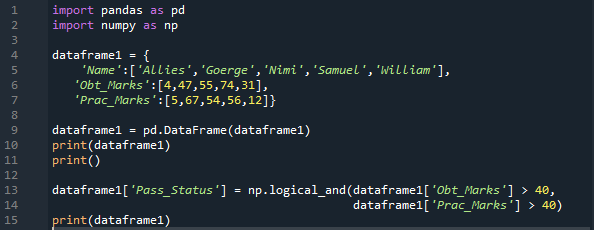
Nous importons à la fois les 'pandas' et 'numpy' ici en tant que 'pd' et 'np', respectivement. Nous obtenons les méthodes 'pandas' en plaçant 'pd' et les méthodes 'numpy' en plaçant le 'np' là où c'est nécessaire. Ensuite, le dictionnaire que nous avons créé ici contient trois colonnes. Dans la colonne « Nom » dans laquelle, nous insérons « Alliés, George, Nimi, Samuel et William ». Ensuite, nous avons la colonne 'Obt_Marks', qui contient les notes obtenues des étudiants, et ces notes sont '4, 47, 55, 74 et 31'.
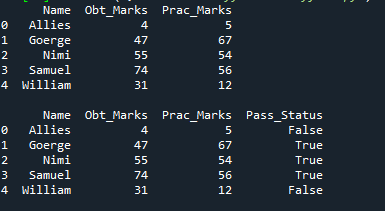
Nous créons également une colonne pour les 'Prac_Marks' ici qui ont les notes pratiques de l'étudiant. Les notes que nous ajoutons ici sont '5, 67, 54, 56 et 12'. Nous créons le DataFrame de ce dictionnaire puis l'imprimons. Nous appliquons ici le 'np.Logical_and', qui renverra le résultat sous la forme 'True' ou 'False'. Nous stockons également le résultat après avoir vérifié les deux conditions dans une nouvelle colonne, que nous avons créée ici avec le nom 'Pass_Status'.
Il vérifie que « Obt_Marks » est supérieur à « 40 » et « Prac_Marks » est supérieur à « 40 ». Si les deux sont vrais, alors il sera rendu vrai dans la nouvelle colonne ; sinon, il rend faux.
La nouvelle colonne est ajoutée avec le nom 'Pass_Status', et cette colonne se compose uniquement de 'True' et 'False'. Il rend vrai là où les notes obtenues ainsi que les notes pratiques sont supérieures à 40 et fausses pour les lignes restantes.
Conclusion
L'objectif principal de ce didacticiel est d'expliquer le concept de 'et condition' dans les 'pandas'. Nous avons expliqué comment acquérir les lignes où les deux conditions sont satisfaites, ou nous obtenons également vrai pour celles où toutes les conditions sont satisfaites et faux pour les autres. Nous avons exploré quatre exemples ici. Les quatre exemples que nous avons établis dans ce didacticiel sont passés par ce processus. Les exemples de ce didacticiel ont tous été soigneusement présentés pour votre bénéfice. Ce tutoriel devrait vous aider à comprendre plus clairement cette idée.