Optimiser le code Python avec des outils de profilage
En configurant Google Colab pour optimiser le code Python avec des outils de profilage, nous commençons par configurer un environnement Google Colab. Si nous sommes nouveaux sur Colab, il s'agit d'une plate-forme cloud essentielle et puissante qui donne accès aux notebooks Jupyter et à une gamme de bibliothèques Python. Nous accédons à Colab en visitant (https://colab.research.google.com/) et en créant un nouveau notebook Python.
Importer les bibliothèques de profilage
Notre optimisation repose sur l'utilisation compétente de bibliothèques de profilage. Deux bibliothèques importantes dans ce contexte sont cProfile et line_profiler.
importer cProfil
importer profil_ligne
La bibliothèque « cProfile » est un outil Python intégré pour profiler le code, tandis que « line_profiler » est un package externe qui nous permet d'aller encore plus loin, en analysant le code ligne par ligne.
Dans cette étape, nous créons un exemple de script Python pour calculer la séquence de Fibonacci à l'aide d'une fonction récursive. Analysons ce processus plus en profondeur. La suite de Fibonacci est un ensemble de nombres dans lequel chaque nombre successif est la somme des deux nombres qui le précèdent. Cela commence généralement par 0 et 1, donc la séquence ressemble à 0, 1, 1, 2, 3, 5, 8, 13, 21, et ainsi de suite. Il s’agit d’une séquence mathématique couramment utilisée comme exemple en programmation en raison de sa nature récursive.
Nous définissons une fonction Python appelée « Fibonacci » dans la fonction récursive de Fibonacci. Cette fonction prend comme argument un entier « n », représentant la position dans la séquence de Fibonacci que nous voulons calculer. Nous voulons localiser le cinquième nombre de la séquence de Fibonacci, par exemple si « n » est égal à 5.
déf fibonacci ( n ) :
Ensuite, nous établissons un cas de base. Un cas de base en récursion est un scénario qui met fin aux appels et renvoie une valeur prédéterminée. Dans la séquence de Fibonacci, lorsque « n » vaut 0 ou 1, on connaît déjà le résultat. Les 0ème et 1er nombres de Fibonacci sont respectivement 0 et 1.
si n <= 1 :retour n
Cette instruction « if » détermine si « n » est inférieur ou égal à 1. Si c’est le cas, nous renvoyons « n » lui-même, car aucune récursion supplémentaire n’est nécessaire.
Calcul récursif
Si « n » dépasse 1, nous procédons au calcul récursif. Dans ce cas, nous devons trouver le « n »-ème nombre de Fibonacci en additionnant les « (n-1) » et « (n-2) » nombres de Fibonacci. Nous y parvenons en effectuant deux appels récursifs au sein de la fonction.
autre :retour fibonacci ( n - 1 ) + fibonacci ( n - 2 )
Ici, « fibonacci(n – 1) » calcule le « (n-1) »ème nombre de Fibonacci, et « fibonacci(n – 2) » calcule le « (n-2) »ème nombre de Fibonacci. Nous additionnons ces deux valeurs pour obtenir le nombre de Fibonacci souhaité à la position « n ».
En résumé, cette fonction « fibonacci » calcule récursivement les nombres de Fibonacci en divisant le problème en sous-problèmes plus petits. Il effectue des appels récursifs jusqu'à ce qu'il atteigne les cas de base (0 ou 1), renvoyant des valeurs connues. Pour tout autre « n », il calcule le nombre de Fibonacci en additionnant les résultats de deux appels récursifs pour « (n-1) » et « (n-2) ».
Bien que cette implémentation soit simple pour calculer les nombres de Fibonacci, elle n’est pas la plus efficace. Dans les étapes ultérieures, nous utiliserons les outils de profilage pour identifier et optimiser ses restrictions de performances afin de meilleurs temps d'exécution.
Profilage du code avec CProfile
Maintenant, nous profilons notre fonction « fibonacci » en employant « cProfile ». Cet exercice de profilage fournit un aperçu du temps consommé par chaque appel de fonction.
cprofileur = cProfil. Profil ( )cprofileur. activer ( )
résultat = fibonacci ( 30 )
cprofileur. désactiver ( )
cprofileur. print_stats ( trier = 'cumulatif' )
Dans ce segment, nous initialisons un objet « cProfile », activons le profilage, demandons la fonction « fibonacci » avec « n=30 », désactivons le profilage et affichons les statistiques triées par temps cumulé. Ce profilage initial nous donne un aperçu de haut niveau des fonctions qui consomment le plus de temps.
! pip installer line_profilerimporter cProfil
importer profil_ligne
déf fibonacci ( n ) :
si n <= 1 :
retour n
autre :
retour fibonacci ( n - 1 ) + fibonacci ( n - 2 )
cprofileur = cProfil. Profil ( )
cprofileur. activer ( )
résultat = fibonacci ( 30 )
cprofileur. désactiver ( )
cprofileur. print_stats ( trier = 'cumulatif' )
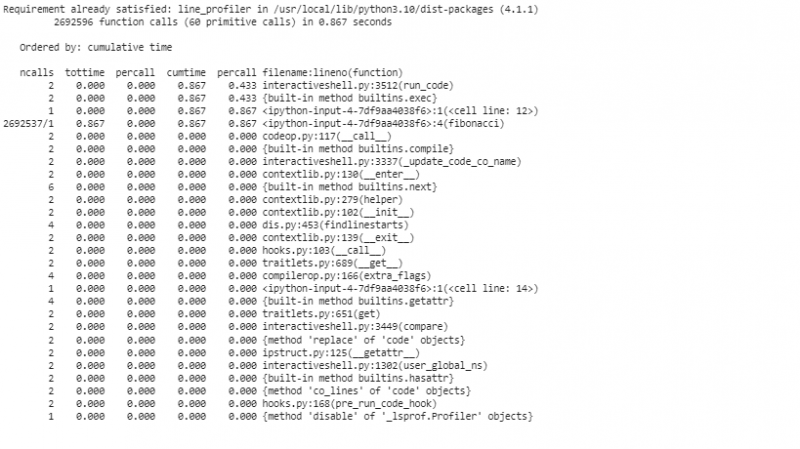
Pour profiler le code ligne par ligne avec line_profiler pour une analyse plus détaillée, nous utilisons le « line_profiler » pour segmenter notre code ligne par ligne. Avant d'utiliser « line_profiler », nous devons installer le package dans le référentiel Colab.
! pip installer line_profilerMaintenant que nous avons le « line_profiler » prêt, nous pouvons l'appliquer à notre fonction « fibonacci » :
%load_ext line_profilerdéf fibonacci ( n ) :
si n <= 1 :
retour n
autre :
retour fibonacci ( n - 1 ) + fibonacci ( n - 2 )
%lprun -f fibonacci fibonacci ( 30 )
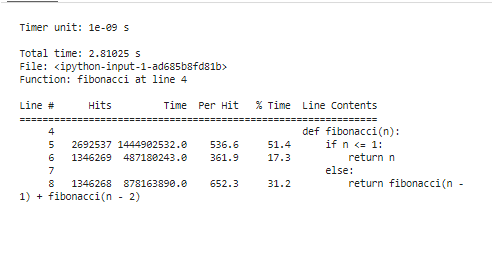
Cet extrait commence par charger l'extension « line_profiler », définit notre fonction « fibonacci » et utilise enfin « %lprun » pour profiler la fonction « fibonacci » avec « n=30 ». Il propose une segmentation ligne par ligne des temps d'exécution, indiquant précisément où notre code dépense ses ressources.
Après avoir exécuté les outils de profilage pour analyser les résultats, un tableau de statistiques sera présenté qui montre les caractéristiques de performance de notre code. Ces statistiques portent sur le temps total passé au sein de chaque fonction et la durée de chaque ligne de code. Par exemple, on peut distinguer que la fonction de Fibonacci investit un peu plus de temps à recalculer plusieurs fois les valeurs identiques. Il s’agit du calcul redondant et c’est un domaine clair dans lequel l’optimisation peut être appliquée, soit par mémorisation, soit en employant des algorithmes itératifs.
Maintenant, nous effectuons des optimisations là où nous avons identifié une optimisation potentielle dans notre fonction de Fibonacci. Nous avons remarqué que la fonction recalcule plusieurs fois les mêmes nombres de Fibonacci, ce qui entraîne une redondance inutile et un temps d'exécution plus lent.
Pour optimiser cela, nous implémentons la mémorisation. La mémorisation est une technique d'optimisation qui consiste à stocker les résultats précédemment calculés (dans ce cas, les nombres de Fibonacci) et à les réutiliser en cas de besoin au lieu de les recalculer. Cela réduit les calculs redondants et améliore les performances, notamment pour les fonctions récursives comme la séquence de Fibonacci.
Pour implémenter la mémoïsation dans notre fonction de Fibonacci, nous écrivons le code suivant :
# Dictionnaire pour stocker les nombres de Fibonacci calculésfib_cache = { }
déf fibonacci ( n ) :
si n <= 1 :
retour n
# Vérifiez si le résultat est déjà mis en cache
si n dans fib_cache :
retour fib_cache [ n ]
autre :
# Calculer et mettre en cache le résultat
fib_cache [ n ] = fibonacci ( n - 1 ) + fibonacci ( n - 2 )
retour fib_cache [ n ] ,
Dans cette version modifiée de la fonction « fibonacci », nous introduisons un dictionnaire « fib_cache » pour stocker les nombres de Fibonacci précédemment calculés. Avant de calculer un nombre de Fibonacci, on vérifie s'il est déjà dans le cache. Si c'est le cas, nous renvoyons le résultat mis en cache. Dans tous les autres cas, nous le calculons, le gardons dans le cache, puis le renvoyons.
Répéter le profilage et l'optimisation
Après avoir mis en œuvre l’optimisation (la mémorisation dans notre cas), il est crucial de répéter le processus de profilage pour connaître l’impact de nos modifications et s’assurer que nous avons amélioré les performances du code.
Profilage après optimisation
Nous pouvons utiliser les mêmes outils de profilage, « cProfile » et « line_profiler », pour profiler la fonction de Fibonacci optimisée. En comparant les nouveaux résultats de profilage avec les précédents, nous pouvons mesurer l'efficacité de notre optimisation.
Voici comment nous pouvons profiler la fonction « fibonacci » optimisée à l’aide de « cProfile » :
cprofileur = cProfil. Profil ( )cprofileur. activer ( )
résultat = fibonacci ( 30 )
cprofileur. désactiver ( )
cprofileur. print_stats ( trier = 'cumulatif' )
A l’aide du « line_profiler », on le profile ligne par ligne :
%lprun -f fibonacci fibonacci ( 30 )Code:
# Dictionnaire pour stocker les nombres de Fibonacci calculésfib_cache = { }
déf fibonacci ( n ) :
si n <= 1 :
retour n
# Vérifiez si le résultat est déjà mis en cache
si n dans fib_cache :
retour fib_cache [ n ]
autre :
# Calculer et mettre en cache le résultat
fib_cache [ n ] = fibonacci ( n - 1 ) + fibonacci ( n - 2 )
retour fib_cache [ n ]
cprofileur = cProfil. Profil ( )
cprofileur. activer ( )
résultat = fibonacci ( 30 )
cprofileur. désactiver ( )
cprofileur. print_stats ( trier = 'cumulatif' )
%lprun -f fibonacci fibonacci ( 30 )
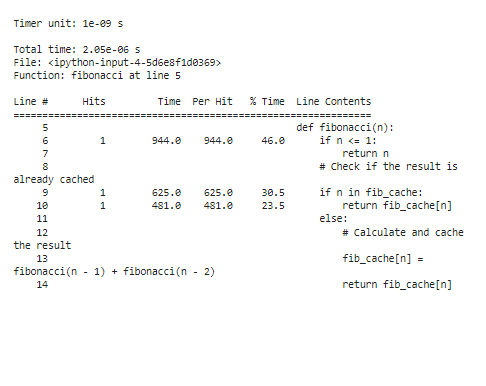
Pour analyser les résultats du profilage après optimisation, les temps d'exécution seront considérablement réduits, en particulier pour les grandes valeurs « n ». Grâce à la mémorisation, on observe que la fonction passe désormais beaucoup moins de temps à recalculer les nombres de Fibonacci.
Ces étapes sont essentielles dans le processus d’optimisation. L'optimisation implique d'apporter des modifications éclairées à notre code en fonction des observations obtenues grâce au profilage, tandis que la répétition du profilage garantit que nos optimisations génèrent les améliorations de performances attendues. Grâce au profilage, à l'optimisation et à la validation itératifs, nous pouvons affiner notre code Python pour offrir de meilleures performances et améliorer l'expérience utilisateur de nos applications.
Conclusion
Dans cet article, nous avons discuté de l'exemple dans lequel nous avons optimisé le code Python à l'aide d'outils de profilage dans l'environnement Google Colab. Nous avons initialisé l'exemple avec la configuration, importé les bibliothèques de profilage essentielles, écrit les exemples de codes, l'avons profilé à l'aide de « cProfile » et « line_profiler », calculé les résultats, appliqué les optimisations et affiné de manière itérative les performances du code.