6.1 Introduction
Les ordinateurs modernes à usage général sont de deux types : CISC et RISC. CISC signifie Ordinateur à jeu d'instructions complexe. RISK signifie Ordinateur à jeu d'instructions réduit. Les microprocesseurs 6502 ou 6510, applicables à l'ordinateur Commodore-64, ressemblent davantage à l'architecture RISC qu'à une architecture CISC.
Les ordinateurs RISC ont généralement des instructions en langage assembleur plus courtes (en nombre d'octets) par rapport aux ordinateurs CISC.
Note : Qu'il s'agisse d'un CISC, RISC ou d'un ancien ordinateur, un périphérique part d'un port interne et va vers l'extérieur via un port externe sur la surface verticale de l'unité système de l'ordinateur (unité de base) et vers le périphérique externe.
Une instruction typique d'un ordinateur CISC peut être considérée comme la réunion de plusieurs instructions courtes en langage assembleur en une seule instruction en langage assembleur plus longue, ce qui rend l'instruction résultante complexe. En particulier, un ordinateur CISC charge les opérandes de la mémoire dans les registres du microprocesseur, effectue une opération, puis stocke le résultat dans la mémoire, le tout dans une seule instruction. En revanche, cela représente au moins trois instructions (courtes) pour l'ordinateur RISC.
Il existe deux séries populaires d'ordinateurs CISC : les ordinateurs à microprocesseur Intel et les ordinateurs à microprocesseur AMD. AMD signifie Advanced Micro Devices ; c'est une entreprise de fabrication de semi-conducteurs. Les séries de microprocesseurs Intel, par ordre de développement, sont les suivantes : 8086, 8088, 80186, 80286, 80386, 80486, Pentium, Core, i Series, Celeron et Xeon. Les instructions en langage assembleur pour les premiers microprocesseurs Intel tels que 8086 et 8088 ne sont pas très complexes. Elles sont cependant complexes pour les nouveaux microprocesseurs. Les microprocesseurs AMD récents de la série CISC sont Ryzen, Opteron, Athlon, Turion, Phenom et Sempron. Les microprocesseurs Intel et AMD sont appelés microprocesseurs x86.
ARM signifie Advanced RISC Machine. Les architectures ARM définissent une famille de processeurs RISC adaptés à une utilisation dans une grande variété d'applications. Alors que de nombreux microprocesseurs Intel et AMD sont utilisés dans les ordinateurs personnels de bureau, de nombreux processeurs ARM servent de processeurs intégrés dans des systèmes critiques pour la sécurité tels que les freins antiblocage automobiles et de processeurs à usage général dans les montres intelligentes, les téléphones portables, les tablettes et les ordinateurs portables. . Bien que les deux types de microprocesseurs puissent être observés dans les petits et les grands appareils, les microprocesseurs RISC se retrouvent davantage dans les petits appareils que dans les grands appareils.
Mot informatique
Si on dit qu'un ordinateur est un ordinateur de 32 bits, cela signifie que les informations sont stockées, transférées et manipulées sous la forme de codes binaires de trente-deux bits dans la partie interne de la carte mère. Cela signifie également que les registres à usage général du microprocesseur de l'ordinateur ont une largeur de 32 bits. Les registres A, X et Y du microprocesseur 6502 sont des registres à usage général. Ils ont une largeur de huit bits et l'ordinateur Commodore-64 est donc un ordinateur de mots de huit bits.
Un peu de vocabulaire
Ordinateurs X86
La signification des termes octet, mot, double mot, quadword et double quadword est la suivante pour les ordinateurs x86 :
- Octet : 8 bits
- Mot : 16 bits
- Mot double : 32 bits
- Quadword : 64 bits
- Double quadruple mot : 128 bits
Ordinateurs ARM
Les significations des octets, demi-mots, mots et mots doubles sont les suivantes pour les ordinateurs ARM :
- Octet : 8 bits
- Devenez la moitié : 16 bits
- Mot : 32 bits
- Mot double : 64 bits
Les différences et similitudes entre les noms (et valeurs) x86 et ARM doivent être notées.
Note : Les entiers de signe dans les deux types d’ordinateurs sont complémentaires à deux.
Emplacement mémoire
Avec l'ordinateur Commodore-64, un emplacement mémoire est généralement d'un octet mais peut parfois être de deux octets consécutifs en considérant les pointeurs (adressage indirect). Avec un ordinateur x86 moderne, un emplacement mémoire est de 16 octets consécutifs lorsqu'il s'agit d'un double quadword de 16 octets (128 bits), de 8 octets consécutifs lorsqu'il s'agit d'un quadword de 8 octets (64 bits), de 4 octets consécutifs lorsqu'il s'agit d'un double mot de 4 octets (32 bits), 2 octets consécutifs lorsqu'il s'agit d'un mot de 2 octets (16 bits), et 1 octet lorsqu'il s'agit d'un octet (8 bits). Avec un ordinateur ARM moderne, un emplacement mémoire est de 8 octets consécutifs lorsqu'il s'agit d'un double mot de 8 octets (64 bits), 4 octets consécutifs lorsqu'il s'agit d'un mot de 4 octets (32 bits), 2 octets consécutifs lorsqu'il s'agit d'un demi-mot de 2 octets (16 bits), et 1 octet lorsqu'il s'agit d'un octet (8 bits).
Ce chapitre explique ce qui est commun aux architectures CISC et RISC et quelles sont leurs différences. Ceci est fait en comparaison avec le 6502 µP et l'ordinateur Commodore-64 là où cela est applicable.
6.2 Schéma fonctionnel de la carte mère d'un PC moderne
PC signifie ordinateur personnel. Ce qui suit est un schéma fonctionnel de base générique pour une carte mère moderne avec un seul microprocesseur pour un ordinateur personnel. Il représente une carte mère CISC ou RISC.
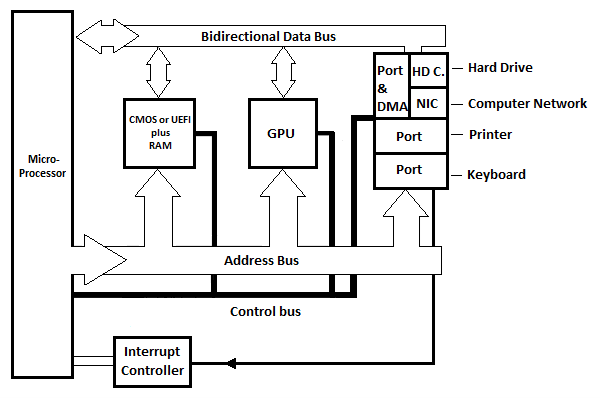
Fig. 6.21 Schéma fonctionnel de base de la carte mère d'un PC moderne
Trois ports internes sont représentés dans le schéma, mais il y en a davantage dans la pratique. Chaque port possède un registre qui peut être considéré comme le port lui-même. Chaque circuit portuaire comporte au moins un autre registre que l'on peut appeler « registre d'état ». Le registre d'état indique le port du programme qui envoie le signal d'interruption au microprocesseur. Il existe un circuit contrôleur d'interruption (non représenté) qui différencie les différentes lignes d'interruption des différents ports et ne comporte que quelques lignes vers le µP.
HD.C dans le diagramme signifie Hard Drive Card. NIC signifie Carte d'Interface Réseau. La carte de disque dur (circuit) est connectée au disque dur qui se trouve à l’intérieur de l’unité de base (unité système) de l’ordinateur moderne. La carte d'interface réseau (circuit) est connectée via un câble externe à un autre ordinateur. Dans le schéma, il y a un port et un DMA (reportez-vous à l'illustration suivante) qui sont connectés à la carte de disque dur et/ou à la carte d'interface réseau. Le DMA signifie Direct Memory Access.
Rappelez-vous du chapitre sur l'ordinateur Commodore-64 que pour envoyer les octets de la mémoire vers le lecteur de disque ou un autre ordinateur, chaque octet doit être copié dans un registre du microprocesseur avant d'être copié sur le port interne correspondant, puis automatiquement à l'appareil. Afin de recevoir les octets du lecteur de disque ou d'un autre ordinateur vers la mémoire, chaque octet doit être copié du registre de port interne correspondant vers un registre du microprocesseur avant d'être copié dans la mémoire. Cela prend normalement du temps si le nombre d'octets dans le flux est important. La solution pour un transfert rapide est l'utilisation du Direct Memory Access (circuit) sans passer par le microprocesseur.
Le circuit DMA se situe entre le port et le HD. C ou NIC. Avec l'accès direct à la mémoire du circuit DMA, le transfert de grands flux d'octets s'effectue directement entre le circuit DMA et la mémoire (RAM) sans la participation continue du microprocesseur. Le DMA utilise le bus d'adresses et le bus de données à la place du µP. La durée totale du transfert est plus courte que si le µP hard devait être utilisé. HD C. ou NIC utilisent le DMA lorsqu'ils disposent d'un flux important de données (octets) à transférer avec la RAM (la mémoire).
GPU signifie Graphics Processing Unit. Ce bloc sur la carte mère est chargé d'envoyer le texte et les images animées ou fixes à l'écran.
Avec les ordinateurs (PC) modernes, il n’y a pas de mémoire morte (ROM). Il existe cependant le BIOS ou UEFI qui est une sorte de RAM non volatile. Les informations du BIOS sont en fait conservées par une batterie. La batterie est également ce qui maintient la minuterie de l'horloge, à la bonne heure et à la bonne date pour l'ordinateur. L'UEFI a été inventé après le BIOS et a remplacé le BIOS, même si le BIOS est toujours très pertinent dans les PC modernes. Nous en reparlerons plus tard !
Dans les PC modernes, les bus d'adresses et de données entre le µP et les circuits de ports internes (et la mémoire) ne sont pas des bus parallèles. Ce sont des bus série qui nécessitent deux conducteurs pour la transmission dans un sens et deux autres conducteurs pour la transmission dans le sens opposé. Cela signifie, par exemple, que 32 bits peuvent être envoyés en série (un bit après l'autre) dans les deux sens.
Si la transmission série se fait uniquement dans un sens avec deux conducteurs (deux lignes), on parle alors de semi-duplex. Si la transmission série s'effectue dans les deux sens avec quatre conducteurs, une paire dans les deux sens, on parle alors de duplex intégral.
La mémoire entière d’un ordinateur moderne est toujours constituée d’une série d’emplacements d’octets : huit bits par octet. Un ordinateur moderne dispose d'un espace mémoire d'au moins 4 giga octets = 4 x 210 x 2 dix x2 dix = 4 x 1 073 741 824 dix octets = 4 x 1024 10/sous> x 1024 dix x1024 dix = 4 x 1 073 741 824 dix .
Note : Bien qu'aucun circuit de minuterie ne soit affiché sur la carte mère précédente, toutes les cartes mères modernes ont des circuits de minuterie.
6.3 Les bases de l'architecture informatique x64
6.31 L'ensemble de registres x64
Le microprocesseur 64 bits de la série de microprocesseurs x86 est un microprocesseur 64 bits. Il est assez moderne pour remplacer le processeur 32 bits de la même série. Les registres à usage général du microprocesseur 64 bits et leurs noms sont les suivants :
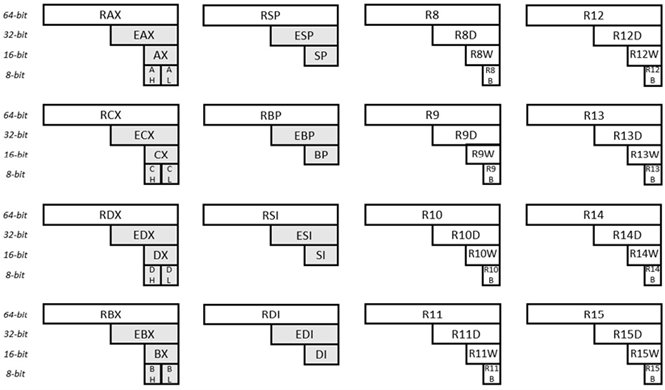
Fig. 6.31 Registres à usage général pour x64
Seize (16) registres à usage général sont présentés dans l'illustration donnée. Chacun de ces registres a une largeur de 64 bits. En regardant le registre dans le coin supérieur gauche, les 64 bits sont identifiés comme RAX. Les 32 premiers bits de ce même registre (en partant de la droite) sont identifiés comme EAX. Les 16 premiers bits de ce même registre (en partant de la droite) sont identifiés comme AX. Le deuxième octet (en partant de la droite) de ce même registre est identifié comme AH (H signifie ici haut). Et le premier octet (de ce même registre) est identifié comme AL (L signifie ici faible). En regardant le registre dans le coin inférieur droit, les 64 bits sont identifiés comme R15. Les 32 premiers bits de ce même registre sont identifiés comme R15D. Les 16 premiers bits de ce même registre sont identifiés comme R15W. Et le premier octet est identifié comme R15B. Les noms des autres registres (et sous-registres) sont expliqués de la même manière.
Il existe quelques différences entre les µP Intel et AMD. Les informations contenues dans cette section sont destinées à Intel.
Avec le 6502 µP, le registre Program Counter (non accessible directement) qui contient la prochaine instruction à exécuter a une largeur de 16 bits. Ici (x64), le compteur de programme est appelé pointeur d'instruction et sa largeur est de 64 bits. Il est étiqueté comme RIP. Cela signifie que le x64 µP peut adresser jusqu'à 264 = 1,844674407 x 1019 (en réalité 18 446 744 073 709 551 616) emplacements d'octets de mémoire. RIP n'est pas un registre à usage général.
Le Stack Pointer Register ou RSP fait partie des 16 registres à usage général. Il pointe vers la dernière entrée de pile dans la mémoire. Comme avec 6502 µP, la pile pour x64 croît vers le bas. Avec le x64, la pile en RAM est utilisée pour stocker les adresses de retour des sous-programmes. Il est également utilisé pour stocker « l’espace fantôme » (voir la discussion suivante).
Le 6502 µP dispose d'un registre d'état du processeur 8 bits. L'équivalent dans le x64 s'appelle le registre RFLAGS. Ce registre stocke les drapeaux utilisés pour les résultats des opérations et pour le contrôle du processeur (µP). Sa largeur est de 64 bits. Les 32 bits supérieurs sont réservés et ne sont pas utilisés actuellement. Le tableau suivant donne les noms, index et significations des bits couramment utilisés dans le registre RFLAGS :
| Tableau 6.31.1 Drapeaux RFLAGS (bits) les plus utilisés |
|||
|---|---|---|---|
| Symbole | Peu | Nom | But |
| FC | 0 | Porter | Il est défini si une opération arithmétique génère un report ou un emprunt du bit le plus significatif du résultat ; effacé autrement. Cet indicateur indique une condition de débordement pour l'arithmétique des entiers non signés. Il est également utilisé en arithmétique à précision multiple. |
| PF | 2 | Parité | Il est défini si l'octet de poids faible du résultat contient un nombre pair de bits 1 ; effacé autrement. |
| DE | 4 | Ajuster | Il est défini si une opération arithmétique génère un report ou un emprunt du bit 3 du résultat ; effacé autrement. Cet indicateur est utilisé en arithmétique décimale codée binaire (BCD). |
| ZF | 6 | Zéro | Il est défini si le résultat est nul ; effacé autrement. |
| SF | 7 | Signe | Il est positionné s'il est égal au bit de poids fort du résultat qui est le bit de signe d'un entier signé (0 indique une valeur positive et 1 indique une valeur négative). |
| DE | onze | Débordement | Il est défini si le résultat entier est un nombre positif trop grand ou un nombre négatif trop petit (à l'exclusion du bit de signe) pour tenir dans l'opérande de destination ; effacé autrement. Cet indicateur indique une condition de débordement pour l’arithmétique des entiers signés (complément à deux). |
| DF | dix | Direction | Il est défini si les instructions de chaîne de direction fonctionnent (incrémentation ou décrémentation). |
| IDENTIFIANT | vingt-et-un | Identification | Il est défini si sa variabilité indique la présence de l'instruction CPUID. |
En plus des dix-huit registres de 64 bits indiqués précédemment, l'architecture x64 µP dispose de huit registres de 80 bits de large pour l'arithmétique à virgule flottante. Ces huit registres peuvent également être utilisés comme registres MMX (voir la discussion suivante). Il existe également seize registres de 128 bits pour XMM (voir la discussion suivante).
Il ne s’agit pas uniquement de registres. Il existe d'autres registres x64 qui sont des registres de segments (pour la plupart inutilisés dans x64), des registres de contrôle, des registres de gestion de la mémoire, des registres de débogage, des registres de virtualisation, des registres de performances qui suivent toutes sortes de paramètres internes (accès/échecs du cache, micro-opérations exécutées, timing). , et beaucoup plus).
SIMD
SIMD signifie Données multiples à instruction unique. Cela signifie qu’une instruction en langage assembleur peut agir sur plusieurs données en même temps dans un seul microprocesseur. Considérez le tableau suivant :
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| + | 9 | dix | onze | 12 | 13 | 14 | quinze | 16 |
| = | dix | 12 | 14 | 16 | 18 | vingt | 22 | 24 |
Dans ce tableau, huit paires de nombres sont additionnées en parallèle (dans la même durée) pour donner huit réponses. Une instruction en langage assembleur peut effectuer les huit additions entières parallèles dans les registres MMX. Une chose similaire peut être faite avec les registres XMM. Il existe donc des instructions MMX pour les entiers et des instructions XMM pour les flottants.
6.32 Carte mémoire et x64
Avec le pointeur d'instruction (compteur de programme) ayant 64 bits, cela signifie que 264 = 1,844674407 x 1019 emplacements d'octets de mémoire peuvent être adressés. En hexadécimal, l'emplacement de l'octet le plus élevé est FFFF,FFFF,FFFF,FFFF16. Aucun ordinateur ordinaire aujourd’hui ne peut fournir un espace mémoire (complet) aussi grand. Ainsi, une carte mémoire appropriée pour l’ordinateur x64 est la suivante :

Notez que l'écart entre 0000,8000,0000,000016 et FFFF,7FFF,FFFF,FFFF16 n'a aucun emplacement mémoire (pas de banques de mémoire RAM). Il s’agit d’une différence de FFFF 0000 0000 000116, ce qui est assez important. La moitié canonique haute contient le système d'exploitation, tandis que la moitié canonique basse contient les programmes utilisateur (applications) et les données. Le système d'exploitation se compose de deux parties : un petit UEFI (BIOS) et une grande partie chargée depuis le disque dur. Le chapitre suivant parle davantage des systèmes d'exploitation modernes. Notez la similitude avec cette carte mémoire et celle du Commodore-64, où 64 Ko auraient pu ressembler à beaucoup de mémoire.
Dans ce contexte, le système d’exploitation est grossièrement appelé le « noyau ». Le noyau est similaire au Kernal de l'ordinateur Commodore-64, mais possède beaucoup plus de sous-programmes.
Le caractère endian pour x64 est petit endian, ce qui signifie que pour un emplacement, l'adresse inférieure pointe vers l'octet de contenu inférieur dans la mémoire.
6.33 Modes d'adressage du langage assembleur pour x64
Les modes d'adressage sont les moyens par lesquels une instruction peut accéder aux registres µP et à la mémoire (y compris les registres de port internes). Le x64 dispose de nombreux modes d'adressage, mais seuls les modes d'adressage couramment utilisés sont abordés ici. La syntaxe générale d'une instruction ici est :
destination de l'opcode, source
Les nombres décimaux sont écrits sans préfixe ni suffixe. Avec le 6502, la source est implicite. Le x64 a plus de codes op que le 6502, mais certains opcodes ont les mêmes mnémoniques. Les instructions x64 individuelles sont de longueur variable et peuvent varier en taille de 1 à 15 octets. Les modes d'adressage couramment utilisés sont les suivants :
Mode d'adressage immédiat
Ici, l'opérande source est une valeur réelle et non une adresse ou une étiquette. Exemple (lire le commentaire) :
AJOUTER EAX, 14 ; ajoutez le décimal 14 à l'EAX 32 bits du RAX 64 bits, la réponse reste dans l'EAX (destination)
S'inscrire pour enregistrer le mode d'adressage
Exemple:
AJOUTER R8B, AL ; ajoutez AL 8 bits de RAX à R8B de R8 64 bits – les réponses restent dans R8B (destination)
Mode d'adressage indirect et indexé
L'adressage indirect avec le 6502 µP signifie que l'emplacement de l'adresse donnée dans l'instruction a l'adresse effective (pointeur) de l'emplacement final. Une chose similaire se produit avec x64. L'adressage d'index avec le 6502 µP signifie que le contenu d'un registre µP est ajouté à l'adresse donnée dans l'instruction pour avoir l'adresse effective. Une chose similaire se produit avec le x64. Aussi, avec le x64, le contenu du registre peut également être multiplié par 1 ou 2 ou 4 ou 8 avant d'être ajouté à l'adresse donnée. L'instruction mov (copie) du x64 peut combiner à la fois l'adressage indirect et indexé. Exemple:
MOUVEMENT R8W, 1234[8*RAX+RCX] ; déplacer le mot à l'adresse (8 x RAX + RCX) + 1234
Ici, R8W possède les 16 premiers bits de R8. L'adresse donnée est 1234. Le registre RAX a un nombre de 64 bits multiplié par 8. Le résultat est ajouté au contenu du registre RCX de 64 bits. Ce deuxième résultat est ajouté à l'adresse donnée qui est 1234 pour obtenir l'adresse effective. Le numéro à l'emplacement de l'adresse effective est déplacé (copié) vers la première position de 16 bits (R8W) du registre R8, remplaçant tout ce qui s'y trouvait. Notez l’utilisation des crochets. N'oubliez pas qu'un mot en x64 a une largeur de 16 bits.
Adressage relatif RIP
Pour le 6502 µP, l'adressage relatif est utilisé uniquement avec les instructions de branchement. Là, l'opérande unique de l'opcode est un décalage qui est ajouté ou soustrait au contenu du compteur de programme pour l'adresse d'instruction effective (et non l'adresse de données). Une chose similaire se produit avec le x64 où le compteur de programme est appelé pointeur d'instruction. L’instruction avec x64 ne doit pas seulement être une instruction de branchement. Voici un exemple d'adressage relatif RIP :
MOV AL, [RIP]
AL de RAX a un numéro signé de 8 bits qui est ajouté ou soustrait du contenu dans RIP (pointeur d'instruction 64 bits) pour pointer vers l'instruction suivante. Notez que la source et la destination sont exceptionnellement permutées dans cette instruction. Notez également l'utilisation de crochets qui font référence au contenu de RIP.
6.34 Instructions couramment utilisées de x64
Dans le tableau suivant, * désigne différents suffixes possibles d'un sous-ensemble d'opcodes :
| Tableau 6.34.1 Instructions couramment utilisées en x64 |
|
|---|---|
| Opcode | Signification |
| MOV | Déplacer (copier) vers/depuis/entre la mémoire et les registres |
| CMOV* | Divers mouvements conditionnels |
| XCHG | Échange |
| BSWAP | Échange d'octets |
| POUSSER/POP | Utilisation de la pile |
| AJOUTER/ADC | Ajouter/avec transport |
| SUB/SBC | Soustraire/avec report |
| MUL/IMUL | Multiplier/non signé |
| DIV/IDIV | Divisé/non signé |
| INC/DÉC | Incrémenter/Décrémenter |
| NÉG | Nier |
| CMP | Comparer |
| ET/OU/XOR/NON | Opérations au niveau du bit |
| SHR/DAS | Décalage vers la droite logique/arithmétique |
| SHL/SAL | Maj gauche logique/arithmétique |
| ROR/RÔLE | Faire pivoter à droite/à gauche |
| RCR/RCL | Rotation à droite/à gauche via le mors de transport |
| BT/BTS/BTR | Test de bits/et réglage/et réinitialisation |
| JMP | Saut inconditionnel |
| JE/JNE/JC/JNC/J* | Sauter si égal/pas égal/porter/ne pas porter/beaucoup d'autres |
| MARCHE/MARCHE/MARCHE | Boucle avec ECX |
| APPEL/RET | Appeler le sous-programme/retour |
| NON | Pas d'opération |
| CPUID | Informations sur le processeur |
Le x64 a des instructions de multiplication et de division. Il possède des circuits matériels de multiplication et de division dans son µP. Le 6502 µP ne dispose pas de circuits matériels de multiplication et de division. Il est plus rapide d'effectuer la multiplication et la division par matériel que par logiciel (y compris le décalage des bits).
Instructions de chaîne
Il existe un certain nombre d'instructions de chaîne, mais la seule à être abordée ici est l'instruction MOVS (pour move string) pour copier une chaîne commençant à l'adresse C000. H . Pour commencer à l'adresse C100 H , utilisez les instructions suivantes :
MOUVEMENTS [C100H], [C000H]
Notez le suffixe H pour hexadécimal.
6.35 Boucle en x64
Le 6502 µP dispose d'instructions de branchement pour le bouclage. Une instruction de branchement saute vers un emplacement d'adresse qui contient la nouvelle instruction. L'emplacement de l'adresse peut être appelé « boucle ». Le x64 dispose d'instructions LOOP/LOOPE/LOOPNE pour le bouclage. Ces mots réservés en langage assembleur ne doivent pas être confondus avec le label « boucle » (sans les guillemets). Le comportement est le suivant :
LOOP décrémente ECX et vérifie si ECX n'est pas nul. Si cette condition (zéro) est remplie, il passe à une étiquette spécifiée. Sinon, cela échoue (continuez avec le reste des instructions dans la discussion suivante).
LOOPE décrémente ECX et vérifie que ECX n'est pas nul (peut être 1 par exemple) et que ZF est défini (à 1). Si ces conditions sont remplies, il saute sur l'étiquette. Sinon, ça échoue.
LOOPNE décrémente ECX et vérifie que ECX n'est pas nul et que ZF N'EST PAS défini (c'est-à-dire qu'il est nul). Si ces conditions sont remplies, il passe à l'étiquette. Sinon, ça échoue.
Avec x64, le registre RCX ou ses sous-parties comme ECX ou CX, contient le compteur entier. Avec les instructions LOOP, le compteur décompte normalement, décrémentant de 1 pour chaque saut (boucle). Dans le segment de code de boucle suivant, le nombre dans le registre EAX augmente de 0 à 10 en dix itérations tandis que le nombre dans ECX compte (décrémente) 10 fois (lire les commentaires) :
MOUVEMENT EAX, 0 ;
MOUVEMENT ECX, 10 ; compte à rebours 10 fois par défaut, une fois pour chaque itération
étiquette:
INC EAX ; incrémenter EAX comme corps de boucle
Étiquette BOUCLE ; décrémentez EAX, et si EAX n'est pas nul, réexécutez le corps de la boucle à partir de « label : »
Le codage de la boucle commence à partir de « label : ». Notez l'utilisation des deux points. Le codage de la boucle se termine par « étiquette LOOP » qui indique décrémenter EAX. Si son contenu n'est pas nul, revenez à l'instruction après « label : » et réexécutez toute instruction (toutes les instructions du corps) qui descend jusqu'au « label LOOP ». Notez que « label » peut toujours avoir un autre nom.
6.36 Entrée/Sortie de x64
Cette section du chapitre traite de l'envoi des données vers un port de sortie (interne) ou de la réception des données depuis un port d'entrée (interne). Le chipset dispose de ports huit bits. Deux ports 8 bits consécutifs peuvent être traités comme un port 16 bits, et quatre ports consécutifs peuvent être un port 32 bits. De cette manière, le processeur peut transférer 8, 16 ou 32 bits vers ou depuis un périphérique externe.
Les informations peuvent être transférées entre le processeur et un port interne de deux manières : en utilisant ce que l'on appelle les entrées/sorties mappées en mémoire ou en utilisant un espace d'adressage d'entrée/sortie séparé. Les E/S mappées en mémoire ressemblent à ce qui se passe avec le processeur 6502, où les adresses de port font en réalité partie de tout l'espace mémoire. Dans ce cas, lors de l'envoi des données vers un emplacement d'adresse particulier, elles vont vers un port et non vers une banque mémoire. Les ports peuvent avoir un espace d'adressage d'E/S distinct. Dans ce dernier cas, tous les bancs mémoire ont leurs adresses à partir de zéro. Il existe une plage d'adresses distincte de 0000H à FFFF16. Ceux-ci sont utilisés par les ports du chipset. La carte mère est programmée afin de ne pas confondre entre les E/S mappées en mémoire et l'espace d'adressage d'E/S séparé.
E/S mappées en mémoire
Avec cela, les ports sont considérés comme des emplacements mémoire, et les opcodes normaux à utiliser entre la mémoire et le µP sont utilisés pour le transfert de données entre le µP et les ports. Ainsi, pour déplacer un octet d'un port à l'adresse F000H vers le registre µP RAX:EAX:AX:AL, procédez comme suit :
MOV AL, [F000H]
Une chaîne peut être déplacée de la mémoire vers un port et vice versa. Exemple:
MOUVEMENTS [F000H], [C000H] ; la source est C000H et la destination est le port à F000H.
Espace d'adressage E/S séparé
Pour cela, les instructions spéciales pour l'entrée et la sortie doivent être utilisées.
Transférer des éléments uniques
Le registre du processeur pour le transfert est RAX. En fait, il s'agit de RAX:EAX pour double mot, RAX:EAX:AX pour mot et RAX:EAX:AX:AL pour octet. Ainsi, pour transférer un octet d'un port à FFF0h vers RAX:EAX:AX:AL, tapez ce qui suit :
DANS AL, [FFF0H]
Pour le virement inverse, saisissez ce qui suit :
SORTIE [FFF0H], AL
Ainsi, pour les articles uniques, les instructions sont IN et OUT. L'adresse du port peut également être indiquée dans le registre RDX:EDX:DX.
Transfert de chaînes
Une chaîne peut être transférée de la mémoire vers un port du chipset et vice versa. Pour transférer une chaîne d'un port à l'adresse FFF0H vers la mémoire, commencez à C100H, tapez :
INS [ESI], [DX]
ce qui a le même effet que :
INS [EDI], [DX]
Le programmeur doit mettre l'adresse de port sur deux octets de FFF0H dans le registre RDX:EDX:Dx et doit mettre l'adresse de port sur deux octets de C100H dans le registre RSI:ESI ou RDI:EDI. Pour le transfert inverse, procédez comme suit :
INS [DX], [ESI]
ce qui a le même effet que :
INS [DX], [EDI]
6.37 La pile en x64
Comme le processeur 6502, le processeur x64 dispose également d'une pile en RAM. La pile pour le x64 peut être 2 16 = 65 536 octets de long ou cela peut être 2 32 = 4 294 967 296 octets de long. Il pousse également vers le bas. Lorsque le contenu d'un registre est placé sur la pile, le nombre dans le pointeur de pile RSP est diminué de 8. N'oubliez pas qu'une adresse mémoire pour le x64 a une largeur de 64 bits. La valeur du pointeur de pile dans le µP pointe vers l'emplacement suivant de la pile dans la RAM. Lorsque le contenu d'un registre (ou une valeur dans un opérande) est extrait de la pile dans un registre, le nombre dans le pointeur de pile RSP est augmenté de 8. Le système d'exploitation décide de la taille de la pile et de son emplacement de départ dans la RAM. et grandit vers le bas. N'oubliez pas qu'une pile est une structure Last-In-First-Out (LIFO) qui croît vers le bas et se rétrécit vers le haut dans ce cas.
Pour pousser le contenu du registre µP RBX vers la pile, procédez comme suit :
POUSSER RBX
Pour réinsérer la dernière entrée de la pile dans RBX, procédez comme suit :
POP RBX
6.38 Procédure en x64
Le sous-programme du x64 est appelé « procédure ». La pile est ici plus utilisée que pour le 6502 µP. La syntaxe d'une procédure x64 est la suivante :
nom_proc :
corps de procédure
…
droite
Avant de continuer, notez que les opcodes et les étiquettes d'un sous-programme x64 (instructions en langage assembleur en général) ne sont pas sensibles à la casse. C'est-à-dire que proc_name est identique à PROC_NAME. Comme le 6502, le nom de la procédure (étiquette) commence au début d'une nouvelle ligne dans l'éditeur de texte pour le langage assembleur. Ceci est suivi de deux points et non d'un espace et d'un opcode comme avec le 6502. Le corps du sous-programme suit, se terminant par RET et non RTS comme avec le 6502 µP. Comme pour le 6502, chaque instruction du corps, y compris RET, ne commence pas au début de sa ligne. Notez qu’une étiquette ici peut comporter plus de 8 caractères. Pour appeler cette procédure, au dessus ou en dessous de la procédure saisie, procédez comme suit :
APPELER nom_proc
Avec le 6502, le nom de l'étiquette est simplement saisi pour appeler. Cependant, ici, on tape le mot réservé « CALL » ou « call », suivi du nom de la procédure (sous-programme) après un espace.
Lorsqu’il s’agit de procédures, il existe généralement deux procédures. Une procédure appelle l’autre. La procédure qui appelle (qui possède l'instruction d'appel) est appelée « l'appelant » et la procédure appelée est appelée « l'appelé ». Il y a une convention (des règles) à suivre.
Les règles de l'appelant
L'appelant doit respecter les règles suivantes lors de l'appel d'un sous-programme :
1. Avant d'appeler un sous-programme, l'appelant doit sauvegarder le contenu de certains registres désignés comme enregistrés par l'appelant dans la pile. Les registres enregistrés par l'appelant sont R10, R11 et tous les registres dans lesquels les paramètres sont placés (RDI, RSI, RDX, RCX, R8, R9). Si le contenu de ces registres doit être conservé tout au long de l'appel du sous-programme, placez-les sur la pile au lieu de les enregistrer ensuite dans la RAM. Celles-ci doivent être effectuées car les registres doivent être utilisés par l'appelé pour effacer le contenu précédent.
2. Si la procédure consiste à additionner deux nombres par exemple, les deux nombres sont les paramètres à passer à la pile. Pour transmettre les paramètres au sous-programme, placez-en six dans les registres suivants dans l'ordre : RDI, RSI, RDX, RCX, R8, R9. S'il y a plus de six paramètres dans le sous-programme, placez le reste sur la pile dans l'ordre inverse (c'est-à-dire le dernier paramètre en premier). Au fur et à mesure que la pile s'agrandit, le premier des paramètres supplémentaires (en réalité le septième paramètre) est stocké à l'adresse la plus basse (cette inversion de paramètres était historiquement utilisée pour permettre aux fonctions (sous-programmes) d'être passées avec un nombre variable de paramètres).
3. Pour appeler le sous-programme (procédure), utilisez l'instruction d'appel. Cette instruction place l'adresse de retour au-dessus des paramètres sur la pile (position la plus basse) et les branches vers le code du sous-programme.
4. Après le retour du sous-programme (c'est-à-dire immédiatement après l'instruction d'appel), l'appelant doit supprimer tous les paramètres supplémentaires (au-delà des six stockés dans les registres) de la pile. Cela restaure la pile à son état avant l'exécution de l'appel.
5. L'appelant peut s'attendre à trouver la valeur de retour (adresse) du sous-programme dans le registre RAX.
6. L'appelant restaure le contenu des registres enregistrés par l'appelant (R10, R11 et tous les registres de passage de paramètres) en les retirant de la pile. L'appelant peut supposer qu'aucun autre registre n'a été modifié par le sous-programme.
En raison de la manière dont la convention d'appel est structurée, il arrive généralement que certaines (ou la plupart) de ces étapes n'apportent aucune modification à la pile. Par exemple, s’il y a six paramètres ou moins, rien n’est placé sur la pile à cette étape. De même, les programmeurs (et les compilateurs) conservent généralement les résultats qui les intéressent en dehors des registres enregistrés par l'appelant aux étapes 1 et 6 pour éviter les poussées et les pops excessifs.
Il existe deux autres manières de transmettre les paramètres à un sous-programme, mais celles-ci ne seront pas abordées dans ce cours de carrière en ligne. L'un d'eux utilise la pile elle-même au lieu des registres à usage général.
Les règles de l'appelé
La définition du sous-programme appelé doit respecter les règles suivantes :
1. Allouez les variables locales (variables développées dans la procédure) à l'aide des registres ou en faisant de la place sur la pile. Rappelez-vous que la pile croît vers le bas. Ainsi, pour libérer de l'espace en haut de la pile, le pointeur de pile doit être décrémenté. La quantité de décrémentation du pointeur de pile dépend du nombre nécessaire de variables locales. Par exemple, si un float local et un long local (12 octets au total) sont requis, le pointeur de pile doit être décrémenté de 12 pour libérer de l'espace pour ces variables locales. Dans un langage de haut niveau comme C, cela signifie déclarer les variables sans attribuer (initialiser) les valeurs.
2. Ensuite, les valeurs de tous les registres qui sont enregistrés par l'appelé désigné (registres à usage général non enregistrés par l'appelant) qui sont utilisés par la fonction doivent être enregistrés. Pour enregistrer les registres, placez-les sur la pile. Les registres enregistrés par l'appelé sont RBX, RBP et R12 à R15 (RSP est également préservé par la convention d'appel, mais n'a pas besoin d'être poussé sur la pile au cours de cette étape).
Une fois ces trois actions réalisées, le fonctionnement proprement dit du sous-programme peut se poursuivre. Lorsque le sous-programme est prêt à revenir, les règles de convention d'appel continuent.
3. Lorsque le sous-programme est terminé, la valeur de retour du sous-programme doit être placée dans RAX si elle n'y est pas déjà.
4. Le sous-programme doit restaurer les anciennes valeurs de tous les registres enregistrés par les appelés (RBX, RBP et R12 à R15) qui ont été modifiés. Le contenu du registre est restauré en le retirant de la pile. Notez que les registres doivent être ouverts dans l'ordre inverse de leur poussée.
5. Ensuite, nous libérons les variables locales. La façon la plus simple de procéder est d’ajouter au RER le même montant qui en a été soustrait à l’étape 1.
6. Enfin, nous revenons vers l'appelant en exécutant une instruction ret. Cette instruction trouvera et supprimera l'adresse de retour appropriée de la pile.
Un exemple du corps d'un sous-programme appelant pour appeler un autre sous-programme qui est « myFunc » est le suivant (lire les commentaires) :
; Vous voulez appeler une fonction « myFunc » qui prend trois
; paramètre entier. Le premier paramètre est dans RAX .
; Le deuxième paramètre est la constante 456. Troisième
; le paramètre est dans l’emplacement mémoire « variabl »
pousser rdi ; rdi sera un paramètre, donc sauvegardez-le
; long retVal = myFunc ( x , 456 , z ) ;
mov rdi , rax ; mettre le premier paramètre dans RDI
mouvement rsi, 456 ; mettre le deuxième paramètre dans RSI
mov rdx , [variable] ; mettre le troisième paramètre dans RDX
appelle myFunc ; appeler la fonction
pop rdi ; restaurer la valeur RDI enregistrée
; la valeur de retour de myFunc est maintenant disponible dans RAX
Un exemple de fonction appelée (myFunc) est (lire les commentaires) :
maFonction :
; ∗∗∗ Prologue de sous-programme standard ∗∗∗
sous rsp, 8 ; place pour une variable locale de 64 bits (résultat) en utilisant l'opcode 'sub'
pousser rbx ; enregistrer l'appelé−enregistrer les registres
pousser rbp ; les deux seront utilisés par myFunc
; ∗∗∗ Sous-routine Corps ∗∗∗
mov rax , rdi ; paramètre 1 à RAX
mov rbp, rsi ; paramètre 2 à RBP
mouvement rbx, rdx ; paramètre 3 à rb x
mov [ rsp + 1 6 ] , rbx ; mettre rbx dans une variable locale
ajouter [ rsp + 1 6 ] , rbp ; ajouter rbp dans la variable locale
mov rax , [ rsp +16 ] ; déplacer le contenu de la variable locale vers RAX
; (valeur de retour/résultat final)
; ∗∗∗ Épilogue du sous-programme standard ∗∗∗
pop rbp ; récupérer les registres de sauvegarde des appelés
pop rbx ; inversement lorsqu'on le pousse
ajouter rsp, 8 ; désallouer la ou les variables locales. 8 signifie 8 octets
retraité ; afficher la valeur supérieure de la pile, y aller
6.39 Interruptions et exceptions pour x64
Le processeur fournit deux mécanismes pour interrompre l'exécution du programme, les interruptions et les exceptions :
- Une interruption est un événement asynchrone (peut survenir à tout moment) qui est généralement déclenché par un périphérique d'E/S.
- Une exception est un événement synchrone (qui se produit lorsque le code est exécuté, préprogrammé, basé sur une occurrence) qui est généré lorsque le processeur détecte une ou plusieurs conditions prédéfinies lors de l'exécution d'une instruction. Trois classes d'exceptions sont spécifiées : les erreurs, les interruptions et les abandons.
Le processeur répond aux interruptions et aux exceptions essentiellement de la même manière. Lorsqu'une interruption ou une exception est signalée, le processeur arrête l'exécution du programme ou de la tâche en cours et passe à une procédure de gestionnaire écrite spécifiquement pour gérer la condition d'interruption ou d'exception. Le processeur accède à la procédure du gestionnaire via une entrée dans la table des descripteurs d'interruption (IDT). Lorsque le gestionnaire a terminé de traiter l'interruption ou l'exception, le contrôle du programme est renvoyé au programme ou à la tâche interrompue.
Les pilotes du système d'exploitation, de l'exécutif et/ou du périphérique gèrent normalement les interruptions et les exceptions indépendamment des programmes ou des tâches d'application. Les programmes d'application peuvent cependant accéder aux gestionnaires d'interruptions et d'exceptions incorporés dans un système d'exploitation ou l'exécuter via les appels en langage assembleur.
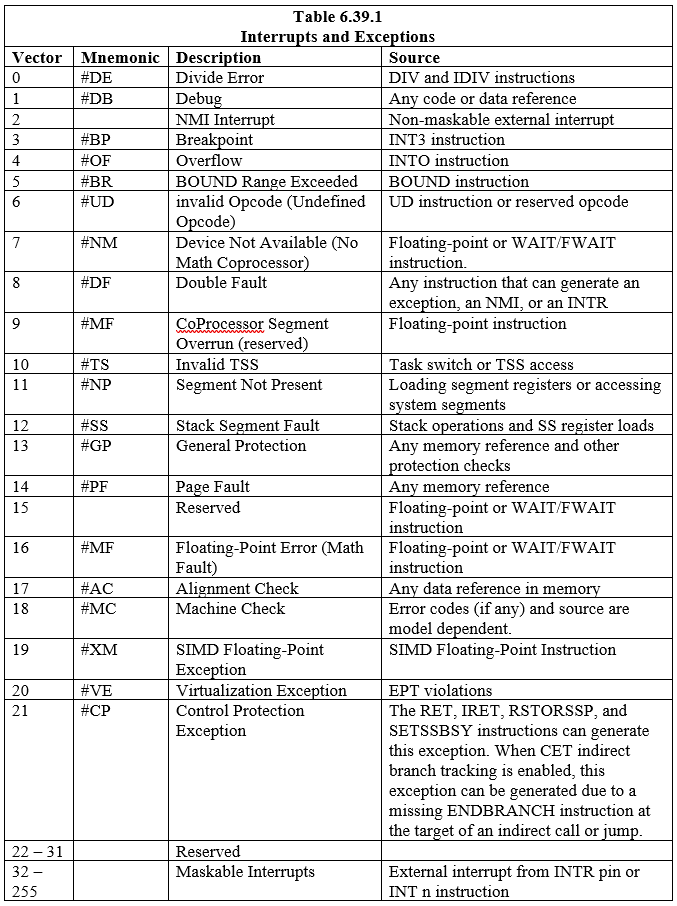
Dix-huit (18) interruptions et exceptions prédéfinies, associées aux entrées dans l'IDT, sont définies. Deux cent vingt-quatre (224) interruptions définies par l'utilisateur peuvent également être effectuées et associées à la table. Chaque interruption et exception dans l'IDT est identifiée par un numéro appelé « vecteur ». Le tableau 6.39.1 répertorie les interruptions et exceptions avec des entrées dans l'IDT et leurs vecteurs respectifs. Les vecteurs 0 à 8, 10 à 14 et 16 à 19 sont les interruptions et exceptions prédéfinies. Les vecteurs 32 à 255 sont destinés aux interruptions définies par logiciel (utilisateur) qui sont destinées soit à des interruptions logicielles, soit à des interruptions matérielles masquables.
Lorsque le processeur détecte une interruption ou une exception, il effectue l'une des opérations suivantes :
- Exécuter un appel implicite à une procédure de gestionnaire
- Exécuter un appel implicite à une tâche de gestionnaire
6.4 Les bases de l'architecture informatique ARM 64 bits
Les architectures ARM définissent une famille de processeurs RISC adaptés à une utilisation dans une grande variété d'applications. ARM est une architecture de chargement/stockage qui nécessite que les données soient chargées de la mémoire vers un registre avant qu'un traitement tel qu'une opération ALU (Arithmetic Logic Unit) puisse avoir lieu avec. Une instruction ultérieure stocke le résultat dans la mémoire. Même si cela peut sembler un recul par rapport aux architectures x86 et x64, qui opèrent directement sur les opérandes de la mémoire en une seule instruction (en utilisant les registres du processeur, bien sûr), l'approche chargement/stockage permet en pratique plusieurs opérations séquentielles. être exécuté à grande vitesse sur un opérande une fois celui-ci chargé dans l'un des nombreux registres du processeur. Les processeurs ARM ont le choix entre un caractère peu endianiste ou un caractère big-endien. Le paramètre par défaut d'ARM 64 est Little-Endian, qui est la configuration couramment utilisée par les systèmes d'exploitation. L'architecture ARM 64 bits est moderne et devrait remplacer l'architecture ARM 32 bits.
Note : Chaque instruction pour l'ARM µP 64 bits est longue de 4 octets (32 bits).
6.41 L'ensemble de registres ARM 64 bits
Il existe 31 registres 64 bits à usage général pour l'ARM µP 64 bits. Le diagramme suivant montre les registres à usage général et certains registres importants :
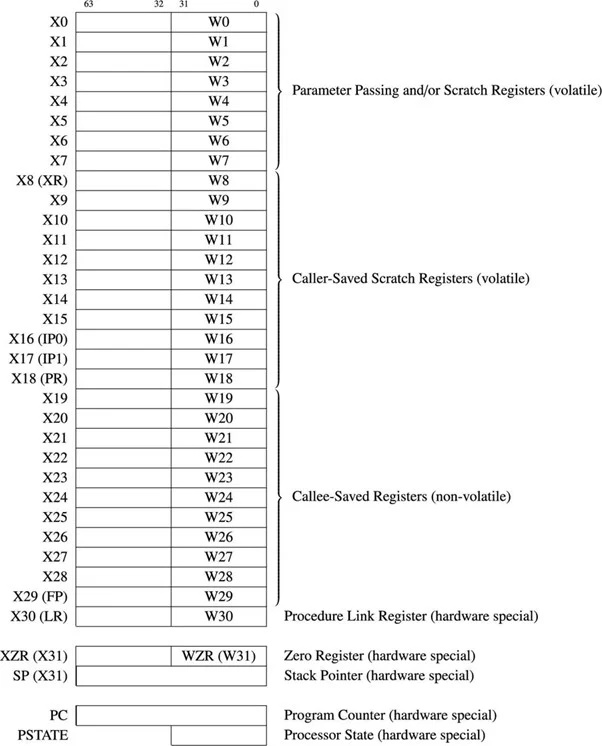
Fig.4.11.1 Usage général 64 bits et quelques registres importants
Les registres à usage général sont appelés X0 à X30. La première partie de 32 bits de chaque registre est appelée W0 à W30. Lorsque la différence entre 32 bits et 64 bits n'est pas soulignée, le préfixe « R » est utilisé. Par exemple, R14 fait référence à W14 ou X14.
Le 6502 µP dispose d'un compteur de programme 16 bits et peut adresser les 2 16 emplacements des octets de mémoire. L'ARM µP 64 bits possède un compteur de programme 64 bits et peut adresser jusqu'à 2 64 = 1,844674407 x 1019 (en fait 18 446 744 073 709 551 616) emplacements d'octets de mémoire. Le compteur de programme contient l'adresse de la prochaine instruction à exécuter. La longueur de l'instruction de l'ARM64 ou de l'AArch64 est généralement de quatre octets. Le processeur incrémente automatiquement ce registre de quatre après que chaque instruction soit extraite de la mémoire.
Le registre Stack Pointer ou SP ne fait pas partie des 31 registres à usage général. Le pointeur de pile de n’importe quelle architecture pointe vers la dernière entrée de pile dans la mémoire. Pour l'ARM-64, la pile croît vers le bas.
Le 6502 µP dispose d'un registre d'état du processeur 8 bits. L'équivalent dans l'ARM64 est appelé le registre PSTATE. Ce registre stocke les drapeaux utilisés pour les résultats des opérations et pour le contrôle du processeur (µP). Sa largeur est de 32 bits. Le tableau suivant donne les noms, index et significations des bits couramment utilisés dans le registre PSTATE :
| Tableau 6.41.1 Indicateurs PSTATE les plus utilisés (bits) |
||
|---|---|---|
| Symbole | Peu | But |
| M | 0-3 | Mode : niveau de privilège d'exécution actuel (USR, SVC, etc.). |
| T | 4 | Thumb : Il est défini si le jeu d'instructions T32 (Thumb) est actif. S’il est clair, le jeu d’instructions ARM est actif. Le code utilisateur peut activer et effacer ce bit. |
| ET | 9 | Endianness : la définition de ce bit active le mode big-endian. Si clair, le mode petit-boutiste est actif. La valeur par défaut est le mode petit-boutiste. |
| Q | 27 | Indicateur de saturation cumulée : il est activé si, à un moment donné d'une série d'opérations, un débordement ou une saturation se produit |
| DANS | 28 | Indicateur de débordement : il est défini si l'opération a entraîné un débordement signé. |
| C | 29 | Indicateur de report : il indique si l'addition a produit un report ou la soustraction a produit un emprunt. |
| AVEC | 30 | Indicateur zéro : il est défini si le résultat d'une opération est zéro. |
| N | 31 | Indicateur négatif : il est défini si le résultat d'une opération est négatif. |
L'ARM-64 µP possède de nombreux autres registres.
SIMD
SIMD signifie Instruction unique, données multiples. Cela signifie qu’une instruction en langage assembleur peut agir sur plusieurs données en même temps dans un seul microprocesseur. Il existe trente-deux registres de 128 bits de large à utiliser avec les opérations SIMD et à virgule flottante.
6.42 Mappage de la mémoire
La RAM et la DRAM sont toutes deux des mémoires à accès aléatoire. La DRAM fonctionne plus lentement que la RAM. La DRAM est moins chère que la RAM. S'il y a plus de 32 gigaoctets (Go) de DRAM continue dans la mémoire, il y aura davantage de problèmes de gestion de la mémoire : 32 Go = 32 x 1 024 x 1 024 x 1 024 octets. Pour un espace mémoire total bien supérieur à 32 Go, la DRAM supérieure à 32 Go doit être intercalée avec des RAM pour une meilleure gestion de la mémoire. Afin de comprendre la carte mémoire ARM-64, vous devez d'abord comprendre la carte mémoire de 4 Go pour l'unité centrale de traitement (CPU) ARM 32 bits. CPU signifie µP. Pour un ordinateur 32 bits, l'espace mémoire adressable maximum est de 2 32 = 4x2 dix x2 dix x2 dix = 4 x 1 024 x 1 024 x 1 024 = 4 294 967 296 = 4 Go.
Carte mémoire ARM 32 bits
La carte mémoire pour un ARM 32 bits est :

Pour un ordinateur 32 bits, la taille maximale de la mémoire totale est de 4 Go. De l’adresse 0 Go à l’adresse 1 Go se trouvent les emplacements du système d’exploitation ROM, de la RAM et des E/S. L'idée générale du système d'exploitation ROM, de la RAM et des adresses d'E/S est similaire à la situation du Commodore-64 avec un éventuel processeur 6502. La ROM du système d'exploitation du Commodore-64 se trouve en haut de l'espace mémoire. Le système d'exploitation ROM ici est beaucoup plus grand que celui du Commodore-64 et se situe au début de tout l'espace d'adressage mémoire. Comparé à d’autres ordinateurs modernes, le système d’exploitation ROM est ici complet, dans le sens où il est comparable à la quantité de système d’exploitation présente sur leurs disques durs. Il y a deux raisons principales pour lesquelles le système d'exploitation est présent dans les circuits intégrés ROM : 1) Les processeurs ARM sont principalement utilisés dans les petits appareils comme les smartphones. De nombreux disques durs sont plus gros que les smartphones et autres petits appareils, 2) pour des raisons de sécurité. Lorsque le système d'exploitation est dans la mémoire en lecture seule, il ne peut pas être corrompu (parties écrasées) par des pirates. Les sections RAM et les sections d'entrée/sortie sont également très grandes par rapport à celles du Commodore-64.
Lors de la mise sous tension avec le système d'exploitation ROM 32 bits, le système d'exploitation doit démarrer à (démarrer à partir de) l'adresse 0x00000000 ou l'adresse 0xFFFF0000 si HiVEC est activé. Ainsi, lorsque l'alimentation est remise après la phase de réinitialisation, le matériel du processeur charge 0x00000000 ou 0xFFFF0000 dans le compteur de programme. Le préfixe « 0x » signifie Hexadécimal. L'adresse de démarrage des processeurs ARMv8 64 bits est une implémentation définie. Cependant, l'auteur conseille à l'ingénieur informaticien de démarrer à 0x00000000 ou 0xFFFF0000 par souci de compatibilité ascendante.
De 1 Go à 2 Go correspond à l’entrée/sortie mappée. Il existe une différence entre les E/S mappées et les E/S uniquement qui se trouvent entre 0 Go et 1 Go. Avec les E/S, l'adresse de chaque port est fixe comme avec le Commodore-64. Avec les E/S mappées, l'adresse de chaque port n'est pas nécessairement la même pour chaque opération de l'ordinateur (dynamique).
De 2 Go à 4 Go, c'est de la DRAM. Il s'agit de la RAM attendue (ou habituelle). DRAM signifie Dynamic RAM, ce n'est pas le sens d'un changement d'adresse pendant le fonctionnement de l'ordinateur mais dans le sens où la valeur de chaque cellule de la RAM physique doit être actualisée à chaque impulsion d'horloge.
Note :
- De 0x0000,0000 à 0x0000, FFFF est la ROM du système d'exploitation.
- De 0x0001,0000 à 0x3FFF,FFFF, il peut y avoir plus de ROM, puis de RAM, et enfin quelques E/S.
- De 0x4000,0000 à 0x7FFF,FFFF, une E/S supplémentaire et/ou une E/S mappée est autorisée.
- De 0x8000,0000 à 0xFFFF,FFFF est la DRAM attendue.
Cela signifie que la DRAM attendue ne doit pas nécessairement démarrer à la limite de 2 Go de mémoire, en pratique. Pourquoi le programmeur devrait-il respecter les limites idéales alors qu'il n'y a pas suffisamment de banques de RAM physiques insérées sur la carte mère ? En effet, le client n'a pas assez d'argent pour toutes les banques RAM.
Carte mémoire ARM 36 bits
Pour un ordinateur ARM 64 bits, tous les 32 bits sont utilisés pour adresser toute la mémoire. Pour un ordinateur ARM 64 bits, les 36 premiers bits peuvent être utilisés pour adresser toute la mémoire qui, dans ce cas, est de 2 36 = 68 719 476 736 = 64 Go. Cela représente déjà beaucoup de mémoire. Les ordinateurs ordinaires d’aujourd’hui n’ont pas besoin d’une telle quantité de mémoire. Ce n'est pas encore la plage maximale de mémoire accessible par 64 bits. La carte mémoire pour 36 bits pour le processeur ARM est :
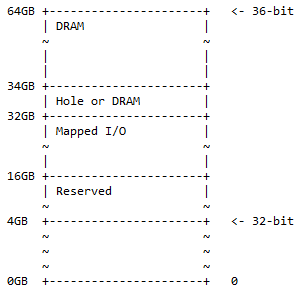
De l'adresse 0 Go à l'adresse 4 Go se trouve la carte mémoire 32 bits. « Réservé » signifie non utilisé et est conservé pour une utilisation future. Il n'est pas nécessaire que ce soient des banques de mémoire physiques insérées sur la carte mère pour cet espace. Ici, la DRAM et les E/S mappées ont les mêmes significations que pour la carte mémoire 32 bits.
En pratique, on peut rencontrer la situation suivante :
- 0x1 0000 0000 – 0x3 FFFF FFFF ; réservé. 12 Go d'espace d'adressage sont réservés pour une utilisation future.
- 0x4 0000 0000 – 0x7 FFFF FFFF ; E/S mappées. 16 Go d'espace d'adressage sont disponibles pour les E/S mappées dynamiquement.
- 0x8 0000 0000 – 0x8 7FFF FFFF FFFF ; Trou ou DRAM. 2 Go d'espace d'adressage peuvent contenir l'un des éléments suivants :
- Trou pour activer le partitionnement du périphérique DRAM (comme décrit dans la discussion suivante).
- DRACHME.
- 0x8 8000 0000 – 0xF FFFF FFFF ; DRACHME. 30 Go d'espace d'adressage pour la DRAM.
Cette carte mémoire est un surensemble de la carte d'adresses 32 bits, l'espace supplémentaire étant divisé en 50 % de DRAM (1/2) avec un trou facultatif et 25 % d'espace d'E/S mappé et d'espace réservé (1/4). ). Les 25 % restants (1/4) sont destinés à la carte mémoire 32 bits ½ + ¼ + ¼ = 1.
Note : De 32 bits à 360 bits, c'est un ajout de 4 bits au côté le plus significatif de 36 bits.
Carte mémoire 40 bits
La carte d'adresses 40 bits est un surensemble de la carte d'adresses 36 bits et suit le même modèle de 50 % de DRAM d'un trou facultatif, 25 % d'espace d'E/S mappé et d'espace réservé, et le reste des 25 % espace pour la carte mémoire précédente (36 bits). Le schéma de la carte mémoire est :
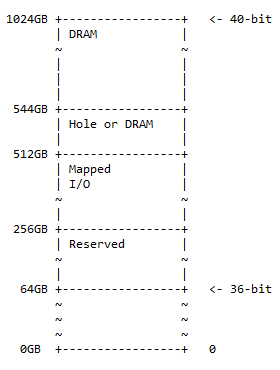
La taille du trou est de 544 – 512 = 32 Go. En pratique, on peut rencontrer la situation suivante :
- 0x10 0000 0000 – 0x3F FFFF FFFF ; réservé. 192 Go d'espace d'adressage sont réservés pour une utilisation future.
- 0x40 0000 0000 – 0x7F FFFF FFFF ; cartographié. E/S 256 Go d'espace d'adressage sont disponibles pour les E/S mappées dynamiquement.
- 0x80 0000 0000 – 0x87 FFFF FFFF ; trou ou DRAM. 32 Go d'espace d'adressage peuvent contenir l'un des éléments suivants :
- Trou pour activer le partitionnement du périphérique DRAM (comme décrit dans la discussion suivante)
- DRACHME
- 0x88 0000 0000 – 0xFF FFFF FFFF ; DRACHME. 480 Go d'espace d'adressage pour la DRAM.
Note : De 36 bits à 40 bits, c'est un ajout de 4 bits au côté le plus significatif de 36 bits.
Trou DRAM
Dans la carte mémoire au-delà de 32 bits, il s'agit soit d'un trou de DRAM, soit d'une continuation de la DRAM par le haut. Lorsqu'il s'agit d'un trou, il doit être apprécié comme suit : Le trou DRAM fournit un moyen de partitionner un grand périphérique DRAM en plusieurs plages d'adresses. Le trou DRAM facultatif est proposé au début de la limite supérieure de l’adresse DRAM. Cela permet un schéma de décodage simplifié lors du partitionnement d'un périphérique DRAM de grande capacité sur la région physiquement adressée inférieure.
Par exemple, une partie DRAM de 64 Go est subdivisée en trois régions, les décalages d'adresse étant effectués par une simple soustraction dans les bits d'adresse de poids fort, comme suit :
| Tableau 6.42.1 Exemple de partitionnement de DRAM de 64 Go avec des trous |
|||
|---|---|---|---|
| Adresses physiques dans le SoC | Compenser | Adresse DRAM interne | |
| 2 Go (carte 32 bits) | 0x00 8000 0000 – 0x00 FFFF FFFF | -0x00 8000 0000 | 0x00 0000 0000 – 0x00 7FFF FFFF |
| 30 Go (carte 36 bits) | 0x08 8000 0000 – 0x0F FFFF FFFF | -0x08 0000 0000 | 0x00 8000 0000 – 0x07 FFFF FFFF |
| 32 Go (carte 40 bits) | 0x88 0000 0000 – 0x8F FFFF FFFF | -0x80 0000 0000 | 0x08 0000 0000 – 0x0F FFFF FFFF |
Cartes de mémoire adressées 44 bits et 48 bits proposées pour les processeurs ARM
Supposons qu'un ordinateur personnel dispose de 1 024 Go (= 1 To) de mémoire ; c'est trop de mémoire. Ainsi, les cartes mémoire adressées 44 bits et 48 bits pour les processeurs ARM de 16 To et 256 To, respectivement, ne sont que des propositions pour les futurs besoins informatiques. En fait, ces propositions pour les processeurs ARM suivent la même division de mémoire par rapport que les cartes mémoire précédentes. C'est-à-dire : 50 % de DRAM avec un trou facultatif, 25 % d'espace d'E/S mappé et d'espace réservé, et le reste des 25 % d'espace pour la carte mémoire précédente.
Les cartes mémoire adressées 52 bits, 56 bits, 60 bits et 64 bits restent à proposer pour l'ARM 64 bits dans un avenir lointain. Si les scientifiques de l’époque trouvent encore utile le partage 50 : 25 : 25 de l’ensemble de l’espace mémoire, ils maintiendront ce rapport.
Note : SoC signifie System-on-Chip qui fait référence aux circuits de la puce µP qui autrement n'auraient pas été là.
La SRAM ou Static Random Access Memory est plus rapide que la DRAM plus traditionnelle, mais nécessite plus de surface de silicium. La SRAM ne nécessite pas de rafraîchissement. Le lecteur peut imaginer la RAM comme la SRAM.
6.43 Modes d'adressage du langage assembleur pour ARM 64
ARM est une architecture de chargement/stockage qui nécessite que les données soient chargées de la mémoire vers un registre du processeur avant qu'un traitement tel qu'une opération logique arithmétique puisse avoir lieu avec elle. Une instruction ultérieure stocke le résultat dans la mémoire. Bien que cela puisse sembler un pas en arrière par rapport aux architectures x86 et x64 ultérieures, qui opèrent directement sur les opérandes de la mémoire en une seule instruction, en pratique, l'approche chargement/stockage permet d'effectuer plusieurs opérations séquentielles à grande vitesse sur un opérande une fois qu'il est chargé dans l'un des nombreux registres du processeur.
Le format du langage assembleur ARM présente des similitudes et des différences avec la série x64 (x86).
- Compenser : Une constante signée peut être ajoutée au registre de base. Le décalage est saisi dans le cadre de l'instruction. Par exemple : ldr x0, [rx, #10] charge r0 avec le mot à l'adresse r1+10.
- Registre : Un incrément non signé stocké dans un registre peut être ajouté ou soustrait de la valeur dans un registre de base. Par exemple : ldr r0, [x1, x2] charge r0 avec le mot à l'adresse x1+x2. L'un ou l'autre des registres peut être considéré comme le registre de base.
- Registre à l'échelle : Un incrément dans un registre est décalé vers la gauche ou la droite d'un nombre spécifié de positions de bits avant d'être ajouté ou soustrait de la valeur du registre de base. Par exemple : ldr x0, [x1, x2, lsl #3] charge r0 avec le mot à l'adresse r1+(r2×8). Le décalage peut être un décalage logique vers la gauche ou la droite (lsl ou lsr) qui insère des bits nuls dans les positions de bits libérées ou un décalage arithmétique vers la droite (asr) qui réplique le bit de signe dans les positions libérées.
Lorsque deux opérandes sont impliqués, la destination précède (à gauche) la source (il existe quelques exceptions à cela). Les opcodes du langage assembleur ARM ne sont pas sensibles à la casse.
Mode d'adressage ARM64 immédiat
Exemple:
mouvement r0, #0xFF000000 ; Chargez la valeur 32 bits FF000000h dans r0
Une valeur décimale est sans 0x mais est toujours précédée de #.
S'inscrire directement
Exemple:
déplacement x0, x1 ; Copier x1 vers x0
Inscription indirecte
Exemple:
chaîne x0, [x3] ; Stockez x0 à l'adresse dans x3
Enregistrement indirect avec compensation
Exemples:
ldr x0, [x1, #32] ; Chargez r0 avec la valeur à l'adresse [r1+32] ; r1 est le registre de base
chaîne x0, [x1, #4] ; Stockez r0 à l'adresse [r1+4] ; r1 est le registre de base ; les nombres sont en base 10
Registre indirect avec décalage (pré-incrémenté)
Exemples:
ldrx0, [x1, #32] ! ; Chargez r0 avec [r1+32] et mettez à jour r1 vers (r1+32)
force x0, [x1, #4] ! ; Stockez r0 dans [r1+4] et mettez à jour r1 vers (r1+4)
Notez l’utilisation du « ! » symbole.
Registre indirect avec décalage (post-incrémenté)
Exemples:
ldrx0, [x1], #32 ; Chargez [x1] sur x0, puis mettez à jour x1 vers (x1+32)
chaîne x0, [x1], #4 ; Stockez x0 dans [x1], puis mettez à jour x1 vers (x1+4)
Double registre indirect
L'adresse de l'opérande est la somme d'un registre de base et d'un registre d'incrémentation. Les noms de registres sont entourés de crochets.
Exemples:
ldr x0, [x1, x2] ; Charger x0 avec [x1+x2]
str x0, [rx, x2] ; Stocker x0 dans [x1+x2]
Mode d'adressage relatif
En mode d'adressage relatif, l'instruction efficace est l'instruction suivante dans le compteur de programme, plus un index. L'indice peut être positif ou négatif.
Exemple:
ldr x0, [pc, #24]
Cela signifie le registre de chargement X0 avec le mot pointé par le contenu du PC plus 24.
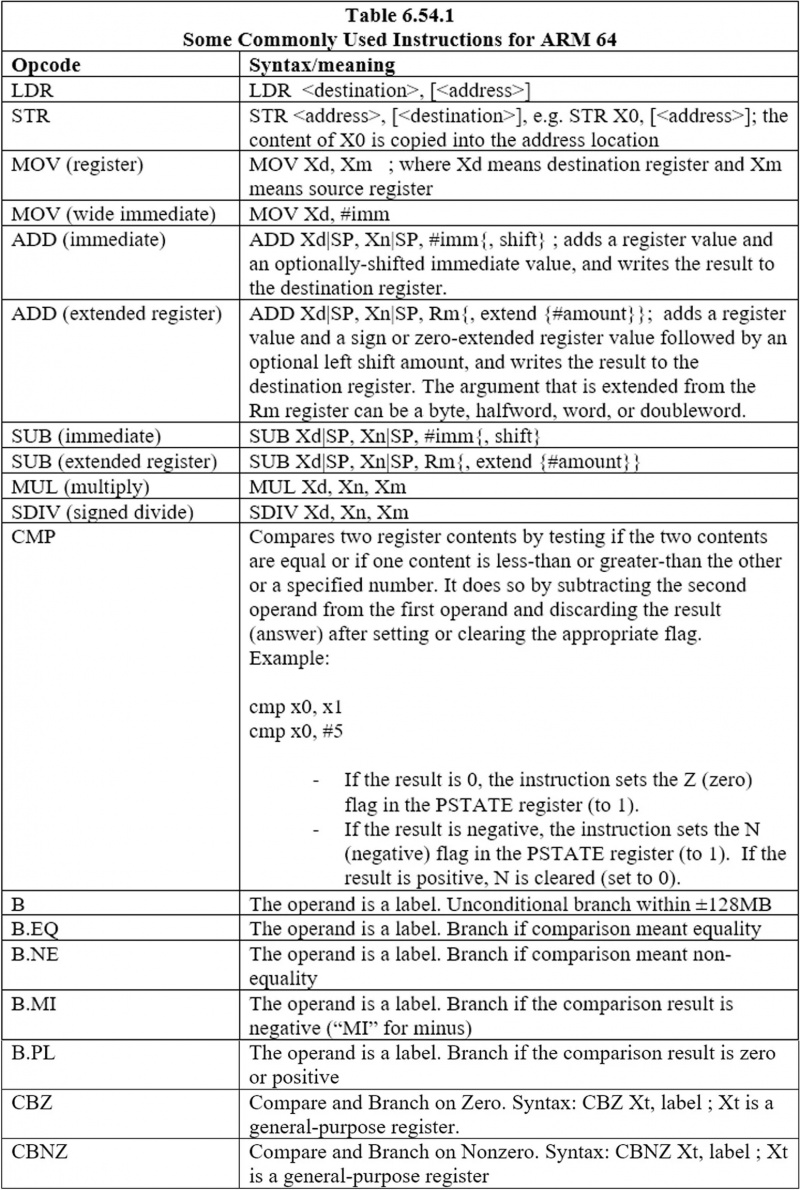
6.44 Quelques instructions couramment utilisées pour ARM 64
Voici les instructions couramment utilisées :
6.45 Boucle
Illustration
Le code suivant continue d'ajouter la valeur du registre X10 à la valeur de X9 jusqu'à ce que la valeur de X8 soit nulle. Supposons que toutes les valeurs sont des nombres entiers. La valeur dans X8 est soustraite de 1 à chaque itération :
boucle:
CBZ X8, sauter
AJOUTER X9, X9, X10 ; le premier X9 est la destination et le deuxième X9 est la source
SOUS-X8, X8, #1 ; le premier X8 est la destination et le deuxième X8 est la source
Boucle B
sauter:
Comme pour le 6502 µP et le X64 µP, l'étiquette dans l'ARM 64 µP commence au début de la ligne. Le reste des instructions commence quelques espaces après le début de la ligne. Avec x64 et ARM 64, l'étiquette est suivie de deux points et d'une nouvelle ligne. Alors qu'avec 6502, l'étiquette est suivie d'une instruction après un espace. Dans le code précédent, la première instruction qui est « CBZ X8, skip » signifie que si la valeur dans X8 est zéro, continuez avec l'étiquette « skip : », en sautant les instructions intermédiaires et en continuant avec le reste des instructions ci-dessous. 'sauter:'. La « boucle B » est un saut inconditionnel vers l’étiquette « boucle ». Tout autre nom d'étiquette peut être utilisé à la place de « loop ».
Ainsi, comme avec le 6502 µP, utilisez les instructions de branchement pour avoir une boucle avec l'ARM 64.
6.46 Entrée/Sortie ARM 64
Tous les périphériques ARM (ports internes) sont mappés en mémoire. Cela signifie que l'interface de programmation est un ensemble de registres adressés en mémoire (ports internes). L'adresse d'un tel registre est un décalage par rapport à une adresse de base mémoire spécifique. Ceci est similaire à la façon dont le 6502 effectue les entrées/sorties. ARM n'a pas la possibilité d'espace d'adressage d'E/S séparé.
6.47 Pile d'ARM 64
L'ARM 64 dispose d'une pile en mémoire (RAM) de la même manière que les 6502 et x64. Cependant, avec l'ARM64, il n'y a pas d'opcode push ou pop. La pile dans ARM 64 croît également vers le bas. L'adresse dans le pointeur de pile pointe juste après le dernier octet de la dernière valeur placée dans la pile.
La raison pour laquelle il n'y a pas d'opcode pop ou push générique pour l'ARM64 est que l'ARM 64 gère sa pile en groupes de 16 octets consécutifs. Toutefois, les valeurs existent dans des groupes d'octets d'un octet, deux octets, quatre octets et 8 octets. Ainsi, une valeur peut être placée dans la pile, et le reste des emplacements (emplacements d'octets) pour compenser 16 octets est complété par des octets factices. Cela présente l'inconvénient de gaspiller de la mémoire. Une meilleure solution consiste à remplir l'emplacement de 16 octets avec des valeurs plus petites et à faire écrire du code par le programmeur qui suit l'origine des valeurs dans l'emplacement de 16 octets (registres). Ce code supplémentaire est également nécessaire pour extraire les valeurs. Une alternative consiste à remplir deux registres à usage général de 8 octets avec les différentes valeurs, puis à envoyer le contenu des deux registres de 8 octets à une pile. Un code supplémentaire est encore nécessaire ici pour suivre les petites valeurs spécifiques qui entrent dans la pile et la quittent.
Le code suivant stocke quatre données de 4 octets dans la pile :
str w0, [sp, #-4] !
str w1, [sp, #-8] !
str w2, [sp, #-12] !
str w3, [sp, #-16] !
Les quatre premiers octets (w) des registres – x0, x1, x2 et x3 – sont envoyés à 16 emplacements d'octets consécutifs dans la pile. Notez l’utilisation de « str » et non de « push ». Notez le symbole d'exclamation à la fin de chaque instruction. Étant donné que la pile mémoire croît vers le bas, la première valeur de quatre octets commence à une position située moins quatre octets en dessous de la position précédente du pointeur de pile. Le reste des valeurs de quatre octets suit, en descendant. Le segment de code suivant fera l'équivalent correct (et dans l'ordre) de l'extraction des quatre octets :
ldr w3, [sp], #0
ldr w2, [sp], #4
ldr w1, [sp], #8
ldr w0, [sp], #12
Notez l'utilisation de l'opcode ldr au lieu de pop. Notez également que le symbole d'exclamation n'est pas utilisé ici.
Tous les octets de X0 (8 octets) et X1 (8 octets) peuvent être envoyés à l'emplacement de 16 octets dans la pile comme suit :
stp x0, x1, [sp, #-16] ! ; 8 + 8 = 16
Dans ce cas, les registres x2 (w2) et x3 (w3) ne sont pas nécessaires. Tous les octets recherchés se trouvent dans les registres X0 et X2. Notez l'opcode stp pour stocker les paires de contenus de registre dans la RAM. Notez également le symbole d'exclamation. L'équivalent pop est :
ldp x0, x1, [sp], #0
Il n'y a pas de signe d'exclamation pour cette instruction. Notez l'opcode LDP au lieu de LDR pour charger deux emplacements de données consécutifs de la mémoire vers deux registres µP. N'oubliez pas non plus que la copie de la mémoire vers un registre µP est un chargement, à ne pas confondre avec le chargement d'un fichier du disque vers la RAM, et que la copie d'un registre µP vers la RAM est un stockage.
6.48 Sous-programme
Un sous-programme est un bloc de code qui exécute une tâche, éventuellement basée sur certains arguments et qui renvoie éventuellement un résultat. Par convention, les registres R0 à R3 (quatre registres) sont utilisés pour transmettre les arguments (paramètres) à un sous-programme, et R0 est utilisé pour renvoyer un résultat à l'appelant. Un sous-programme nécessitant plus de 4 entrées utilise la pile pour les entrées supplémentaires. Pour appeler un sous-programme, utilisez le lien ou l'instruction de branchement conditionnel. La syntaxe de l'instruction de lien est :
Etiquette BL
Où BL est l'opcode et l'étiquette représente le début (adresse) du sous-programme. Cette branche est inconditionnelle, en avant ou en arrière dans les 128 Mo. La syntaxe de l’instruction de branchement conditionnel est :
Étiquette B.cond
Où cond est la condition, par exemple eq (égal) ou ne (différent). Le programme suivant possède le sous-programme doadd qui additionne les valeurs de deux arguments et renvoie un résultat dans R0 :
Sous-programme ZONE, CODE, LECTURE SEULEMENT ; Nommez ce bloc de code
ENTRÉE ; Marquer la première instruction à exécuter
démarrer MOV r0, #10 ; Configurer les paramètres
MOV r1, #3
BL doadd ; Appeler le sous-programme
arrêter MOV r0, #0x18 ; angel_SWIreason_ReportException
LDR r1, =0x20026 ; ADP_Stopped_ApplicationExit
SVC #0x123456 ; Semi-hébergement ARM (anciennement SWI)
doadd AJOUTER r0, r0, r1 ; Code de sous-programme
BX gdr ; Retour du sous-programme
;
FIN ; Marquer la fin du fichier
Les nombres à ajouter sont le décimal 10 et le décimal 3. Les deux premières lignes de ce bloc de code (programme) seront expliquées plus tard. Les trois lignes suivantes envoient 10 au registre R0 et 3 au registre R1, et appellent également le sous-programme doadd. Le « doadd » est l'étiquette qui contient l'adresse du début du sous-programme.
Le sous-programme se compose de seulement deux lignes. La première ligne ajoute le contenu 3 de R au contenu 10 de R0 ce qui permet le résultat de 13 dans R0. La deuxième ligne avec l'opcode BX et l'opérande LR revient du sous-programme au code de l'appelant.
DROITE
L'opcode RET dans ARM 64 traite toujours du sous-programme, mais fonctionne différemment de RTS dans 6502 ou RET sur x64, ou de la combinaison « BX LR » dans ARM 64. Dans ARM 64, la syntaxe de RET est :
DROITE {Xn}
Cette instruction donne la possibilité au programme de continuer avec un sous-programme qui n'est pas le sous-programme appelant, ou simplement de continuer avec une autre instruction et son segment de code suivant. Xn est un registre à usage général qui contient l'adresse à laquelle le programme doit continuer. Cette instruction bifurque sans condition. La valeur par défaut est le contenu de X30 si Xn n'est pas donné.
Norme d’appel de procédure
Si le programmeur souhaite que son code interagisse avec un code écrit par quelqu'un d'autre ou avec un code produit par un compilateur, le programmeur doit se mettre d'accord avec la personne ou le rédacteur du compilateur sur les règles d'utilisation des registres. Pour l’architecture ARM, ces règles sont appelées Procedure Call Standard ou PCS. Ce sont des accords entre deux ou trois parties. Le PCS précise les éléments suivants :
- Quels registres µP sont utilisés pour transmettre les arguments dans la fonction (sous-programme)
- Quels registres µP sont utilisés pour renvoyer le résultat à la fonction qui effectue l'appel, connue sous le nom d'appelant
- Le µP qui enregistre la fonction appelée, connue sous le nom d'appelé, peut corrompre
- Quels µP enregistrent l'appelé ne peut pas corrompre
6.49 Interruptions
Il existe deux types de circuits de contrôleur d'interruption disponibles pour le processeur ARM :
- Contrôleur d'interruption standard : le gestionnaire d'interruption détermine quel périphérique nécessite une maintenance en lisant un registre bitmap de périphérique dans le contrôleur d'interruption.
- Contrôleur d'interruption vectorielle (VIC) : hiérarchise les interruptions et simplifie la détermination du périphérique à l'origine de l'interruption. Après avoir associé une priorité et une adresse de gestionnaire à chaque interruption, le VIC envoie un signal d'interruption au processeur uniquement si la priorité d'une nouvelle interruption est supérieure à celle du gestionnaire d'interruption en cours d'exécution.
Note : L'exception fait référence à une erreur. Les détails du contrôleur d'interruption vectorielle pour l'ordinateur ARM 32 bits sont les suivants (64 bits est similaire) :
| Tableau 6.49.1 Exception/interruption de vecteur ARM pour ordinateur 32 bits |
|||
|---|---|---|---|
| Exception/Interruption | Main courte | Adresse | Adresse élevée |
| Réinitialiser | RÉINITIALISER | 0x00000000 | 0xffff0000 |
| Instruction non définie | FNUD | 0x00000004 | 0xffff0004 |
| Interruption logicielle | SWI | 0x00000008 | 0xffff0008 |
| Abandon de la prélecture | pabt | 0x0000000C | 0xffff000C |
| Date d'avortement | DABT | 0x00000010 | 0xffff0010 |
| Réservé | – | 0x00000014 | 0xffff0014 |
| Demande d'interruption | IRQ | 0x00000018 | 0xffff0018 |
| Demande d'interruption rapide | FIQ | 0x0000001C | 0xffff001C |
Cela ressemble à la disposition de l'architecture 6502 où INM , BR , et IRQ peut avoir des pointeurs sur la page zéro et les routines correspondantes sont en mémoire (ROM OS). De brèves descriptions des lignes du tableau précédent sont les suivantes :
RÉINITIALISER
Cela se produit lorsque le processeur démarre. Il initialise le système et configure les piles pour différents modes de processeur. Il s'agit de l'exception ayant la priorité la plus élevée. Lors de l'entrée dans le gestionnaire de réinitialisation, le CPSR est en mode SVC et les bits IRQ et FIQ sont définis sur 1, masquant toute interruption.
DATE DE L'AVORTEMENT
La deuxième priorité la plus élevée. Cela se produit lorsque nous essayons de lire/écrire dans une adresse invalide ou d'accéder à une mauvaise autorisation d'accès. Lors de l'entrée dans le gestionnaire d'abandon de données, les IRQ seront désactivées (jeu de bits I 1) et le FIQ sera activé. Les IRQ sont masquées, mais les FIQ restent démasqués.
FIQ
L'interruption la plus prioritaire, IRQ et FIQ, est désactivée jusqu'à ce que FIQ soit traité.
IRQ
L'interruption de haute priorité, le gestionnaire d'IRQ, est entrée uniquement s'il n'y a pas d'abandon de FIQ et de données en cours.
Abandon de la pré-récupération
Ceci est similaire à l'abandon des données, mais se produit en cas d'échec de la récupération d'adresse. Lors de l'entrée dans le gestionnaire, les IRQ sont désactivées mais les FIQ restent activés et peuvent se produire lors d'un abandon de pré-lecture.
SWI
Une exception d'interruption logicielle (SWI) se produit lorsque l'instruction SWI est exécutée et qu'aucune des autres exceptions de priorité plus élevée n'a été signalée.
Instruction non définie
L’exception Instruction non définie se produit lorsqu’une instruction qui ne figure pas dans le jeu d’instructions ARM ou Thumb atteint l’étape d’exécution du pipeline et qu’aucune des autres exceptions n’a été signalée. Il s’agit de la même priorité que SWI, car une opération peut se produire à la fois. Cela signifie que l’instruction en cours d’exécution ne peut pas être à la fois une instruction SWI et une instruction indéfinie.
Gestion des exceptions ARM
Les événements suivants se produisent lorsqu'une exception se produit :
- Stockez le CPSR dans le SPSR du mode exception.
- Le PC est stocké dans le LR du mode exception.
- Le registre de liaison est défini sur une adresse spécifique en fonction de l'instruction en cours. Par exemple : pour ISR, LR = dernière instruction exécutée + 8.
- Mettez à jour le CPSR concernant l’exception.
- Définissez le PC sur l'adresse du gestionnaire d'exceptions.
6.5 Instructions et données
Les données font référence aux variables (étiquettes avec leurs valeurs) et aux tableaux et autres structures similaires aux tableaux. La chaîne est comme un tableau de caractères. Un tableau d’entiers est vu dans l’un des chapitres précédents. Les instructions font référence aux opcodes et à leurs opérandes. Un programme peut être écrit avec les opcodes et les données mélangés dans une section continue de mémoire. Cette approche présente des inconvénients mais n'est pas recommandée.
Un programme doit d'abord être écrit avec les instructions, suivies des données (le pluriel de donnée est donnée). La séparation entre les instructions et les données ne peut être que de quelques octets. Pour un programme, les instructions et les données peuvent se trouver dans une ou deux sections distinctes de la mémoire.
6.6 L'architecture de Harvard
L'un des premiers ordinateurs s'appelle Harvard Mark I (1944). Une architecture Harvard stricte utilise un espace d'adressage pour les instructions du programme et un autre espace d'adressage distinct pour les données. Cela signifie qu'il existe deux mémoires distinctes. Ce qui suit montre l'architecture :
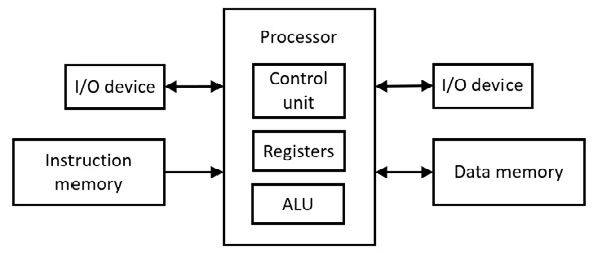
Figure 6.71 Architecture de Harvard
L'unité de contrôle effectue le décodage des instructions. L'unité arithmétique et logique (ALU) effectue les opérations arithmétiques avec une logique combinatoire (portes). ALU effectue également les opérations logiques (par exemple le décalage).
Avec le microprocesseur 6502, une instruction va d'abord au microprocesseur (unité de contrôle) avant que la donnée (singulier pour les données) ne passe au registre µP avant qu'ils n'interagissent. Cela nécessite au moins deux impulsions d'horloge et il ne s'agit pas d'un accès simultané à l'instruction et à la donnée. D'autre part, l'architecture Harvard fournit un accès simultané aux instructions et aux données, l'instruction et la donnée entrant dans le µP en même temps (opcode vers l'unité de contrôle et donnée vers le registre µP), économisant ainsi au moins une impulsion d'horloge. C'est une forme de parallélisme. Cette forme de parallélisme est utilisée dans le cache matériel des cartes mères modernes (voir la discussion suivante).
6.7 Mémoire cache
La mémoire cache (RAM) est une région de mémoire à grande vitesse (par rapport à la vitesse de la mémoire principale) qui stocke temporairement les instructions ou les données du programme pour une utilisation ultérieure. La mémoire cache fonctionne plus rapidement que la mémoire principale. Habituellement, ces instructions ou éléments de données sont récupérés de la mémoire principale récente et seront probablement à nouveau nécessaires sous peu. L'objectif principal de la mémoire cache est d'augmenter la vitesse d'accès répété aux mêmes emplacements de mémoire principale. Pour être efficace, l'accès aux éléments mis en cache doit être beaucoup plus rapide que l'accès à la source originale des instructions ou des données, appelée Backing Store.
Lorsque la mise en cache est utilisée, chaque tentative d'accès à un emplacement de mémoire principale commence par une recherche dans le cache. Si l'élément demandé est présent, le processeur le récupère et l'utilise immédiatement. C’est ce qu’on appelle un Cache Hit. Si la recherche dans le cache échoue (manque de cache), l'instruction ou l'élément de données doit être récupéré du magasin de sauvegarde (mémoire principale). Lors du processus de récupération de l'élément demandé, une copie est ajoutée au cache pour une utilisation anticipée dans un avenir proche.
Unité de gestion de la mémoire
L'unité de gestion de la mémoire (MMU) est un circuit qui gère la mémoire principale et les registres de mémoire associés sur la carte mère. Dans le passé, il s’agissait d’un circuit intégré séparé sur la carte mère ; mais aujourd'hui, il fait généralement partie du microprocesseur. La MMU doit également gérer le cache (circuit) qui fait également partie du microprocesseur aujourd'hui. Le circuit cache était autrefois un circuit intégré distinct.
RAM statique
La RAM statique (SRAM) a un temps d'accès nettement plus rapide que la DRAM, mais au détriment de circuits beaucoup plus complexes. Les cellules binaires SRAM occupent beaucoup plus de place sur la puce du circuit intégré que les cellules d'un dispositif DRAM capable de stocker une quantité équivalente de données. La mémoire principale (RAM) est généralement constituée de DRAM (Dynamic RAM).
La mémoire cache améliore les performances de l'ordinateur car de nombreux algorithmes exécutés par les systèmes d'exploitation et les applications présentent la localité de référence. La localité de référence fait référence à la réutilisation de données récemment consultées. C'est ce qu'on appelle la localité temporelle. Sur une carte mère moderne, la mémoire cache se trouve dans le même circuit intégré que le microprocesseur. La mémoire principale (DRAM) est éloignée et accessible via les bus. La localité de référence fait également référence à la localité spatiale. La localité spatiale est liée à la vitesse plus élevée d’accès aux données en raison de la proximité physique.
En règle générale, les régions de mémoire cache sont petites (en nombre d'emplacements d'octets) par rapport à la mémoire de sauvegarde (mémoire principale). Les dispositifs de mémoire cache sont conçus pour une vitesse maximale, ce qui signifie généralement qu'ils sont plus complexes et plus coûteux par bit que la technologie de stockage de données utilisée dans le magasin de sauvegarde. En raison de leur taille limitée, les dispositifs de mémoire cache ont tendance à se remplir rapidement. Lorsqu'un cache ne dispose pas d'un emplacement disponible pour stocker une nouvelle entrée, une entrée plus ancienne doit être supprimée. Le contrôleur de cache utilise une politique de remplacement du cache pour sélectionner quelle entrée de cache sera écrasée par la nouvelle entrée.
L'objectif de la mémoire cache du microprocesseur est de maximiser le pourcentage d'accès au cache au fil du temps, fournissant ainsi le taux d'exécution d'instructions soutenu le plus élevé. Pour atteindre cet objectif, la logique de mise en cache doit déterminer quelles instructions et données seront placées dans le cache et conservées pour une utilisation future proche.
La logique de mise en cache d’un processeur ne garantit pas qu’un élément de données mis en cache sera un jour réutilisé une fois inséré dans le cache.
La logique de la mise en cache repose sur la probabilité qu'en raison de la localisation temporelle (répétition dans le temps) et spatiale (espace), il y a de très bonnes chances que les données mises en cache soient accessibles dans un avenir proche. Dans les implémentations pratiques sur les processeurs modernes, les accès au cache se produisent généralement sur 95 à 97 % des accès mémoire. Étant donné que la latence de la mémoire cache ne représente qu'une petite fraction de la latence de la DRAM, un taux de réussite élevé du cache entraîne une amélioration substantielle des performances par rapport à une conception sans cache.
Un peu de parallélisme avec le cache
Comme mentionné précédemment, un bon programme en mémoire a les instructions séparées des données. Dans certains systèmes de cache, il y a un circuit de cache à « gauche » du processeur et un autre circuit de cache à « droite » du processeur. Le cache de gauche gère les instructions d'un programme (ou d'une application) et le cache de droite gère les données du même programme (ou de la même application). Cela conduit à une meilleure augmentation de la vitesse.
6.8 Processus et threads
Les ordinateurs CISC et RISC disposent de processus. Un processus est sur le logiciel. Un programme en cours d'exécution (en cours d'exécution) est un processus. Le système d'exploitation est livré avec ses propres programmes. Pendant que l'ordinateur fonctionne, les programmes du système d'exploitation qui permettent à l'ordinateur de fonctionner sont également en cours d'exécution. Ce sont des processus du système d’exploitation. L'utilisateur ou le programmeur peut écrire ses propres programmes. Lorsque le programme de l’utilisateur est en cours d’exécution, c’est un processus. Peu importe que le programme soit écrit en langage assembleur ou en langage de haut niveau comme C ou C++. Tous les processus (utilisateur ou OS) sont gérés par un autre processus appelé « planificateur ».
Un thread est comme un sous-processus appartenant à un processus. Un processus peut démarrer et se diviser en threads, puis continuer comme un seul processus. Un processus sans threads peut être considéré comme le thread principal. Les processus et leurs threads sont gérés par le même planificateur. Le planificateur lui-même est un programme lorsqu'il réside sur le disque du système d'exploitation. Lorsqu'il est exécuté en mémoire, le planificateur est un processus.
6.9 Multitraitement
Les threads sont gérés presque comme des processus. Le multitraitement signifie exécuter plusieurs processus en même temps. Il existe des ordinateurs dotés d’un seul microprocesseur. Il existe des ordinateurs équipés de plusieurs microprocesseurs. Avec un seul microprocesseur, les processus et/ou threads utilisent le même microprocesseur de manière entrelacée (ou temporelle). Cela signifie qu'un processus utilise le processeur et s'arrête sans terminer. Un autre processus ou thread utilise le processeur et s'arrête sans terminer. Ensuite, un autre processus ou thread utilise le microprocesseur et s'arrête sans terminer. Cela continue jusqu'à ce que tous les processus et threads mis en file d'attente par le planificateur aient eu une part du processeur. C'est ce qu'on appelle le multitraitement simultané.
Lorsqu’il y a plus d’un microprocesseur, il y a un multitraitement parallèle, par opposition à la concurrence. Dans ce cas, chaque processeur exécute un processus ou un thread particulier, différent de celui qu’exécute l’autre processeur. Tous les processeurs d'une même carte mère exécutent leurs différents processus et/ou différents threads en même temps en multitraitement parallèle. Les processus et threads en multitraitement parallèle sont toujours gérés par le planificateur. Le multitraitement parallèle est plus rapide que le multitraitement simultané.
À ce stade, le lecteur peut se demander en quoi le traitement parallèle est plus rapide que le traitement simultané. En effet, les processeurs partagent (doivent utiliser à des moments différents) la même mémoire et les mêmes ports d'entrée/sortie. Eh bien, avec l'utilisation du cache, le fonctionnement global de la carte mère est plus rapide.
6.10 Radiomessagerie
L'unité de gestion de la mémoire (MMU) est un circuit proche du microprocesseur ou dans la puce du microprocesseur. Il gère la carte mémoire ou la pagination et d'autres problèmes de mémoire. Ni le 6502 µP ni l'ordinateur Commodore-64 n'ont de MMU en soi (bien qu'il y ait encore une certaine gestion de la mémoire dans le Commodore-64). Le Commodore-64 gère la mémoire par pagination où chaque page fait 256 dix octets de long (100 16 octets de long). Il n'était pas obligatoire qu'il gère la mémoire par pagination. Il pourrait toujours avoir simplement une carte mémoire, puis des programmes qui s'intègrent dans leurs différentes zones désignées. Eh bien, la pagination est un moyen de fournir une utilisation efficace de la mémoire sans avoir de nombreuses sections de mémoire qui ne peuvent pas contenir de données ou de programme.
L'architecture informatique x86 386 a été lancée en 1985. Le bus d'adresses a une largeur de 32 bits. Donc au total 2 32 = 4 294 967 296 d'espace d'adressage sont possibles. Cet espace d'adressage est divisé en 1 048 576 pages = 1 024 Ko de pages. Avec ce nombre de pages, une page comprend 4 096 octets = 4 Ko. Le tableau suivant présente les pages d'adresses physiques pour l'architecture x86 32 bits :
| Tableau 6.10.1 Pages adressables physiquement pour l'architecture x86 |
||
|---|---|---|
| Adresses en base 16 | Pages | Adresses en base 10 |
| FFFFF000 – FFFFFFFF | Page 1 048 575 | 4 294 963 200 – 4 294 967 295 |
| FFFFE000 – FFFFEFFF | Page 1 044 479 | 4 294 959 104 – 4 294 963 199 |
| FFFFD000 – FFFFDFFF | Page 1 040 383 | 4 294 955 008 – 4 294 959 103 |
| | | | |
| | | |
| | | |
| 00002000 – 00002FFF | Page 2 | 8 192 – 12 288 |
| 00001000 – 00001FFF | Page 1 | 4 096 – 8 191 |
| 00000000 – 00000FFF | Page 0 | 0 – 4 095 |
Aujourd’hui, une application se compose de plusieurs programmes. Un programme peut prendre moins d'une page (moins de 4 096) ou deux pages ou plus. Ainsi, une application peut prendre une ou plusieurs pages, chaque page faisant 4096 octets. Différentes personnes peuvent rédiger une candidature, chaque personne étant affectée à une ou plusieurs pages.
Notez que la page 0 va de 00000000H à 00000FFF
la page 1 va de 00001000H à 00001FFFH, la page 2 va de 00002000 H – 00002FFF H , et ainsi de suite. Pour un ordinateur 32 bits, il existe deux registres 32 bits dans le processeur pour l'adressage physique des pages : un pour l'adresse de base et l'autre pour l'adresse d'index. Pour accéder aux emplacements d'octets de la page 2, par exemple, le registre de l'adresse de base doit être 00002 H qui sont les 20 premiers bits (en partant de la gauche) pour les adresses de départ de la page 2. Le reste des bits dans la plage de 000 H à FFF H sont dans le registre appelé « registre d’index ». Ainsi, tous les octets de la page sont accessibles en incrémentant simplement le contenu du registre d'index à partir de 000. H à FFF H . Le contenu du registre d'index est ajouté au contenu qui ne change pas dans le registre de base pour obtenir l'adresse effective. Ce schéma d'adressage d'index est vrai pour les autres pages.
Cependant, ce n’est pas vraiment ainsi que le programme en langage assembleur est écrit pour chaque page. Pour chaque page, le programmeur écrit le code à partir de la page 000 H vers la page FFF H . Étant donné que le code des différentes pages est connecté, le compilateur utilise l'adressage d'index pour connecter toutes les adresses associées dans les différentes pages. Par exemple, en supposant que la page 0, la page 1 et la page 2 concernent une seule application et que chacune comporte le 555 H adresses connectées entre elles, le compilateur compile de telle manière que lorsque 555 H de la page 0 doit être consultée, 00000 H sera dans le registre de base et 555 H sera dans le registre d'index. Quand 555 H de la page 1 doit être consulté, 00001 H sera dans le registre de base et 555 H sera dans le registre d'index. Quand 555 H de la page 2 doit être consulté, 00002 H sera dans le registre de base et 555H sera dans le registre d'index. Ceci est possible car les adresses peuvent être identifiées à l'aide d'étiquettes (variables). Les différents programmeurs doivent se mettre d'accord sur le nom des étiquettes à utiliser pour les différentes adresses de connexion.
Mémoire virtuelle des pages
La pagination, comme décrit précédemment, peut être modifiée pour augmenter la taille de la mémoire dans une technique appelée « Mémoire virtuelle de page ». En supposant que toutes les pages de la mémoire physique, comme décrit précédemment, contiennent quelque chose (des instructions et des données), toutes les pages ne sont pas actuellement actives. Les pages qui ne sont pas actuellement actives sont envoyées sur le disque dur et sont remplacées par les pages du disque dur qui doivent être exécutées. De cette façon, la taille de la mémoire augmente. Au fur et à mesure que l'ordinateur continue de fonctionner, les pages qui deviennent inactives sont échangées avec les pages du disque dur qui peuvent toujours être les pages envoyées de la mémoire vers le disque. Tout cela est effectué par l'unité de gestion de la mémoire (MMU).
6.11 Problèmes
Il est conseillé au lecteur de résoudre tous les problèmes d'un chapitre avant de passer au chapitre suivant.
1) Donner les similitudes et les différences des architectures informatiques CISC et RISC. Nommez un exemple d'ordinateur SISC et RISC.
2) a) Quels sont les noms suivants pour l'ordinateur CISC en termes de bits : octet, mot, double mot, quadword et double quadword.
b) Quels sont les noms suivants pour l'ordinateur RISC en termes de bits : octet, demi-mot, mot et mot double.
c) Oui ou non. Les mots doubles et quadruples signifient-ils la même chose dans les architectures CISC et RISC ?
3 a) Pour x64, le nombre d'octets pour les instructions du langage assembleur va de quoi à quoi ?
b) Le nombre d'octets pour toutes les instructions en langage assembleur pour l'ARM 64 est-il fixe ? Si oui, quel est le nombre d’octets pour toutes les instructions ?
4) Répertoriez les instructions en langage assembleur les plus couramment utilisées pour x64 et leur signification.
5) Répertoriez les instructions en langage assembleur les plus couramment utilisées pour ARM 64 et leurs significations.
6) Dessinez un schéma fonctionnel étiqueté de l’ancienne architecture informatique de Harvard. Expliquez comment ses instructions et fonctionnalités de données sont utilisées dans le cache des ordinateurs modernes.
7) Faites la différence entre un processus et un thread et donnez le nom du processus qui gère les processus et les threads dans la plupart des systèmes informatiques.
8) Expliquez brièvement ce qu'est le multitraitement.
9) a) Expliquer la pagination applicable à l'architecture informatique x86 386 µP.
b) Comment modifier cette pagination pour augmenter la taille de la mémoire entière ?