Conditions préalables
Vous devez installer le serveur de base de données avec le client avant de pratiquer les exemples de ce didacticiel. Le serveur et le client de base de données MariaDB sont utilisés dans ce tutoriel.
1. Exécutez les commandes suivantes pour mettre à jour le système :
$ sudo apt-obtenir la mise à jour
2. Exécutez la commande suivante pour installer le serveur et le client MariaDB :
$ sudo apt-get install mariadb-server mariadb-client
3. Exécutez la commande suivante pour installer le script de sécurité pour la base de données MariaDB :
$ sudo mysql_secure_installation
4. Exécutez la commande suivante pour redémarrer le serveur MariaDB :
$ sudo /etc/init.d/mariadb redémarrage
6. Exécutez la commande suivante pour vous connecter au serveur MariaDB :
$ sudo mariadb -u racine -pListe des exemples de requête SQL
- Créer la base de données
- Créer les tableaux
- Renommer le nom de la table
- Ajouter une nouvelle colonne au tableau
- Supprimer la colonne du tableau
- Insérer une seule ligne dans le tableau
- Insérer plusieurs lignes dans le tableau
- Lire tous les champs particuliers du tableau
- Lire le tableau après avoir filtré les données du tableau
- Lire le tableau après avoir filtré les données en fonction de la logique booléenne
- Lire le tableau après avoir filtré les lignes en fonction de la plage de données
- Lisez le tableau après avoir trié le tableau en fonction des colonnes particulières.
- Lire le tableau en définissant le nom alternatif de la colonne
- Compter le nombre total de lignes dans le tableau
- Lire les données de plusieurs tables
- Lire le tableau en regroupant les champs particuliers
- Lire le tableau après avoir omis les valeurs en double
- Lire le tableau en limitant le nombre de lignes
- Lire le tableau basé sur la correspondance partielle
- Compter la somme du champ particulier de la table
- Trouver les valeurs maximales et minimales du champ particulier
- Lire les données sur la partie particulière d'un champ
- Lire les données de la table après la concaténation
- Lire les données du tableau après calcul mathématique
- Créer une vue du tableau
- Mettre à jour le tableau en fonction de la condition particulière
- Supprimer les données du tableau en fonction de la condition particulière
- Supprimer tous les enregistrements de la table
- Laisser tomber le tableau
- Déposez la base de données
Créer la base de données
Supposons que nous devions concevoir une base de données simple pour le système de gestion de bibliothèque. Pour effectuer cette tâche, une base de données doit être créée sur le serveur qui contient plusieurs tables relationnelles. Après vous être connecté au serveur de base de données, exécutez la commande suivante pour créer une base de données nommée 'library' dans le serveur de base de données MariaDB :
CRÉER BASE DE DONNÉES bibliothèque;La sortie montre que la base de données de la bibliothèque est créée sur le serveur :
 Exécutez la commande suivante pour sélectionner la base de données sur le serveur afin d'effectuer différents types d'opérations de base de données :
Exécutez la commande suivante pour sélectionner la base de données sur le serveur afin d'effectuer différents types d'opérations de base de données :
La sortie montre que la base de données de la bibliothèque est sélectionnée :

Créer les tableaux
L'étape suivante consiste à créer les tables nécessaires à la base de données pour stocker les données. Trois tables sont créées dans cette partie du didacticiel. Il s'agit des livres, des membres et des tables d'emprunt_info.
- La table des livres stocke toutes les données relatives aux livres.
- La table des membres stocke toutes les informations sur les membres qui empruntent le livre à la bibliothèque.
- La table loan_info stocke les informations sur quel livre est emprunté par quel membre.
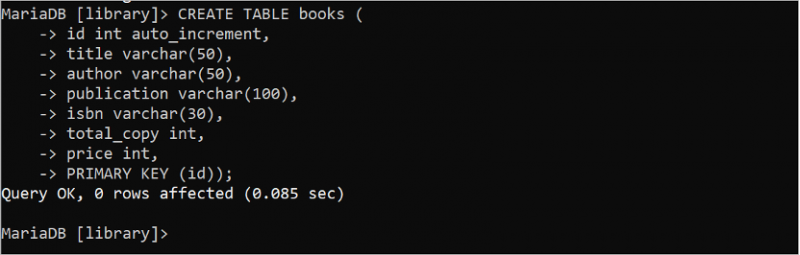
1. Livres Tableau
Exécutez l'instruction SQL suivante pour créer une table nommée 'livres' dans la base de données 'bibliothèque' qui contient sept champs et une clé primaire. Ici, le champ 'id' est la clé primaire et le type de données est int. L'attribut auto_increment est utilisé pour le champ 'id'. Ainsi, la valeur de ce champ est incrémentée automatiquement lorsqu'une nouvelle ligne est insérée. Le type de données varchar est utilisé pour stocker les données de chaîne de la longueur variable. Les champs titre, auteur, publication et isbn stockent les données de chaîne. Le type de données des champs total_copy et price est int. Ainsi, ces champs stockent les données numériques.
CRÉER TABLEAU livres (identifiant INT INCRÉMENTATION AUTOMATIQUE ,
titre VARCHAR ( cinquante ) ,
auteur VARCHAR ( cinquante ) ,
publication VARCHAR ( 100 ) ,
ISBN VARCHAR ( 30 ) ,
copie_totale INT ,
prix INT ,
PRIMAIRE CLÉ ( identifiant ) ) ;
La sortie montre que la table 'books' est créée avec succès :
2. Membres Tableau
Exécutez l'instruction SQL suivante pour créer une table nommée 'members' dans la base de données 'library' qui contient 5 champs et une clé primaire. Le champ 'id' a l'attribut auto_increment comme la table 'books'. Le type de données des autres champs est varchar. Ainsi, ces champs stockent les données de chaîne.
CRÉER TABLEAU membres (identifiant INT INCRÉMENTATION AUTOMATIQUE ,
nom VARCHAR ( cinquante ) ,
adresse VARCHAR ( 200 ) ,
contact_no VARCHAR ( quinze ) ,
e-mail VARCHAR ( cinquante ) ,
PRIMAIRE CLÉ ( identifiant ) ) ;
La sortie montre que la table « membres » est créée avec succès :

3. Emprunter_info Tableau
Exécutez l'instruction SQL suivante pour créer une table nommée 'borrow_info' dans la base de données 'library' qui contient 6 champs. Ici, le champ 'id' est la clé primaire mais l'attribut auto_increment n'est pas utilisé pour ce champ. Ainsi, une valeur unique est insérée manuellement dans ce champ lorsqu'un nouvel enregistrement est inséré dans la table. Les champs book_id et member_id sont des clés étrangères pour cette table ; ce sont la clé primaire de la table 'books' et de la table 'members'. Le type de données des champs loan_date et return_date est date. Ainsi, ces deux champs stockent la valeur de la date au format 'AAAA-MM-JJ'.
CRÉER TABLEAU info_emprunt (identifiant INT ,
date_emprunt DATE ,
book_id INT ,
ID membres INT ,
date de retour DATE ,
STATUT VARCHAR ( dix ) ,
PRIMAIRE CLÉ ( identifiant ) ,
ÉTRANGER CLÉ ( book_id ) LES RÉFÉRENCES livres ( identifiant ) ,
ÉTRANGER CLÉ ( ID membres ) LES RÉFÉRENCES membres ( identifiant ) ) ;
La sortie montre que la table 'borrow_info' est créée avec succès :

Renommer le nom de la table
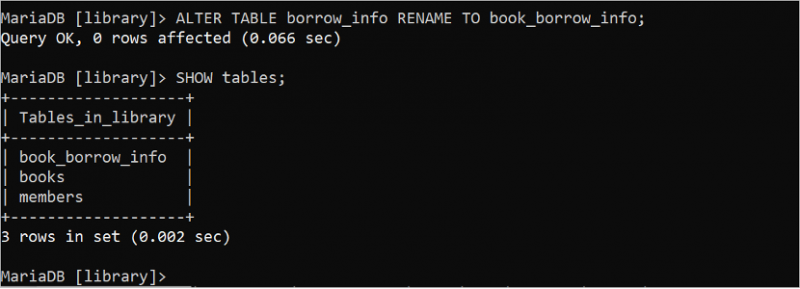
L'instruction ALTER TABLE peut être utilisée à plusieurs fins dans les instructions SQL. Exécutez l'instruction ALTER TABLE suivante pour remplacer le nom de la table « borrow_info » par « book_borrow_info ». Ensuite, l'instruction SHOW tables peut être utilisée pour vérifier si le nom de la table a été modifié ou non.
MODIFIER TABLEAU info_emprunt RENOMMER POUR book_borrow_info ;MONTRER LES TABLES ;
La sortie montre que le nom de la table a été modifié avec succès et que le nom de la table loan_info a été remplacé par book_borrow_info :
Ajouter une nouvelle colonne au tableau
L'instruction ALTER TABLE peut être utilisée pour ajouter ou supprimer une ou plusieurs colonnes après la création de la table. L'instruction ALTER TABLE suivante ajoute un nouveau champ nommé « status » aux membres de la table. L'instruction DESCRIBE est utilisée pour indiquer si la structure de la table a été modifiée ou non.
MODIFIER TABLEAU membres AJOUTER STATUT VARCHAR ( dix ) ;DÉCRIRE membres;
La sortie montre qu'une nouvelle colonne 'status' est ajoutée à la table 'members' et que le type de données de la table est varchar :

Supprimer la colonne du tableau
L'instruction ALTER TABLE suivante supprime le champ nommé 'status' de la table 'members'. L'instruction DESCRIBE est utilisée pour indiquer si la structure de la table a été modifiée ou non.
MODIFIER TABLEAU membres GOUTTE COLONNE STATUT ;DÉCRIRE membres;
La sortie montre que la colonne 'statut' est supprimée de la table 'membres' :

Insérer une seule ligne dans le tableau
L'instruction INSERT INTO est utilisée pour insérer une ou plusieurs lignes dans la table. Exécutez l'instruction SQL suivante pour insérer une seule ligne dans la table 'books'. Ici, le champ 'id' est omis de cette requête car il est inséré automatiquement dans l'enregistrement lorsqu'un nouvel enregistrement est inséré pour l'attribut d'auto-incrémentation. Si ce champ est utilisé dans l'instruction INSERT, la valeur doit être NULL.
INSÉRER DANS livres ( titre , auteur , publication , ISBN , copie_totale , prix )VALEURS ( 'SQL en 10 minutes' , 'Ben Forta' , 'Sams Publishing' , '784534235' , 5 , 39 ) ;
La sortie montre qu'un enregistrement a été ajouté avec succès à la table 'books' :

Les données peuvent être insérées dans la table à l'aide de la clause SET où chaque valeur de champ est affectée séparément. Exécutez l'instruction SQL suivante pour insérer une seule ligne dans la table « membres » à l'aide des clauses INSERT INTO et SET. Le champ 'id' est également omis dans cette requête comme dans l'exemple précédent pour la même raison.
INSÉRER DANS membresENSEMBLE nom = 'John Sina' , adresse = '34, Dhanmondi 9/A, Dacca' , contact_no = '+14844731336' , e-mail = 'john@gmail.com' ;
La sortie montre qu'un enregistrement a été ajouté avec succès à la table des membres :

Exécutez l'instruction SQL suivante pour insérer une seule ligne dans la table 'book_borrow_info' :
INSÉRER DANS book_borrow_info ( identifiant , date_emprunt , book_id , ID membres , date de retour , STATUT )VALEURS ( 1 , '2023-03-12' , 1 , 1 , '2023-03-19' , 'Emprunté' ) ;
La sortie montre qu'un enregistrement est ajouté à la table 'book_borrow_info':

Insérer plusieurs lignes dans le tableau
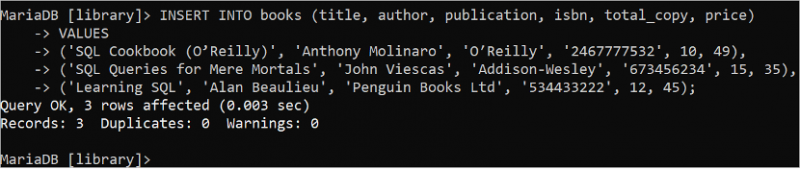
Parfois, cela nécessite d'ajouter plusieurs enregistrements à la fois à l'aide d'une seule instruction INSERT INTO. Exécutez l'instruction SQL suivante pour insérer trois enregistrements dans la table 'books' à l'aide d'une seule instruction INSERT INTO. Dans ce cas, la clause VALUES est utilisée une seule fois et les données de chaque enregistrement sont séparées par une virgule.
INSÉRER DANS livres ( titre , auteur , publication , ISBN , copie_totale , prix )VALEURS
( 'Livre de recettes SQL (O'Reilly)' , 'Anthony Molinaro' , 'O'Reilly' , '2467777532' , dix , 49 ) ,
( 'Requêtes SQL pour les simples mortels' , 'Jean Viescas' , 'Addison-Wesley' , '673456234' , quinze , 35 ) ,
( 'Apprendre SQL' , 'Alan Beaulieu' , 'Penguin Books Ltd' , '534433222' , 12 , Quatre cinq ) ;
La sortie montre que trois enregistrements sont ajoutés à la table 'books' :
Lire tous les champs particuliers du tableau
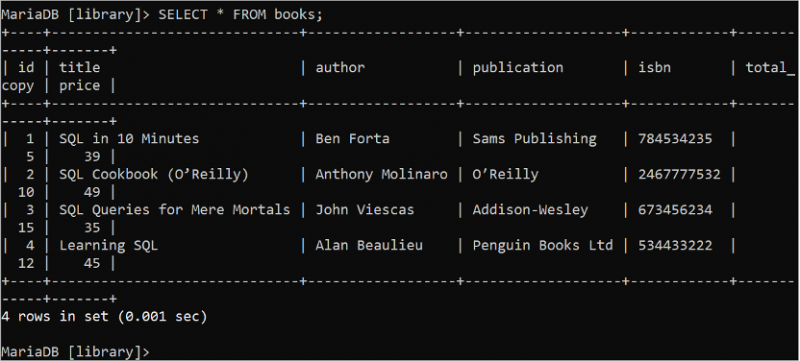
L'instruction SELECT est utilisée pour lire les données de la table 'base de données'. Le symbole '*' est utilisé pour désigner tous les champs de la table dans l'instruction SELECT. Exécutez la commande SQL suivante pour lire tous les enregistrements de la table des livres :
SÉLECTIONNER * DEPUIS livres;La sortie affiche tous les enregistrements de la table livres qui contient 4 enregistrements :
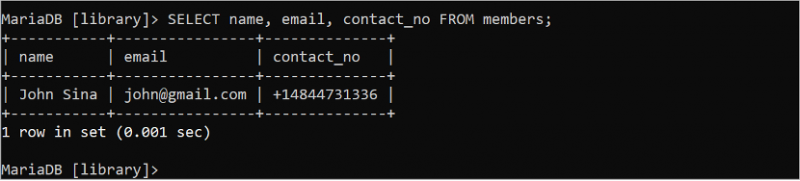
Exécutez la commande SQL suivante pour lire tous les enregistrements de trois champs de la table « membres » :
SÉLECTIONNER nom , e-mail , contact_no DEPUIS membres;La sortie affiche tous les enregistrements de trois champs de la table « membres » :
Lire le tableau après avoir filtré les données du tableau
La clause WHERE est utilisée pour lire les données d'une table en fonction d'une ou plusieurs conditions. Exécutez l'instruction SELECT suivante pour lire tous les enregistrements de tous les champs de la table 'livres' où le nom de l'auteur est 'John Viescas'.
SÉLECTIONNER * DEPUIS livres OÙ auteur = 'Jean Viescas' ;La table 'books' contient un enregistrement qui correspond à la condition de la clause WHERE affichée dans la sortie :

Lire le tableau après avoir filtré les données en fonction de la logique booléenne
La logique booléenne AND est utilisée pour définir plusieurs conditions dans la clause WHERE qui renvoie true si toutes les conditions renvoient true. Exécutez l'instruction SELECT suivante pour lire tous les enregistrements de tous les champs de la table 'books' où la valeur du champ total_copy est supérieure à 10 et la valeur du champ price est inférieure à 45 en utilisant le AND logique.
SÉLECTIONNER * DEPUIS livres OÙ copie_totale > dix ET prix < Quatre cinq ;La table des livres contient un enregistrement qui correspond à la condition de la clause WHERE affichée dans la sortie :

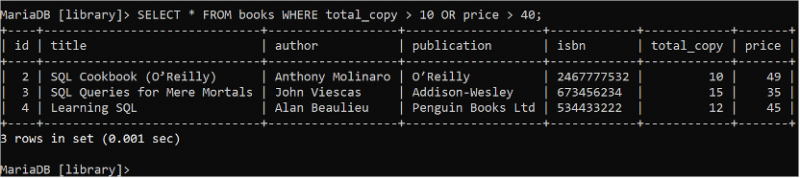
La logique booléenne OR est utilisée pour définir plusieurs conditions dans la clause WHERE qui renvoie true si l'une des conditions renvoie true. Exécutez l'instruction SELECT suivante pour lire tous les enregistrements de tous les champs de la table 'books' où la valeur du champ total_copy est supérieure à 10 ou la valeur du champ price est supérieure à 40.
SÉLECTIONNER * DEPUIS livres OÙ copie_totale > dix OU prix > 40 ;La table des livres contient trois enregistrements qui correspondent à la condition de la clause WHERE affichée dans la sortie :
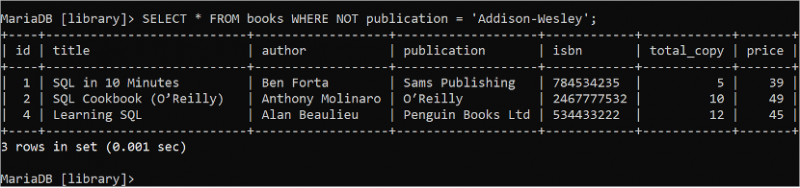
La logique booléenne NOT est utilisée pour renvoyer false lorsque la condition est vraie et renvoie true lorsque la condition est fausse. Exécutez l'instruction SELECT suivante pour lire tous les enregistrements de tous les champs de la table 'livres' où la valeur du champ auteur n'est pas 'Addison-Wesley'.
SÉLECTIONNER * DEPUIS livres OÙ PAS auteur = 'Addison-Wesley' ;La table 'books' contient trois enregistrements qui correspondent à la condition de la clause WHERE affichée dans la sortie :
Lire le tableau après avoir filtré les lignes en fonction de la plage de données
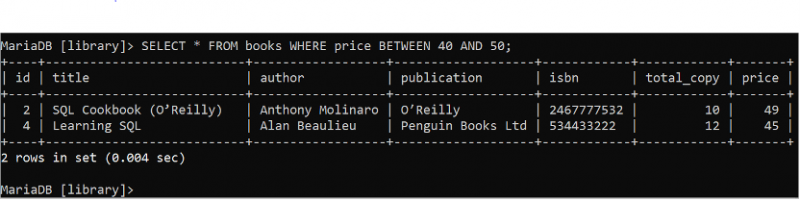
La clause BETWEEN est utilisée pour lire la plage de données de la table de base de données. Exécutez l'instruction SELECT suivante pour lire tous les enregistrements de tous les champs de la table 'livres' où la valeur du champ prix est comprise entre 40 et 50.
SÉLECTIONNER * DEPUIS livres OÙ prix ENTRE 40 ET cinquante ;La table des livres contient deux enregistrements qui correspondent à la condition de la clause WHERE affichée dans la sortie. Les livres des valeurs de prix, 39 et 35, sont omis du jeu de résultats car ils sont hors plage.
Lire le tableau après avoir trié le tableau
La clause ORDER BY est utilisée pour trier le jeu de résultats de l'instruction SELECT dans l'ordre croissant ou décroissant. Le jeu de résultats est trié dans l'ordre croissant par défaut si la clause ORDER BY est utilisée sans ASC ou DESC. L'instruction SELECT suivante lit les enregistrements triés de la table des livres en fonction du champ de titre :
SÉLECTIONNER * DEPUIS livres COMMANDE PAR titre;Les données du champ titre de la table « livres » sont triées par ordre croissant dans la sortie. Le livre 'Learning SQL' vient en premier par ordre alphabétique si le champ titre de la table 'livres' est trié par ordre croissant.
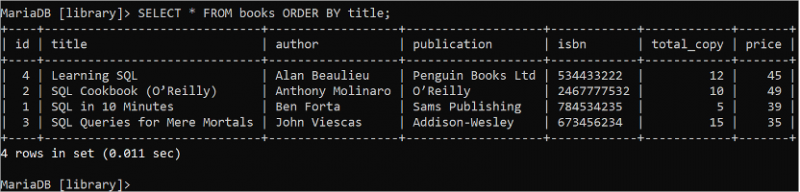
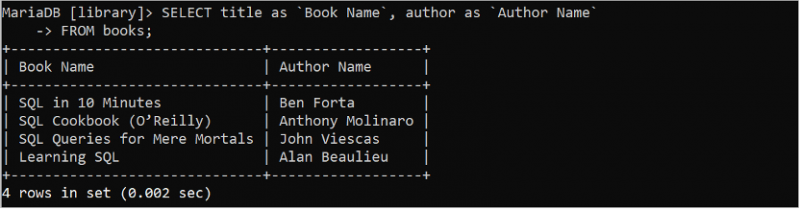
Lire le tableau en définissant le nom alternatif de la colonne
Le nom alternatif de la colonne est utilisé dans la requête pour rendre le jeu de résultats plus lisible. Le nom alternatif est défini à l'aide du mot-clé 'AS'. L'instruction SQL suivante renvoie les valeurs des champs titre et auteur en définissant les noms alternatifs.
SÉLECTIONNER titre COMME `Nom du livre` , auteur COMME `Nom de l'auteur`DEPUIS livres;
Le champ de titre est affiché avec le nom alternatif qui est 'Nom du livre' et le champ d'auteur est affiché avec le nom alternatif qui est 'Nom de l'auteur' dans la sortie.
Compter le nombre total de lignes dans le tableau
Le COUNT () est une fonction d'agrégation de SQL qui est utilisée pour compter le nombre total de lignes en fonction du champ particulier ou de tous les champs. Le symbole '*' est utilisé pour désigner tous les champs et le COUNT(*) est utilisé pour compter tous les enregistrements de la table.
La requête suivante compte le nombre total d'enregistrements de la table des livres :
SÉLECTIONNER COMPTER ( * ) COMME `Nombre total de livres` DEPUIS livres;Quatre enregistrements de la table 'books' sont affichés dans la sortie :

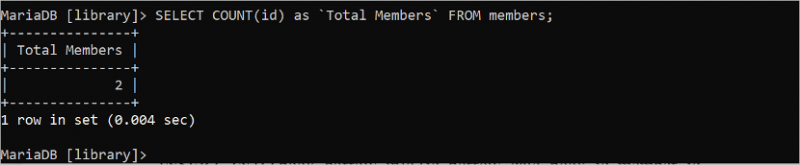
La requête suivante compte le nombre total de lignes de la table « members » en fonction du champ « id » :
SÉLECTIONNER COMPTER ( identifiant ) COMME `Nombre total de membres` DEPUIS membres;La table « membres » a deux valeurs d'identifiant qui sont imprimées dans la sortie :
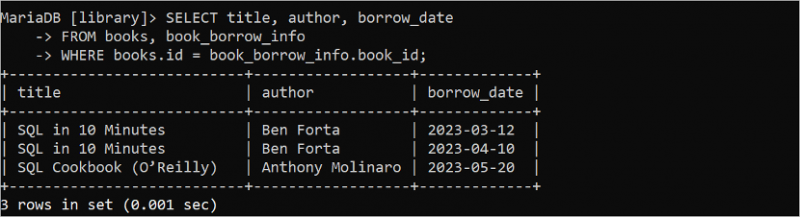
Lire les données de plusieurs tables
Les instructions SELECT précédentes récupéraient les données d'une seule table. Mais l'instruction SELECT peut être utilisée pour récupérer les données de deux tables ou plus. La requête SELECT suivante lit les valeurs des champs titre et auteur de la table « livres » et la date d'emprunt de la table « book_borrow_info ».
SÉLECTIONNER titre , auteur , date_empruntDEPUIS livres , book_borrow_info
OÙ livres . identifiant = book_borrow_info . book_id ;
La sortie suivante montre que le livre 'SQL in 10 Minutes' est emprunté deux fois et que le livre 'SQL Cookbook (O'Reilly)' est emprunté une fois :
Les données peuvent être récupérées à partir de plusieurs tables en utilisant différents types de JOINS tels que INNER JOIN, OUTER JOIN, etc. qui ne sont pas expliqués dans ce tutoriel.
Lire le tableau en regroupant les champs particuliers
La clause GROUP BY est utilisée pour lire les enregistrements de la table en regroupant les lignes en fonction d'un ou plusieurs champs. Ce type de requête est appelé requête récapitulative. Vous devez insérer plusieurs lignes dans les tables pour vérifier l'utilisation de la clause GROUP BY. Exécutez les instructions INSERT suivantes pour insérer un enregistrement dans la table 'members' et deux enregistrements dans la table 'book_borrow_info'.
INSÉRER DANS membresENSEMBLE nom = 'Elle Hasan' , adresse = '11/A, Jigatola, Dacca' , contact_no = '+8801734563423' , e-mail = 'elle@gmail.com' ;
INSÉRER DANS book_borrow_info ( identifiant , date_emprunt , book_id , ID membres , date de retour , STATUT )
VALEURS ( 2 , '2023-04-10' , 1 , 1 , '2023-04-15' , 'Revenu' ) ;
INSÉRER DANS book_borrow_info ( identifiant , date_emprunt , book_id , ID membres , date de retour , STATUT )
VALEURS ( 3 , '2023-05-20' , 2 , 1 , '2023-05-30' , 'Emprunté' ) ;
Après avoir inséré les données en exécutant les requêtes précédentes, exécutez l'instruction SELECT suivante qui compte le nombre total de livres empruntés et le nom du membre en fonction de chaque membre à l'aide de la clause GROUP BY. Ici, la fonction COUNT() travaille sur le champ qui sert à regrouper les enregistrements à l'aide de la clause GROUP BY. Le champ book_id de la table « membres » est utilisé pour le regroupement ici.
SÉLECTIONNER COMPTER ( book_id ) COMME `Total de livres empruntés` , nom COMME `Nom du membre` DEPUIS livres , membres , book_borrow_info OÙ livres . identifiant = book_borrow_info . book_id ET membres . identifiant = book_borrow_info . ID membres GROUPE PAR book_borrow_info . ID membres;Selon les données des livres, des tables « membres » et « livre_emprunt_info », « John Sina » a emprunté 2 livres et « Ella Hasan » a emprunté 1 livre.

Lire le tableau après avoir omis les valeurs en double
Parfois, des données en double sont générées dans le jeu de résultats de l'instruction SELECT en fonction des données de table qui ne sont pas nécessaires. Par exemple, l'instruction SELECT suivante renvoie les enregistrements en double pour les données de la table 'book_borrow_info'.
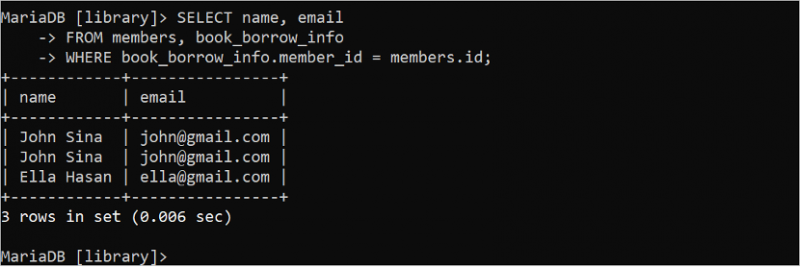
SÉLECTIONNER nom , e-mailDEPUIS membres , book_borrow_info
OÙ book_borrow_info . ID membres = membres . identifiant;
Dans la sortie, le même enregistrement apparaît deux fois car le membre « John Sina » a emprunté deux livres. Ce problème peut être résolu à l'aide du mot-clé DISTINCT. Il supprime les enregistrements en double du résultat de la requête.
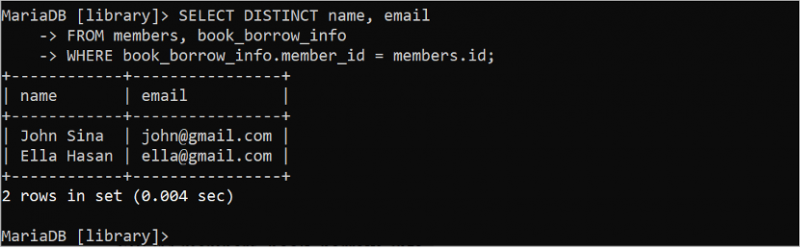
L'instruction SELECT suivante génère des enregistrements uniques du jeu de résultats à partir des tables « members » et « book_borrow_info » après avoir omis les valeurs en double à l'aide du mot-clé DISTINCT dans la requête.
SÉLECTIONNER DISTINCT nom , e-mailDEPUIS membres , book_borrow_info
OÙ book_borrow_info . ID membres = membres . identifiant;
La sortie montre que la valeur en double est supprimée du jeu de résultats :
Lire le tableau en limitant le nombre de lignes
Parfois, cela nécessite de lire le nombre particulier d'enregistrements depuis le début du jeu de résultats, la fin du jeu de résultats ou le milieu du jeu de résultats à partir de la table de base de données en limitant le nombre de lignes. Cela peut être fait de plusieurs façons. Avant de limiter les lignes, exécutez l'instruction SQL suivante pour vérifier le nombre d'enregistrements existant dans la table des livres :
SÉLECTIONNER * DEPUIS livres;Le résultat montre que la table des livres contient quatre enregistrements :

L'instruction SELECT suivante lit les deux premiers enregistrements de la table 'books' à l'aide de la clause LIMIT avec la valeur 2 :
SÉLECTIONNER * DEPUIS livres LIMITE 2 ;Les deux premiers enregistrements de la table 'books' sont récupérés et affichés dans la sortie :

La clause FETCH est l'alternative de la clause LIMIT et son utilisation est illustrée dans l'instruction SELECT suivante. Les 3 premiers enregistrements de la table 'books' sont récupérés à l'aide de la clause FETCH FIRST 3 ROWS ONLY dans l'instruction SELECT :
SÉLECTIONNER * DEPUIS livres FETCH D'ABORD 3 LIGNES SEUL ;La sortie affiche les 3 premiers enregistrements de la table « livres » :

Deux disques du 3 rd ligne de la table des livres sont extraites en exécutant l'instruction SELECT suivante. La clause LIMIT est utilisée ici avec la valeur 2, 2 où le premier 2 définit la position de départ de la ligne de la table qui commence à compter à partir de 0 et le second 2 définit le nombre de lignes qui commence à compter à partir de la position de départ.
SÉLECTIONNER * DEPUIS livres LIMITE 2 , 2 ;Le résultat suivant s'affiche après l'exécution de la requête précédente :

Les enregistrements à partir de la fin de la table peuvent être lus en triant la table par ordre décroissant en fonction de la valeur de clé primaire auto-incrémentée et en utilisant la clause LIMIT. Exécutez l'instruction SELECT suivante qui lit les 2 derniers enregistrements de la table 'books'. Ici, le jeu de résultats est trié par ordre décroissant en fonction du champ 'id'.
SÉLECTIONNER * DEPUIS livres COMMANDE PAR identifiant DESC LIMITE 2 ;Les deux derniers enregistrements de la table des livres sont affichés dans la sortie suivante :

Lire le tableau basé sur la correspondance partielle
La clause LIKE est utilisée avec le symbole '%' pour récupérer les enregistrements de la table par correspondance partielle. L'instruction SELECT suivante recherche les enregistrements de la table 'livres' où le champ auteur contient 'John' au début de la valeur à l'aide de la clause LIKE. Ici, le symbole '%' est utilisé à la fin de la chaîne de recherche.
SÉLECTIONNER * DEPUIS livres OÙ auteur COMME 'John%' ;Un seul enregistrement existe dans la table 'livres' qui contient la chaîne 'John' au début de la valeur du champ auteur.

L'instruction SELECT suivante recherche les enregistrements de la table « livres » où le champ de publication contient le « Ltd » à la fin de la valeur à l'aide de la clause LIKE. Ici, le symbole '%' est utilisé au début de la chaîne de recherche :
SÉLECTIONNER * DEPUIS livres OÙ publication COMME '% Ltd' ;Un seul enregistrement existe dans la table « livres » qui contient la chaîne « Ltd » à la fin du champ de publication.

L'instruction SELECT suivante recherche les enregistrements de la table « livres » où le champ de titre contient les « Requêtes » n'importe où sur la valeur à l'aide de la clause LIKE. Ici, le symbole '%' est utilisé des deux côtés de la chaîne de recherche :
SÉLECTIONNER * DEPUIS livres OÙ titre COMME '%Requêtes%' ;Un seul enregistrement existe dans la table « livres » qui contient la chaîne « Requêtes » dans le champ de titre.

Compter la somme du champ particulier de la table
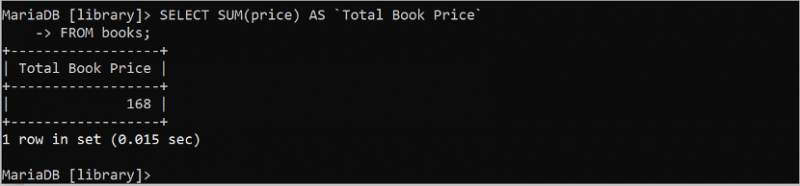
Le SUM () est une autre fonction d'agrégation utile de SQL qui calcule la somme des valeurs de n'importe quel champ numérique de la table. Cette fonction prend un argument qui doit être numérique. L'instruction SQL suivante calcule la somme de toutes les valeurs du champ de prix de la table 'livres' qui contient des valeurs entières.
SÉLECTIONNER SOMME ( prix ) COMME `Prix total du livre`DEPUIS livres;
La sortie affiche la valeur de somme de toutes les valeurs du champ de prix de la table 'livres'. Les quatre valeurs du champ prix sont 39, 49, 35 et 45. La somme de ces valeurs est 168.
Trouver les valeurs maximales et minimales du champ particulier
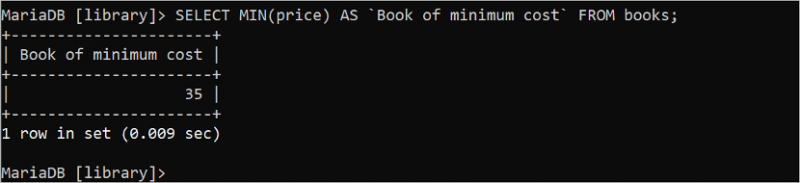
Les fonctions d'agrégation MIN() et MAX() sont utilisées pour connaître les valeurs minimales et maximales du champ particulier de la table. Les deux fonctions prennent un argument qui doit être numérique. L'instruction SQL suivante trouve la valeur du prix minimum à partir de la table 'livres' qui est un entier.
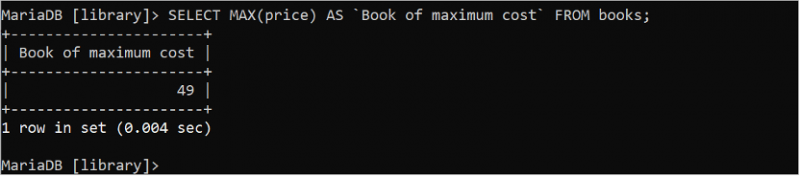
SÉLECTIONNER MIN ( prix ) COMME `Livre de coût minimum` DEPUIS livres;Trente-cinq (35) est la valeur minimale du champ de prix imprimé dans la sortie.
L'instruction SQL suivante trouve la valeur maximale du prix à partir de la table 'books' :
SÉLECTIONNER MAX ( prix ) COMME `Livre de coût maximum` DEPUIS livres;Quarante-neuf (49) est la valeur maximale du champ de prix imprimé dans la sortie.
Lire la partie particulière des données ou un champ
La fonction SUBSTR() est utilisée dans l'instruction SQL pour récupérer la partie particulière des données de chaîne ou la valeur du champ particulier d'une table. Cette fonction contient trois arguments. Le premier argument contient la valeur de chaîne ou une valeur de champ d'une table qui est une chaîne. Le deuxième argument contient la position de départ de la sous-chaîne extraite du premier argument et le comptage de cette valeur commence à partir de 1. Le troisième argument contient la longueur de la sous-chaîne qui commence à compter à partir de la position de départ.
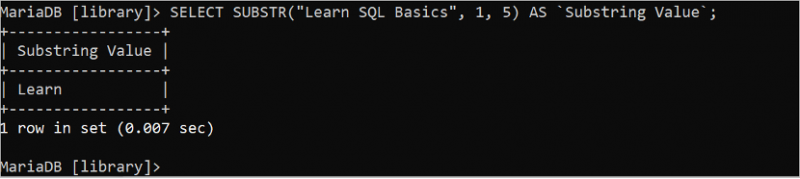
L'instruction SELECT suivante coupe et imprime les cinq premiers caractères de la chaîne 'Learn SQL Basics' où la position de départ est 1 et la longueur est 5 :
SÉLECTIONNER SUBSTR ( 'Apprendre les bases de SQL' , 1 , 5 ) COMME `Valeur de sous-chaîne` ;Les cinq premiers caractères de la chaîne 'Learn SQL Basics' sont 'Learn' qui est imprimé dans la sortie.
L'instruction SELECT suivante coupe et imprime le SQL à partir de la chaîne 'Learn SQL Basics' où la position de départ est 7 et la longueur est 3 :
SÉLECTIONNER SUBSTR ( 'Apprendre les bases de SQL' , 7 , 3 ) COMME `Valeur de sous-chaîne` ;Le résultat suivant s'affiche après l'exécution de la requête précédente :

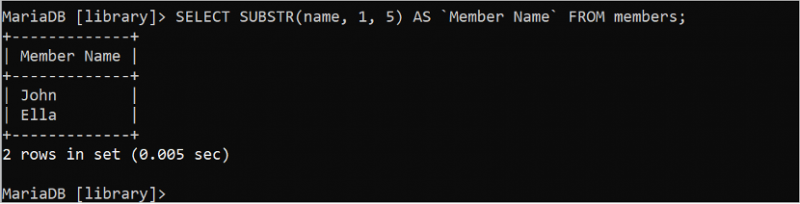
L'instruction SELECT suivante coupe et imprime les cinq premiers caractères du champ de nom de la table « membres » :
SÉLECTIONNER SUBSTR ( nom , 1 , 5 ) COMME `Nom du membre` DEPUIS membres;La sortie affiche les cinq premiers caractères de chaque valeur du champ de nom de la table « membres ».
Lire les données de la table après la concaténation
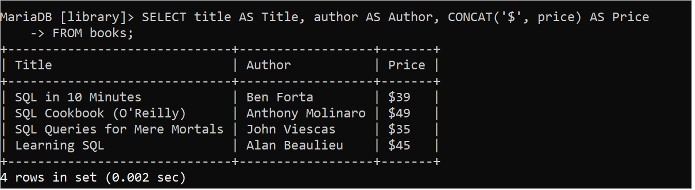
La fonction CONCAT() est utilisée pour générer la sortie en combinant un ou plusieurs champs d'une table ou en ajoutant les données de chaîne ou la valeur de champ particulière de la table. L'instruction SQL suivante lit les valeurs des champs titre, auteur et prix de la table 'livres', et la valeur de chaîne '$' est ajoutée à chaque valeur du champ prix à l'aide de la fonction CONCAT().
SÉLECTIONNER titre COMME Titre , auteur COMME Auteur , CONCAT ( '$' , prix ) COMME PrixDEPUIS livres;
Les valeurs du champ de prix sont imprimées dans la sortie en concaténant avec la chaîne « $ ».
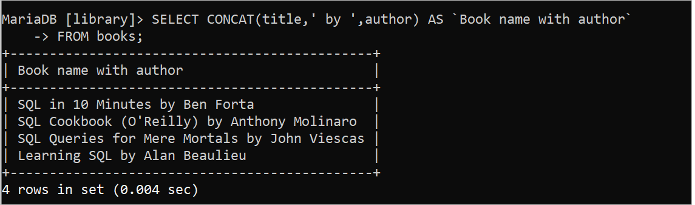
Exécutez l'instruction SQL suivante pour combiner les valeurs des champs titre et auteur de la table « livres » avec la valeur de chaîne « by » à l'aide de la fonction CONCAT() :
SÉLECTIONNER CONCAT ( titre , ' par ' , auteur ) COMME `Nom du livre avec auteur`DEPUIS livres;
La sortie suivante apparaît après l'exécution de la requête SELECT précédente :
Lire les données du tableau après un calcul mathématique
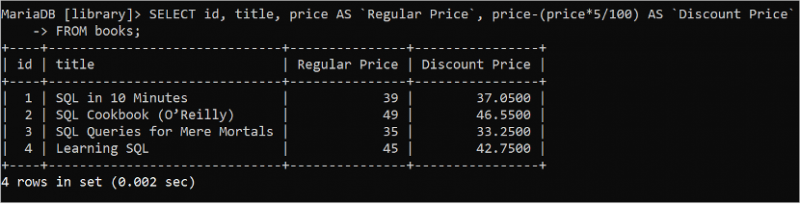
Tout calcul mathématique peut être effectué au moment de la récupération des valeurs de la table à l'aide d'une instruction SELECT. Exécutez l'instruction SQL suivante pour lire l'ID, le titre, le prix et la valeur du prix réduit après avoir calculé la remise de 5 %.
SÉLECTIONNER identifiant , titre , prix COMME `Prix normal` , prix - ( prix * 5 / 100 ) COMME `Prix réduit`DEPUIS livres;
Le résultat suivant indique le prix normal et le prix réduit de chaque livre :
Créer une vue du tableau
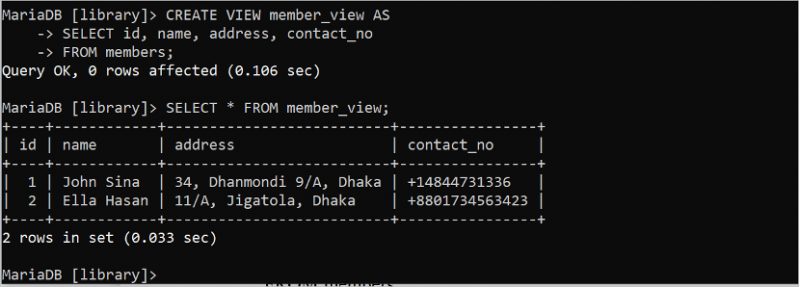
La VUE est utilisée pour simplifier la requête et fournit une sécurité supplémentaire à la base de données. Il fonctionne comme une table virtuelle générée à partir d'une ou plusieurs tables. La méthode de création et d'exécution d'une VUE simple basée sur la table « membres » est illustrée dans l'exemple suivant. La VUE est exécutée à l'aide de l'instruction SELECT. L'instruction SQL suivante crée une VIEW de la table « members » avec les champs id, name, address et contact_no. L'instruction SELECT exécute la vue_membre.
CRÉER VOIR vue_membre COMMESÉLECTIONNER identifiant , nom , adresse , contact_no
DEPUIS membres;
SÉLECTIONNER * DEPUIS vue_membre ;
La sortie suivante apparaît après la création et l'exécution de la vue :
Mettre à jour le tableau en fonction de la condition particulière
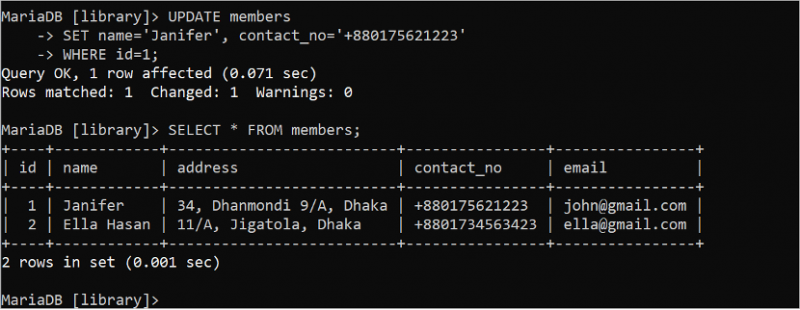
L'instruction UPDATE est utilisée pour mettre à jour le contenu de la table. Si une requête UPDATE est exécutée sans la clause WHERE, tous les champs utilisés dans la requête UPDATE sont mis à jour. Il est donc nécessaire d'utiliser une instruction UPDATE avec la clause WHERE appropriée. Exécutez l'instruction UPDATE suivante pour mettre à jour les champs name et contact_no où la valeur du champ id est 1. Ensuite, exécutez l'instruction SELECT pour vérifier si les données sont mises à jour correctement ou non.
MISE À JOUR membresENSEMBLE nom = 'Janifère' , contact_no = '+880175621223'
OÙ identifiant = 1 ;
SÉLECTIONNER * DEPUIS membres;
La sortie suivante montre que l'instruction UPDATE est exécutée avec succès. La valeur du champ name est changée en 'Janifer' et le champ contact_no est changé en '+880175621223' de l'enregistrement qui contient la valeur id de 1 en utilisant la requête UPDATE :
Supprimer les données du tableau en fonction de la condition particulière
L'instruction DELETE est utilisée pour supprimer le contenu spécifique ou tout le contenu de la table. Si une requête DELETE est exécutée sans la clause WHERE, tous les champs sont supprimés. Il est donc nécessaire d'utiliser l'instruction UPDATE avec la clause WHERE appropriée. Exécutez l'instruction DELETE suivante pour supprimer toutes les données de la table des livres où la valeur id est 4. Ensuite, exécutez l'instruction SELECT pour vérifier si les données sont supprimées correctement ou non.
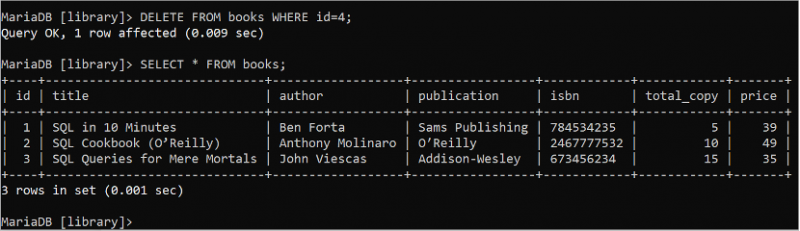
SUPPRIMER DEPUIS livres OÙ identifiant = 4 ;SÉLECTIONNER * DEPUIS livres;
La sortie suivante montre que l'instruction DELETE est exécutée avec succès. Le 4 e l'enregistrement de la table des livres est supprimé à l'aide de la requête DELETE :
Supprimer tous les enregistrements de la table
Exécutez l'instruction DELETE suivante pour supprimer tous les enregistrements de la table 'books' où la clause WHERE est omise. Ensuite, exécutez la requête SELECT pour vérifier le contenu de la table.
SUPPRIMER DEPUIS book_borrow_info ;SÉLECTIONNER * DEPUIS book_borrow_info ;
La sortie suivante montre que la table 'books' est vide après l'exécution de la requête DELETE :

Si une table contient un attribut d'auto-incrémentation et que tous les enregistrements sont supprimés de la table, le champ d'auto-incrémentation commence à compter à partir du dernier incrément lorsqu'un nouvel enregistrement est inséré après avoir vidé la table. Ce problème peut être résolu à l'aide de l'instruction TRUNCATE. Il est également utilisé pour supprimer tous les enregistrements de la table, mais le champ d'auto-incrémentation commence à compter à partir de 1 après la suppression de tous les enregistrements de la table. Le SQL de l'instruction TRUNCATE est illustré ci-dessous :
TRONQUER book_borrow_info ;Laisser tomber le tableau
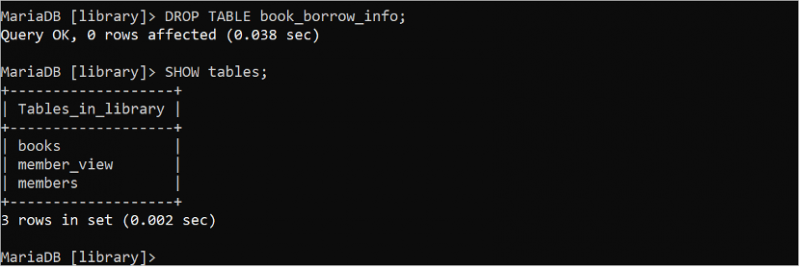
Une ou plusieurs tables peuvent être supprimées en vérifiant ou sans vérifier si la table existe ou non. Les instructions DROP suivantes suppriment la table 'book_borrow_info' et l'instruction 'SHOW tables' vérifie si la table existe ou non sur le serveur.
GOUTTE TABLEAU book_borrow_info ;MONTRER LES TABLES ;
La sortie montre que la table 'book_borrow_info' est supprimée.
La table peut être supprimée après avoir vérifié si elle existe ou non sur le serveur. Exécutez l'instruction DROP suivante pour supprimer la table des livres et des membres si ces tables existent sur le serveur. Ensuite, l'instruction 'SHOW tables' vérifie si les tables existent ou non sur le serveur.
GOUTTE TABLEAU SI EXISTE livres , membres;MONTRER LES TABLES ;
Le résultat suivant montre que les tables sont supprimées du serveur :

Déposez la base de données
Exécutez l'instruction SQL suivante pour supprimer la base de données 'library' du serveur :
GOUTTE BASE DE DONNÉES bibliothèque;La sortie montre que la base de données est supprimée.

Conclusion
Les exemples de requête SQL les plus utilisés pour créer, accéder, modifier et supprimer la base de données du serveur MariaDB sont présentés dans ce didacticiel en créant une base de données et trois tables. Les utilisations des différentes instructions SQL sont expliquées avec des exemples très simples pour aider le nouvel utilisateur de la base de données à apprendre correctement les bases de SQL. Les utilisations des requêtes complexes sont omises ici. Les nouveaux utilisateurs de la base de données pourront commencer à travailler avec n'importe quelle base de données après avoir lu correctement ce didacticiel.