Les données sont collectées chaque jour en grand nombre et la gestion du Big Data est le cas d'utilisation le plus important du moteur Elasticsearch. Les données sont stockées dans la base de données d'analyse en temps réel et l'utilisateur est autorisé à extraire des données pour en tirer des connaissances utiles à l'aide de requêtes. L'utilisateur peut appliquer des requêtes pour rechercher des données à partir de plusieurs index et les afficher dans un seul compartiment à partir de la base de données relationnelle.
Ce guide expliquera les agrégations Elasticsearch avec des exemples utilisant différentes agrégations.
Qu'est-ce qu'Elasticsearch Aggregation ?
Dans Elasticsearch, l'agrégation est le processus de combinaison ou de regroupement des champs pour extraire des informations de la base de données relationnelle. L'agrégation dans Elasticsearch peut être considérée comme la GROUPER PAR CLAUSE ou AGRÉGAT() fonction en langage SQL.
Comment utiliser l'agrégation Elasticsearch ?
Pour utiliser l'agrégation dans Elasticsearch, l'utilisateur doit avoir une compréhension de base de sa base de données. Explorons la syntaxe et sa mise en œuvre pratique :
Syntaxe
Pour trouver des données dans la base de données, la syntaxe de l'agrégation dans le moteur Elasticsearch est la suivante :
'les ags' : {'nom_de_l'agrégation' : {
'type_d'agrégation' : {
'champ' : 'nom_champ_document'
}
Les extraits ci-dessus :
-
- Il utilise le ' aggs ” mot-clé qui explique l'utilisation de l'agrégation dans la requête.
- Le nom_de_l'agrégation est défini par l'utilisateur en fonction des informations requises.
- Après cela, le type_of_aggregation est utilisé pour obtenir des données.
- La dernière ligne utilise le champ mot-clé suivi du nom de l'attribut du document.
Exemple 1 : Agrégation dans les exemples de données Kibana
Cette section explique l'agrégation à l'aide d'un exemple utilisant les exemples de données de Kibana en s'y connectant d'abord. Après cela, dirigez-vous simplement à l'intérieur du ' Outils de développement ” en le recherchant dans la barre de recherche et en cliquant dessus :
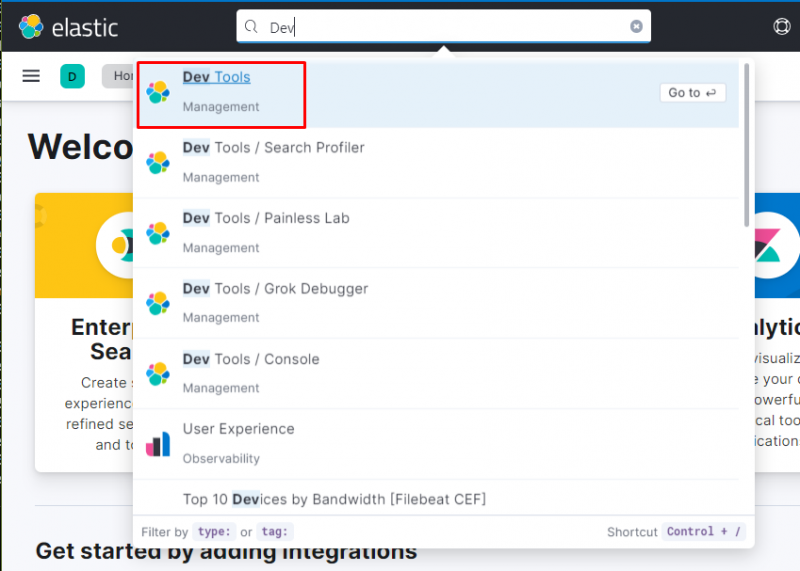
Extraire des données à partir d'exemples de données
Utilisez simplement la commande suivante pour récupérer les données du ' kibana_sample_data_logs ” index sur la console Dev Tools :
OBTENIR / kibana_sample_data_logs / _recherche
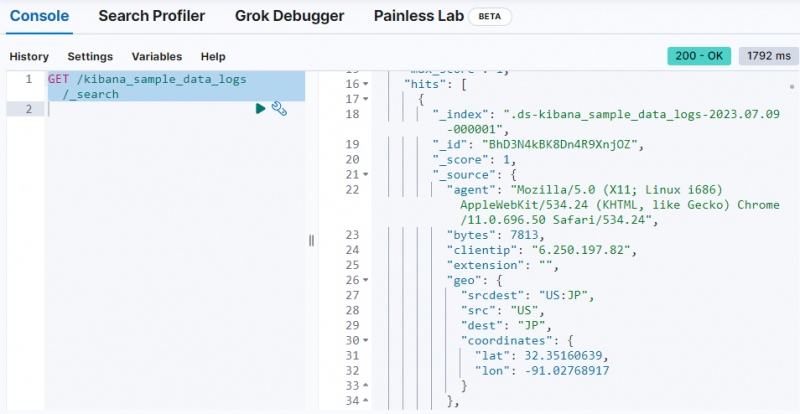
La sortie montre que les données ont été extraites du ' kibana_sample_data_logs ” indice.
Le code suivant utilise un OBTENIR demande sur le ' kibana_sample_data_log ' pour effectuer une recherche à partir de celui-ci en utilisant l'agrégation value_count sur le ' clientip ' champ:
OBTENIR / kibana_sample_data_logs / _recherche{ 'taille' : 0 ,
'les ags' : {
'ip_count' : {
'value_count' : {
'champ' : 'clientip'
}
}
}
}
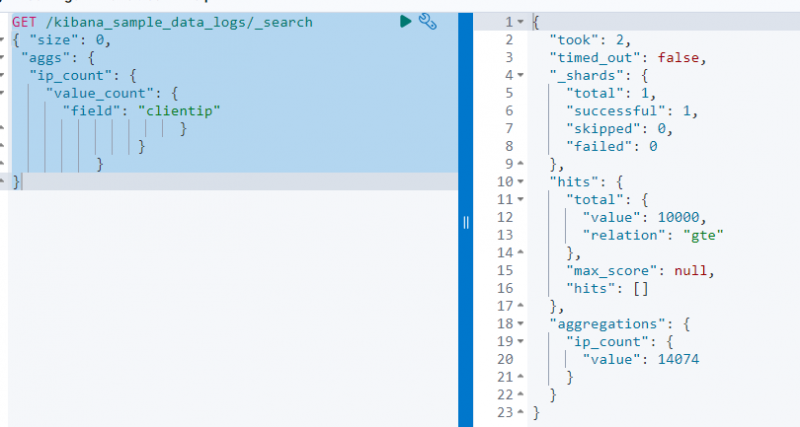
La capture d'écran ci-dessus affiche l'agrégation sur le clientip champ avec la valeur 14074 .
Agrégations importantes
Certaines des agrégations importantes qui sont utilisées pour trouver efficacement des données à partir de la base de données sont mentionnées ci-dessous :
Les exemples suivants expliquent les agrégations mentionnées ci-dessus en utilisant le OBTENIR demande du ' kibana_sample_data_ecommerce ” indice :
Agrégation de cardinalité
Le code suivant utilise le ' cardinalité ' agrégation sur le ' sku ” champ des données e-commerce. L'exécution de ce code obtiendra une agrégation à valeur unique pour obtenir les SKU uniques de la base de données Elasticsearch :
OBTENIR / kibana_sample_data_ecommerce / _recherche{
'taille' : 0 ,
'les ags' : {
'unique_skus' : {
'cardinalité' : {
'champ' : 'sku'
}
}
}
}
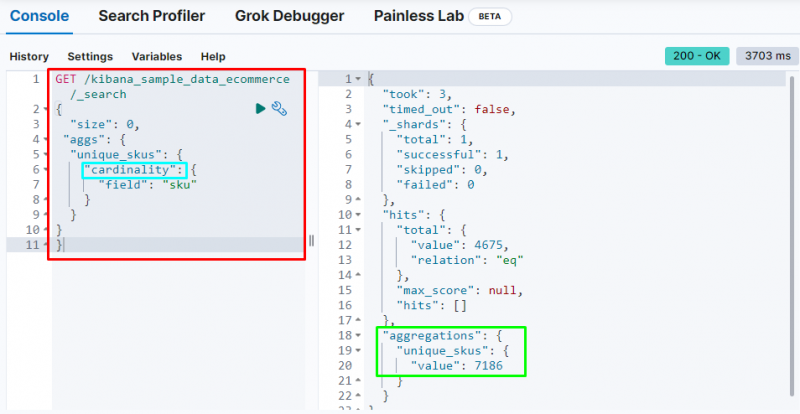
Il affiche le cardinalité agrégation trouver le 7186 valeurs de l'indice.
Agrégation de statistiques
Une autre agrégation importante est le ' Statistiques ' agrégation qui est utilisée pour obtenir le ' compter ”, “ min ”, “ maximum ”, “ moyenne ', et ' somme ' les statistiques du ' quantité totale ' champ:
OBTENIR / kibana_sample_data_ecommerce / _recherche{
'taille' : 0 ,
'les ags' : {
'statistiques_quantité' : {
'Statistiques' : {
'champ' : 'quantité totale'
}
}
}
}
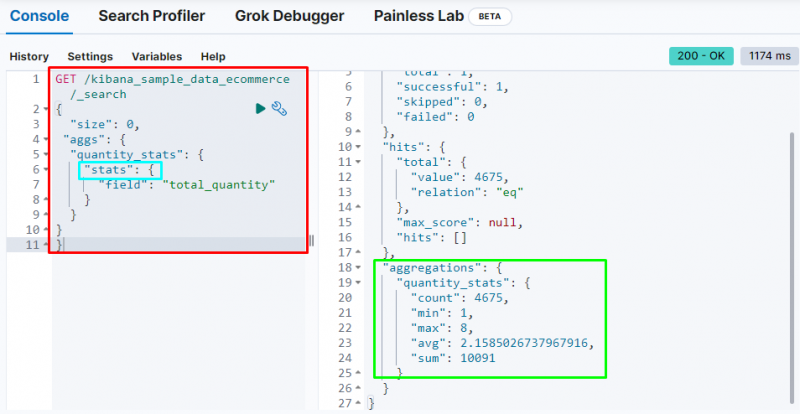
La capture d'écran ci-dessus affiche les statistiques dans la sortie du ' quantité totale ' champ.
Filtrer l'agrégation
L'agrégation de filtres est utilisée pour filtrer les données basées sur un terme ou une phrase de la base de données car le code suivant le contient :
OBTENIR / kibana_sample_data_ecommerce / _recherche{ 'taille' : 0 ,
'les ags' : {
'filter_aggregation' : {
'filtre' : {
'terme' : {
'utilisateur' : 'eddie' } } ,
'les ags' : {
'prix_moyen' : {
'moyenne' : {
'champ' : 'produits.prix' } }
} } } }
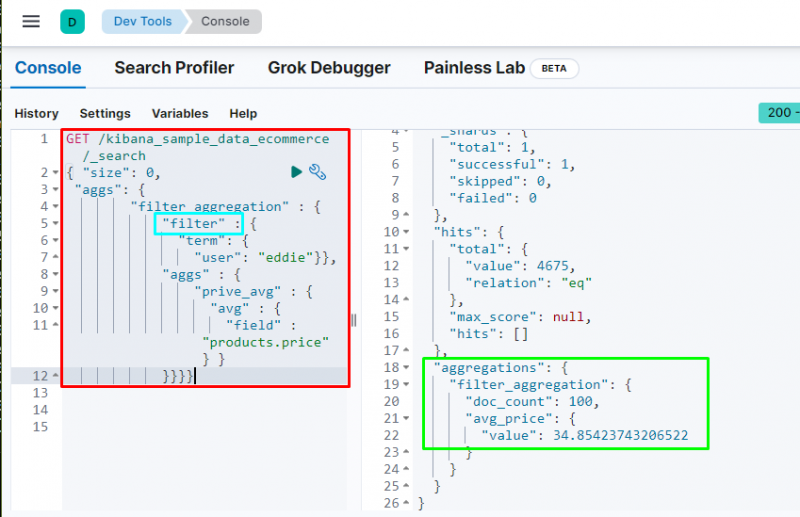
L'exécution du code filtrera les données en fonction du ' Eddie ” utilisateur et affiche le prix moyen des articles achetés. La capture d'écran ci-dessus montre que le utilisateur a trouvé 100 fois à partir des données et de la valeur de la moyenne _ prix agrégation.
Agrégation de termes
Le terme agrégation crée un compartiment et stocke les données du champ dans le compartiment et le code suivant utilise le ' utilisateur ” pour stocker ses données dans le bucket :
OBTENIR / kibana_sample_data_ecommerce / _recherche{
'taille' : 0 ,
'les ags' : {
'Term_Aggregation' : {
'termes' : {
'champ' : 'utilisateur'
}
}
}
}
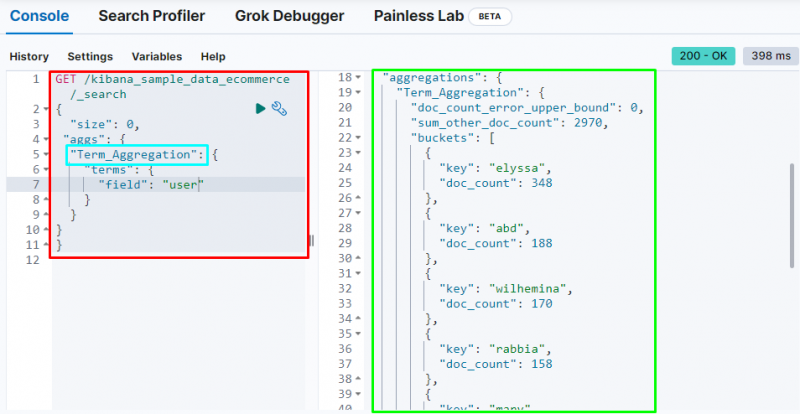
La capture d'écran suivante montre que le terme agrégation a créé des compartiments pour chaque utilisateur et leur nombre de documents.
Il s'agit de l'agrégation Elasticsearch et de différentes agrégations importantes.
Conclusion
Dans Elasticsearch, l'agrégation est utilisée pour obtenir des données à partir des documents agrégés et ces documents sont extraits d'un champ spécifique. Certaines agrégations importantes sont utilisées pour obtenir des informations utiles à partir des index. Ce guide a expliqué l'agrégation Elasticsearch et démontré le processus d'utilisation de l'agrégation Elasticsearch.