'Pandas' est un outil performant pour l'environnement python. Il s'agit d'un code source 'ouvert' pour l'analyse des données. La jointure pandas et la méthode de fusion pandas sont utilisées pour joindre les deux dataframes ensemble en un seul dataframe. Dans les deux méthodes de pandas, la différence est que la fonction 'join' de pandas joint la trame de données à l'aide d'un index. Alors que la fonction pandas 'merge' rejoint le dataframe en utilisant l'index et la méthode de colonne dans laquelle nous pouvons sélectionner nous-mêmes la colonne souhaitée. La méthode de fusion des pandas est principalement utilisée par rapport à la méthode de jointure des pandas. Le logiciel que nous utiliserons pour l'implémentation est le logiciel 'spyder', qui se trouve dans l'environnement python qui nous fournira des avantages pour l'implémentation du code de la méthode pandas join() et de la fonction de la méthode pandas merge().
Syntaxe de la méthode Pandas Join()
'df1. rejoindre ( df2 ) ”Le 'df' dans la syntaxe ci-dessus est l'abréviation de 'dataframe'. Il y a deux dataframes dans la syntaxe avec la fonction 'dot join', qui sert à appeler la méthode. C'est la méthode pandas pour joindre deux dataframes. Cela fonctionne en utilisant l'index pour combiner les dataframes en un seul.
Syntaxe de la méthode Pandas Merge()
'df1. fusionner ( df2 , sur = 'nom de colonne' ) ”La syntaxe de la méthode de fusion pandas a deux dataframes comme 'df1' et 'df2'. La fonction 'dot merge' appelle la méthode de jonction des deux dataframes avec l'apparition de colonnes inversées.
Nous couvrirons les manières suivantes de combiner deux dataframes afin d'utiliser les méthodes de panda merge et pandas join :
- Chevauchement de la méthode Pandas Join.
- Les pandas rejoignent la méthode en utilisant une réinitialisation d'index.
- Méthode de fusion des pandas (colonne 'gauche et droite').
- Méthode de fusion Pandas explicite.
Création des dataframes pour la mise en œuvre de la méthode Pandas Merge et Pandas Join
Tout d'abord, nous devons créer un bloc de données. Pour cela, nous utiliserons l'outil 'spyder'. Après l'avoir ouvert, commencez à écrire le code. Importez des pandas en tant que 'pd' pour l'association de bibliothèque de pandas. Nous avons les variables de trame de données comme 'x', 'y', 'p' et 'q en conséquence et 'a' avec les valeurs '1' et 'b' avec la valeur attribuée comme '2'.

La sortie est un 'df' créé avec les valeurs assignées. Nous pouvons le rendre aussi gros que le sont les données.
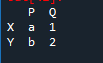
Créer une autre trame de données
Nous devons créer une autre base de données, pour comprendre clairement les méthodes de jonction et de fusion des pandas. Ici, nous avons 'df' créé de la même manière que le 'df' ci-dessus, seules les valeurs attribuées aux variables sont différentes. Nous avons 'h', 'j', 's' et 'd', alors que nous attribuons les valeurs 'b' avec la valeur '8' et 'Y' avec la valeur '3'.

La sortie montre un simple 'df' créé.

Exemple # 01 : Méthode Pandas Join (chevauchement)
Maintenant, nous allons voir comment joindre deux dataframes avec la méthode pandas join. Pour cette méthode, nous pouvons choisir la colonne de votre choix sur laquelle nous voulons travailler à partir du dataframe. Nous avons pris l'exemple avec la colonne qui se chevauche 'à gauche' du 'df', nous pouvons donc résoudre ce problème avec le 'suffixe' pour surmonter le chevauchement des données. Ici, les variables utilisées sont « x », « z », « v », « d ». « p », « o », « l » et « y » avec les valeurs attribuées comme « 3 », « 6 », « 7 » et « 9 ». Le '.join' appelle la méthode, avec l'alignement défini sur jointure gauche avec le suffixe 'df' droit. ”. Le 'suffixe' utilisé dans le code est dû au fait que dans la trame de données, il y a deux colonnes qui ont le même nom qui est 'clé' et qui ne chevaucheront pas les données.
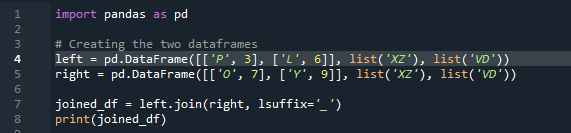
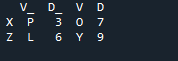
La sortie n'affiche aucune donnée superposée avec la méthode de jonction de deux 'df' à l'aide de la méthode de jointure pandas.
Exemple # 02 : Méthode de jointure Pandas utilisant une réinitialisation d'index
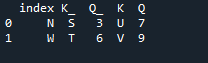
Dans cet exemple, nous spécifierons séparément la colonne avec le paramètre 'on' à utiliser comme 'clé' dans la méthode join qui aide à joindre les deux dataframes. la chose combinée est faite avec ce paramètre. De plus, l'index de l'un des deux 'df' doit être similaire pour les joindre. Des types de données similaires ou des données utilisées dans le même but peuvent être regroupées pour être traitées. Cela utilisera toujours l'index, en utilisant à partir de la droite. Les variables sont les « s », « t », « u », « v », « n », « w », « k » et « q ». Les valeurs attribuées sont « 3 », « 6 », « 7 » et « 9 ». Le 'reset dot index' est une méthode de pandas pour réinitialiser l'index du 'df'. L'index de réinitialisation définit tous les nombres entiers de votre liste de trames de données de 0 jusqu'à ce que les données de la trame de données soient allongées.
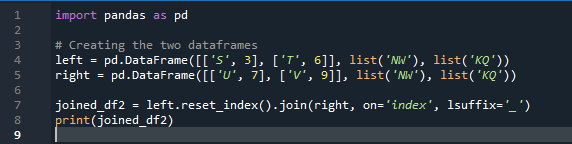
Voici la sortie affichée avec la méthode de jointure index 'key' de pandas.
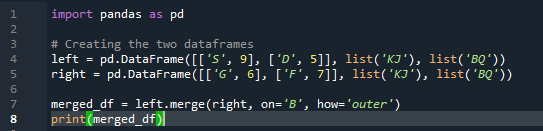
Exemple #03 : Pandas Merge Method (colonne « gauche et droite »)
La méthode de fusion effectue une opération similaire à la méthode de jointure pandas. Les deux méthodes consistent à combiner des données sur une base de données similaire. La méthode de fusion est plus polyvalente et nécessite de spécifier la clé. Nous pouvons également le spécifier sur les colonnes de gauche et de droite en fonction du travail de votre dataframe. Les variables du code sont « s », « d », « g », « f », « k », « j », « b » et « q ». les valeurs attribuées sont « 9 », « 5 », « 6 » et « 7 ». L'implémentation externe 'join' est effectuée sur les deux 'df' en utilisant le paramètre 'how' de la fonction de méthode de fusion pandas.
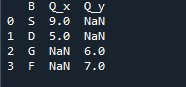
La sortie que nous voyons montre les données fusionnées des deux dataframes. Le 'NaN' représente 'pas un nombre', ce qui signifie que là où il n'y a pas de numéro attribué dans les données, le 'NaN' s'y affiche.
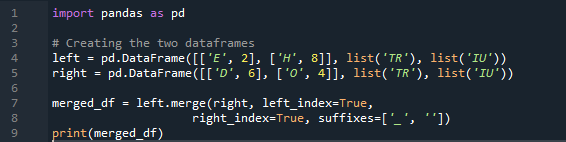
Exemple # 04 : La méthode Merge explicitement
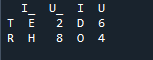
Ici, dans cet exemple, la méthode de fusion est la destruction de l'index et la valeur de l'index n'est pas supposée sur la trame de données. Nous ferons cette méthode en fonction du travail à faire, où le spécifiant explicite est à suivre. Il fusionnera les données basées sur un index gauche ou un index droit avec le paramètre. Les variables de cette base de données sont 't', 'r', 'I', 'u', 'h', 'o', 'e' et 'e'. Les valeurs attribuées sont « 2 », « 4 », « 6 » et « 4 ». L'exemple ci-dessus de la méthode de fusion des pandas avec la sélection de colonnes en fonction des besoins est la méthode la plus présentable et la plus précieuse pour joindre les deux dataframes. Vérifier à la fin de la ligne de code que la clé de fusion est unique dans l'ensemble de données.
Dans la sortie ci-dessous, l'index n'est pas affiché sans l'index, mais la fonction est exécutée en fonction de l'index droit et gauche.
Conclusion
Les méthodes merge() et join() sont toutes deux des méthodes très pratiques et efficaces. Ces deux fonctions sont utilisées pour joindre les deux dataframes séparés sur le même dataframe mais ont une utilisation différente selon le cas. Dans cet article, nous avons appris les principales différences entre les méthodes de jointure et de fusion des pandas. Après avoir fait les exemples et compris la méthode de jointure pandas, nous la conclurons en sachant que, si nous voulons une jointure plus flexible et de style base de données, il est préférable d'opter pour la méthode de fusion pandas. D'un autre côté, si nous voulons combiner la trame de données avec l'index de manière intensive, nous pouvons utiliser la fonction de méthode pandas join ().