Ce guide explique les robots d'exploration de liste dans AWS.
Que sont les List-Crawlers dans AWS ?
Un analyseur est un composant d'AWS Glue qui est utilisé pour analyser l'emplacement des données et déduire ces informations dans le catalogue. Les informations qu'un robot d'exploration collecte peuvent être des types de données, une structure de schéma ou, en d'autres termes, il collecte des métadonnées. Crawler peut également être utilisé avec le catalogue de données qui est utilisé lorsque les données sont déplacées à l'intérieur de l'écosystème Glue lors de l'utilisation de tâches ETL, etc.
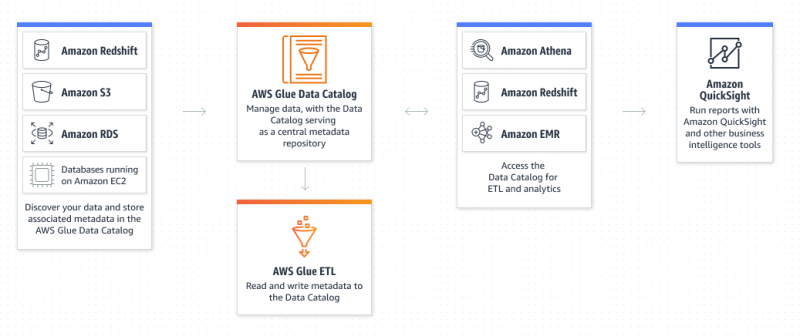
Qu'est-ce qu'Amazon Glue Service ?
AWS Glue est un service Amazon Extract Transform and Load qui permet à l'utilisateur d'organiser, de localiser, de déplacer et de transformer toutes les données. AWS Glue est sans serveur car l'utilisateur n'a pas besoin de provisionner et de configurer les serveurs ni de gérer les cycles de vie. Le catalogue de données et les robots d'exploration sont les composants d'AWS Glue qui agit en tant que référentiel de métadonnées persistantes :

Comment créer un robot d'exploration sur AWS ?
Pour créer un robot d'exploration sur AWS, visitez le service AWS Glue depuis AWS Management Console :
Dirigez-vous vers le ' Crawlers » page en cliquant sur son nom dans le panneau de gauche :
Clique sur le ' Créer un robot ' bouton:
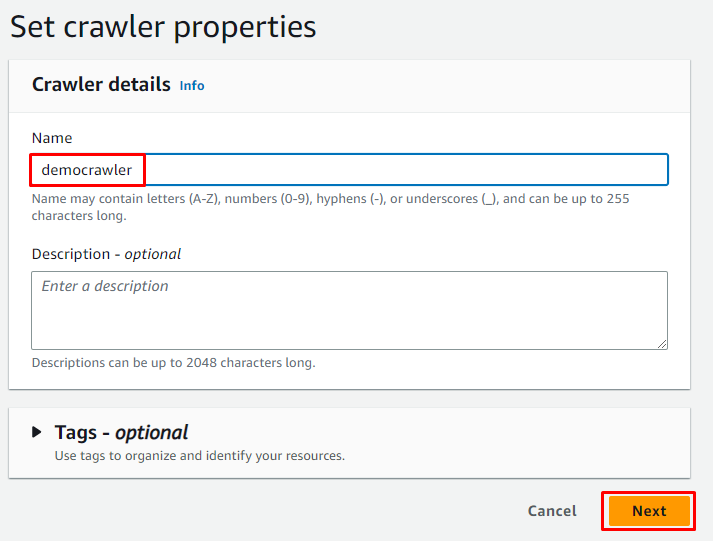
Tapez le nom du crawler et cliquez sur le ' Suivant ' bouton:
Sélectionnez l'option de mappage pour les tables de glue et cliquez sur le ' Ajouter une source ' bouton pour obtenir des données à partir de:

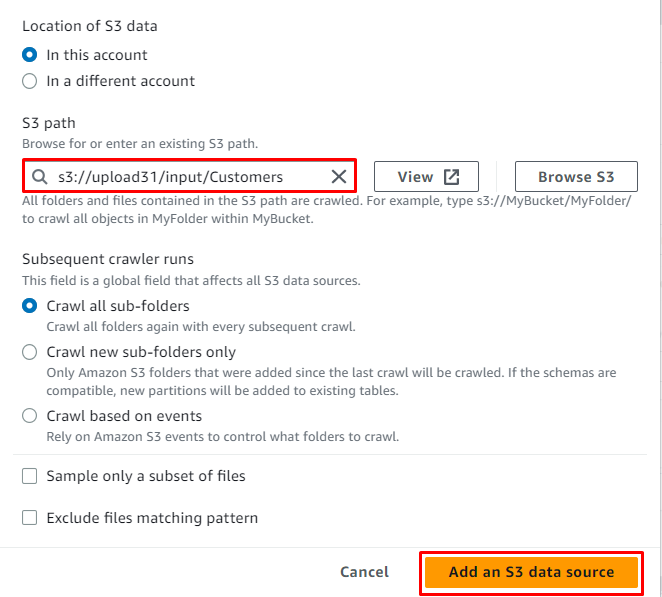
Sélectionnez le service S3 et cliquez sur le « Parcourir S3 ” bouton pour obtenir l'emplacement de la source :

Sélectionnez simplement le dossier S3 et cliquez sur le ' Choisir ' bouton:

Une fois l'emplacement ajouté à la source, il suffit de cliquer sur le ' Ajouter une source de données S3 ' bouton:
Clique sur le ' Suivant ' bouton:

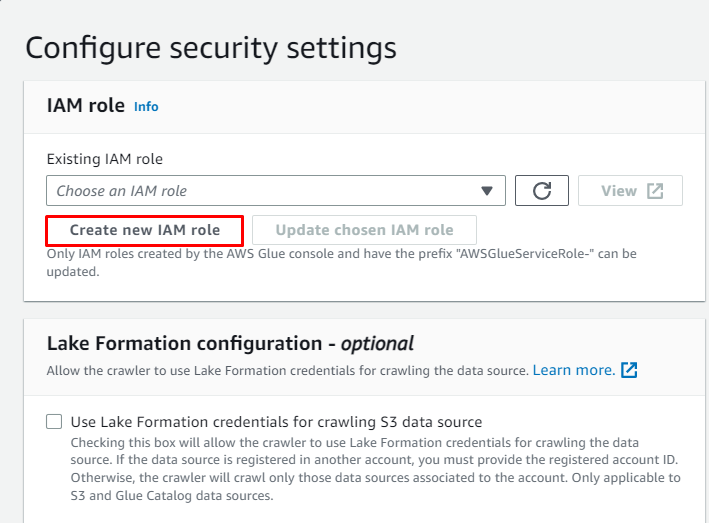
Clique sur le ' Créer un nouveau rôle IAM ' bouton de la ' Configurer les paramètres de sécurité ' section:
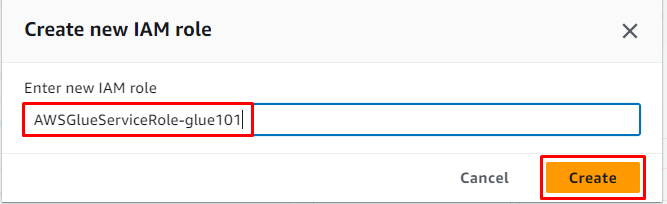
Entrez le nom du rôle et cliquez sur le ' Créer ' bouton:
Après cela, cliquez simplement sur le ' Suivant ' bouton:

Sélectionnez la base de données cible et saisissez le nom qui sera utilisé pour la table :
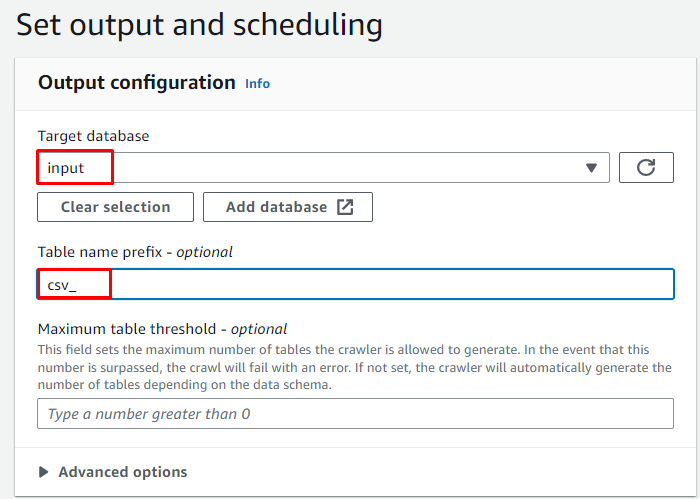
Programmez le robot d'exploration pour ' Sur demande » et cliquez sur le « Suivant ' bouton:
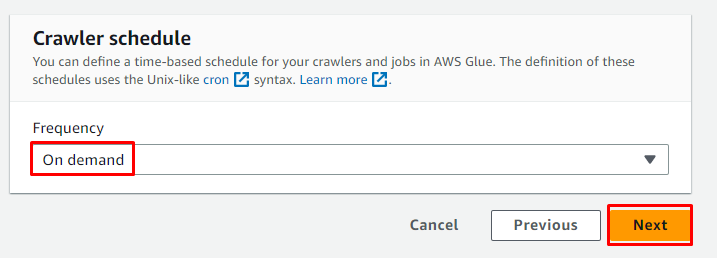
Passez en revue la configuration et cliquez sur le ' Créer un robot ' bouton:
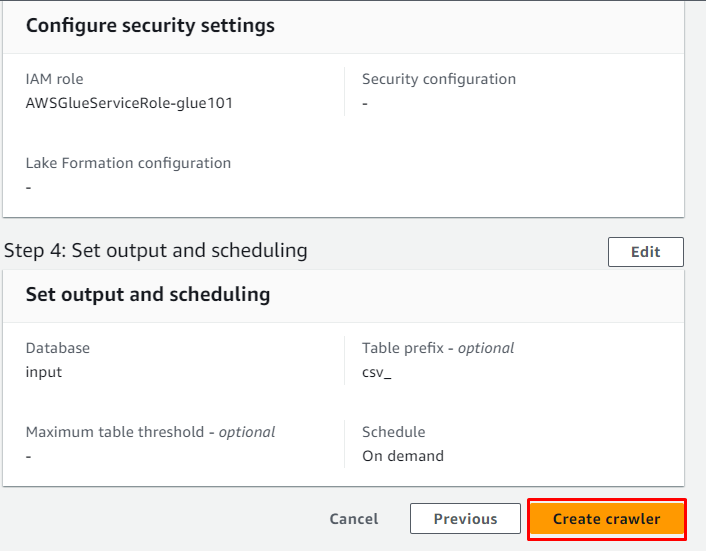
Le crawler a été créé avec succès et il peut être utilisé pour récupérer les données de la source en cliquant sur le ' Courir ' bouton:

C'est tout sur les robots d'exploration de liste dans AWS.
Conclusion
ListCrawler est le composant du service AWS Glue qui peut être utilisé pour explorer des informations à partir de sources et revenir au catalogue. Les catalogues de données et les robots d'exploration peuvent être utilisés pour collecter des données afin d'obtenir des informations sur les données appelées métadonnées. L'utilisateur peut également créer un robot d'exploration à partir d'AWS Glue pour obtenir des données du service S3 ou d'autres sources et placer des tables de création dans la base de données. Ce guide a expliqué les ListCrawlers dans AWS et comment les créer.