L'hébergement et la gestion des données dans des bases de données et des entrepôts de données ont toujours été une tâche ardue et fastidieuse. Cela nécessite beaucoup de ressources et de puissance de calcul pour donner un sens aux données. Amazon Web Services propose une solution unique à cet effet. Il dispose d’un service appelé Amazon Redshift qui gère entièrement les entrepôts de données des utilisateurs.
Cet article expliquera en détail Amazon Redshift ainsi que son architecture d'entrepôt de données. Tous les composants de l’architecture du système d’entrepôt de données de Redshift seront expliqués en détail.
Qu’est-ce qu’Amazon Redshift ?
L'informatique est un service d'entreposage de données fourni par Amazon. Il gère et analyse efficacement de grands ensembles de données à des fins d'analyse et de reporting. Il est construit sur un modèle de stockage en colonnes. Il utilise des clusters de nœuds de calcul contrôlés par un nœud leader pour fournir un traitement de données hautes performances.
Il prend des données provenant de différentes sources et les regroupe pour créer un entrepôt de données. Il offre différentes fonctionnalités, telles que le partage de données et l'analyse en temps réel. Consultez l'image ci-dessous pour comprendre les fonctionnalités et capacités d'Amazon Redshift :
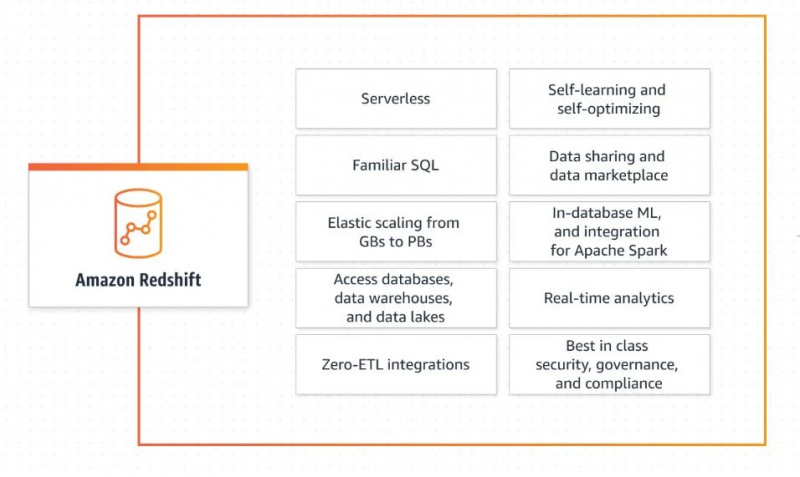
Passons maintenant à son architecture de système d’entrepôt de données.
Qu'est-ce que l'architecture du système d'entrepôt de données Amazon Redshift ?
Cette architecture système comporte trois parties principales. Ces pièces sont :
- Stockage
- Accélération
- Calcul
Comprenons leurs objectifs :
Stockage
La partie stockage concerne les services de stockage dont dispose Redshift. Il dispose de sa propre option de service de stockage géré ainsi que d’une option de compartiment S3.
Accélération
La partie accélération dépend du service de stockage utilisé et de la puissance de calcul utilisée. Le stockage géré par Redshift est plus rapide que les autres options de stockage
Calcul
La partie calcul concerne uniquement la puissance de calcul utilisée. Le calcul est effectué avec des clusters et les clusters ont des nœuds. Les nœuds ont à leur tour des tranches.
Pour mieux comprendre tous les éléments et composants de cette architecture, visualisez l'image ci-dessous :
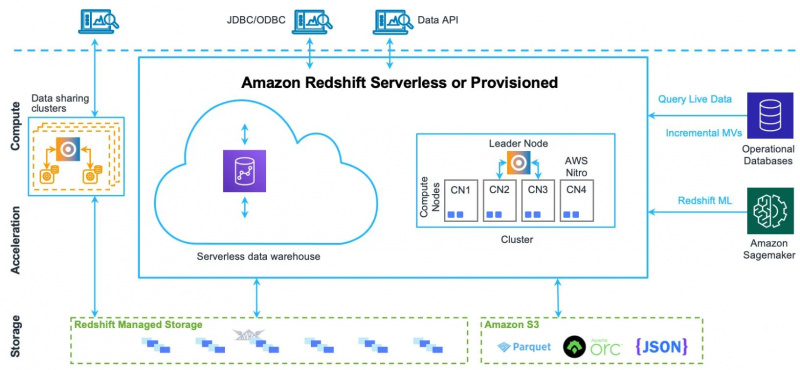
Comprenons ses composants un par un.
Quels sont les composants architecturaux d'Amazon Redshift ?
Voici les composants architecturaux d'Amazon Redshift :
- Groupes
- Nœuds
- Tranches de nœud
- Stockage
- Réseau interne
- Bases de données
Discutons-en un par un :
Groupes
Un cluster est l’unité fondamentale et centrale. Il comprend un certain nombre de nœuds. Si un cluster se compose de plusieurs nœuds de calcul, un nœud leader supplémentaire intervient pour coordonner les activités de ces nœuds de calcul et gérer la communication externe.
Nœuds
Les nœuds des clusters sont de deux types. Ceux-ci sont:
- Nœud leader
- Nœud de calcul
Comprenons-les un par un :
Nœud leader
Il gère la communication avec les programmes clients et coordonne les interactions avec les nœuds de calcul. Le nœud leader joue un rôle essentiel dans l'exécution de requêtes complexes. Il compile le code basé sur le plan d'exécution qui est distribué aux nœuds de calcul et attribue des parties de données à chaque nœud de calcul individuel.
Nœud de calcul
Les nœuds de calcul constituent l'épine dorsale de l'architecture d'Amazon Redshift. Ils effectuent à la fois le stockage et le traitement des données. Ceux-ci disposent de ressources dédiées, telles que la mémoire et le processeur.
Tranches de nœud
Les nœuds de calcul sont ensuite divisés en tranches. Ces tranches fonctionnent ensemble pour traiter les charges de travail assignées et réaliser un parallélisme pour améliorer le traitement des requêtes.
Stockage
Le stockage des données au sein d'Amazon Redshift est géré par « Redshift Managed Storage (RMS) ». Il a la capacité de faire évoluer le stockage de manière indépendante à l’aide du stockage « Amazon S3 ». RMS utilise un stockage local basé sur SSD hautes performances comme cache de niveau 1, ce qui optimise les performances.
Réseau interne
Ce réseau interne d'Amazon Redshift permet une communication rapide et sécurisée entre les nœuds leaders et les nœuds de calcul. Ce réseau n'est pas directement accessible aux applications clientes.
Bases de données
Les clusters disposent d'une ou plusieurs bases de données. Les données de ces bases de données se trouvent sur des nœuds de calcul. Les applications client communiquent avec le nœud leader. Le nœud de calcul gère l'exécution des requêtes sur les nœuds de calcul.
Il s’agit d’Amazon Redshift et de ses éléments architecturaux. Cet article a expliqué en détail les composants fonctionnels d'Amazon Redshift
Conclusion
L'architecture d'Amazon Redshift est la raison sur laquelle reposent ses capacités. Le nœud leader contrôle et gère les nœuds de calcul et les tranches de nœuds aident au traitement parallèle. Redshift Managed Storage utilise le stockage sur SSD pour améliorer les performances. Cet article a expliqué l'architecture du système Amazon Redshift Data Warehouse.