Parfois, l'ensemble de données donné ne se trouve pas dans un seul fichier CSV. Ils sont tous sur des feuilles Excel différentes. Vous savez déjà qu'il est préférable d'effectuer toutes les activités de calcul ou de prétraitement sur un seul jeu de données plutôt que sur plusieurs jeux de données. Cela réduit ou économise le temps que nous devons consacrer aux tâches de prétraitement. De plus, en tant qu'analyste de données ou data scientist, vous pouvez fréquemment vous retrouver surchargé par de nombreux fichiers CSV qui doivent être fusionnés avant même de commencer votre analyse ou votre examen des données disponibles. D'autre part, il n'est pas toujours possible que tous les fichiers soient obtenus à partir d'une seule ou même source de données et aient les mêmes noms de colonnes/variables et la même structure de données. Cet article vous apprendra à combiner deux ou plusieurs fichiers CSV avec une structure de colonne similaire ou différente.
Pourquoi combiner des fichiers CSV ?
Un ensemble de données peut être une collection ou un groupe de valeurs ou de chiffres liés à un sujet spécifique. Par exemple, les résultats des tests de chaque élève dans une certaine classe sont un exemple d'ensemble de données. En raison de la taille des grands ensembles de données, ils sont souvent stockés dans des fichiers CSV distincts pour différentes catégories. Par exemple, si nous sommes tenus d'examiner un patient pour une maladie spécifique, nous devons tenir compte de chaque élément, y compris son sexe, son dossier médical, son âge, la gravité de la maladie, etc. Par conséquent, la combinaison des données CSV est nécessaire pour examiner divers facteurs prédictifs aspects. De plus, il est préférable de travailler et de gérer un seul jeu de données plutôt que plusieurs jeux de données lors de l'exécution des tâches de calcul ou de prétraitement. Il économise de la mémoire et d'autres ressources de calcul
Comment combiner des fichiers CSV en Python ?
Il existe plusieurs façons et méthodes pour combiner deux ou plusieurs fichiers CSV en Python. Dans la section ci-dessous, nous utiliserons les fonctions append(), concat() et merge(), etc., pour combiner des fichiers CSV dans la trame de données pandas, puis les trames de données seront converties en un seul fichier CSV. Nous apprendrons comment combiner plusieurs fichiers CSV avec une structure de colonne similaire ou variable.
Méthode n° 1 : combiner des CSV avec des structures ou des colonnes similaires
Notre répertoire de travail actuel contient deux fichiers CSV, 'test1' et 'test2'.
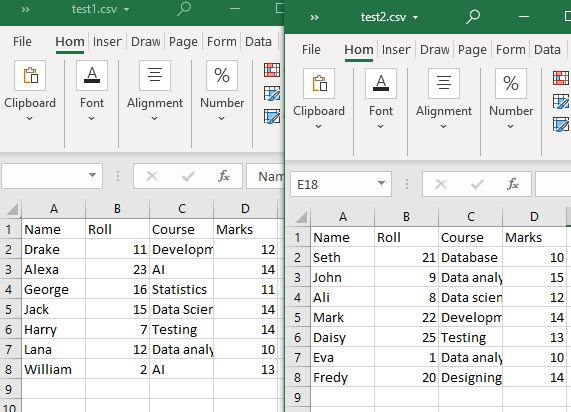
Exemple # 1 : Utilisation de la fonction append()
Les deux fichiers CSV ont la même structure. La fonction glob() sera utilisée dans cette méthode pour lister uniquement les fichiers CSV dans le répertoire de travail. Ensuite, nous utiliserons 'pandas.DataFrame.append()' pour lire nos fichiers CSV (avec une structure de table commune).

Production:
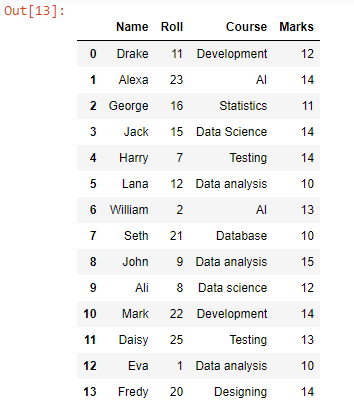
À l'aide de la fonction d'ajout, nous avons ajouté ou ajouté chaque ligne de données de test2.csv sous les lignes de données de test1.csv, car on peut voir que toutes les lignes de données du fichier ont été combinées. Pour convertir cette dataframe en CSV, nous pouvons utiliser la fonction to_csv().

Cela créera un fichier CSV combiné de fichiers CSV de 'test1' et 'test2' dans notre répertoire de travail avec le nom spécifié, c'est-à-dire merged.csv.
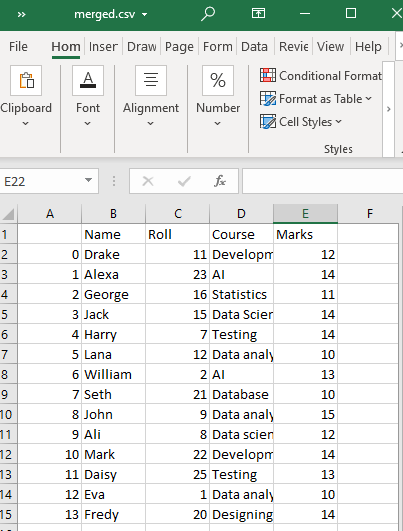
Exemple # 2 : Utilisation de la fonction concat()
Nous allons d'abord importer le module pandas. La méthode map lira chaque fichier CSV que nous avons transmis à l'aide de pd.read_csv(). Ces fichiers mappés (fichiers CSV) seront ensuite combinés le long de l'axe des lignes par défaut à l'aide de la fonction pd.concat(). Si nous voulons combiner des fichiers CSV horizontalement, nous pouvons transmettre axis=1. La spécification de l'indice ignore = True crée également des valeurs d'index continues pour la trame de données combinée.

Le pd.read_csv() est passé à l'intérieur de la fonction concat() pour lire les fichiers CSV dans la trame de données pandas après la concaténation.
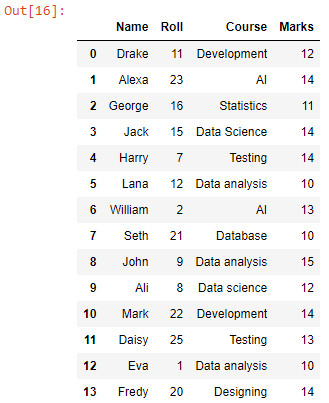
Nous avons obtenu une base de données avec des données combinées de tous les fichiers CSV dans le répertoire de travail. Maintenant, convertissons-le en un fichier CSV.
Notre CSV combiné est créé dans le répertoire courant.
Méthode # 2 : Combiner des CSV avec différentes structures ou colonnes
Nous avons discuté de la combinaison de fichiers CSV avec les mêmes colonnes et structure dans la première méthode. Dans cette méthode, nous combinerons des fichiers CSV avec différentes colonnes et structures.
Exemple # 1 : Utilisation de la fonction merge()
La fonction 'pandas.merge()' du module pandas peut combiner deux fichiers CSV. La fusion fait simplement référence à la combinaison de deux ensembles de données en un seul ensemble de données basé sur des colonnes ou des attributs partagés.
Nous pouvons fusionner des dataframes de quatre manières différentes :
- Intérieur
- Droit
- La gauche
- Extérieur
Pour effectuer ces types de fusions, nous utiliserons deux fichiers CSV.
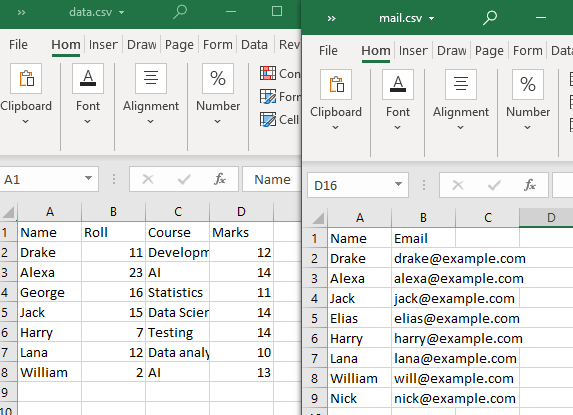
Notez qu'au moins un attribut ou une colonne doit être partagé par les deux fichiers CSV. Comme observé, la colonne 'Nom' et certains de ses attributs sont partagés par les deux fichiers CSV.
Fusionner à l'aide de la jointure interne
La spécification du paramètre how='inner' dans la fonction merge() combinera les deux dataframes en fonction de la colonne spécifiée, puis fournira un nouveau dataframe qui ne contient que les lignes avec des valeurs identiques/identiques dans les deux dataframes d'origine.
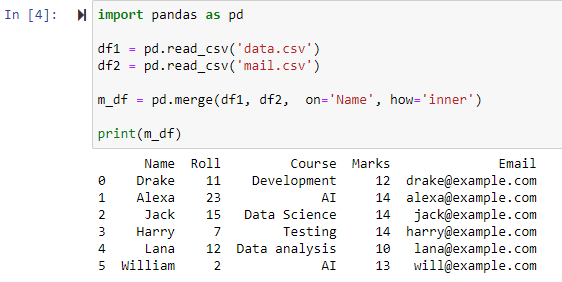
Comme on peut le voir, la fonction a fusionné les deux fichiers CSV et renvoyé les lignes en fonction des attributs communs de la colonne 'Nom'.
Fusionner à l'aide de la jointure externe droite
Lorsque le paramètre how='right' est spécifié, les deux dataframes seront combinés en fonction de la colonne que nous avons spécifiée pour le paramètre 'on'. Et une nouvelle trame de données contenant toutes les lignes de la trame de données de droite, y compris toutes les lignes pour lesquelles la trame de données de gauche ne contient aucune valeur, sera renvoyée, avec la valeur de colonne de la trame de données de gauche définie sur NAN.
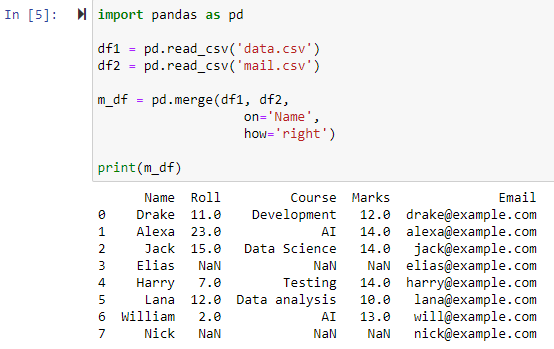
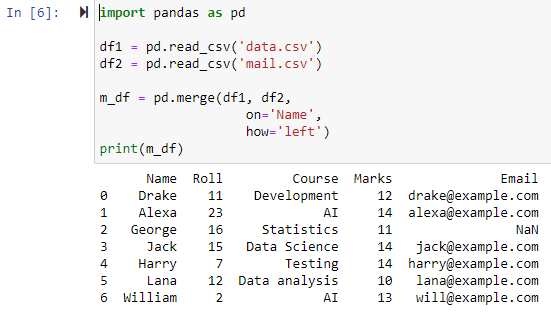
Fusionner à l'aide de la jointure externe gauche
Lorsque le paramètre est spécifié comme 'gauche', les deux trames de données sont combinées en fonction de la colonne spécifiée à l'aide du paramètre 'on', renvoyant une nouvelle trame de données contenant toutes les lignes de la trame de données de gauche ainsi que toutes les lignes contenant NAN ou des valeurs nulles dans la trame de données droite et définit la valeur de colonne de la trame de données droite sur NAN.
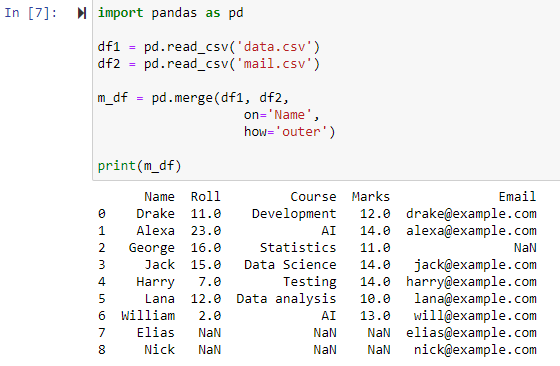
Fusionner à l'aide d'une jointure externe complète
Lorsque how='outer' est spécifié, les deux trames de données sont combinées en fonction de la colonne spécifiée pour le paramètre 'on', renvoyant une nouvelle trame de données contenant les lignes des trames de données df1 et df2 et définissant NAN comme valeur pour toutes les lignes pour laquelle des données sont absentes dans l'une des trames de données.
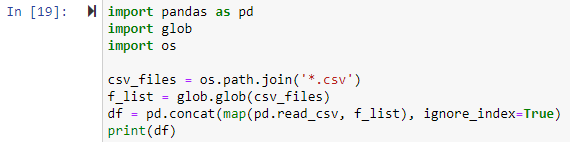
Exemple # 2 : Combinaison de tous les fichiers CSV dans le répertoire de travail
Dans cette méthode, nous utiliserons le module glob pour combiner tous les fichiers .csv dans un pandas DataFrame. Toutes les bibliothèques devaient d'abord être importées. Ensuite, nous allons définir un chemin pour chaque fichier CSV que nous voulons combiner. Le chemin du fichier est le premier argument de la fonction os.path.join() dans l'exemple ci-dessous, et le deuxième argument est soit les composants du chemin, soit les fichiers .csv à joindre. Ici, l'expression « *.csv » trouvera et renverra chaque fichier dans le répertoire de travail se terminant par l'extension de fichier .csv. La fonction glob.glob(files joins) accepte une liste des noms des fichiers fusionnés en entrée et génère une liste de tous les fichiers fusionnés/combinés.
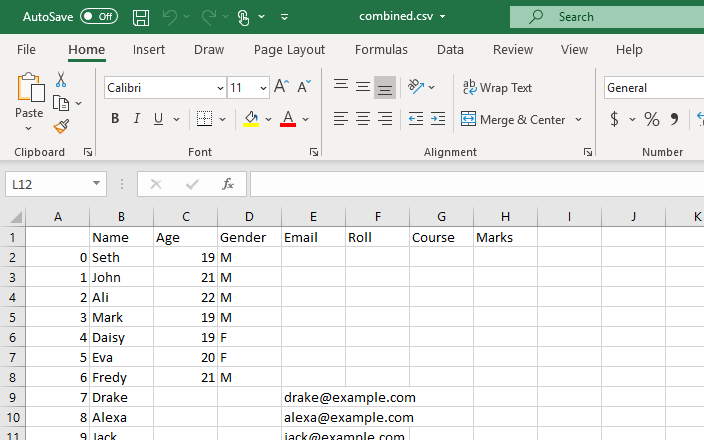
Ce script renverra une trame de données avec les données combinées de tous les fichiers CSV de notre répertoire de travail.
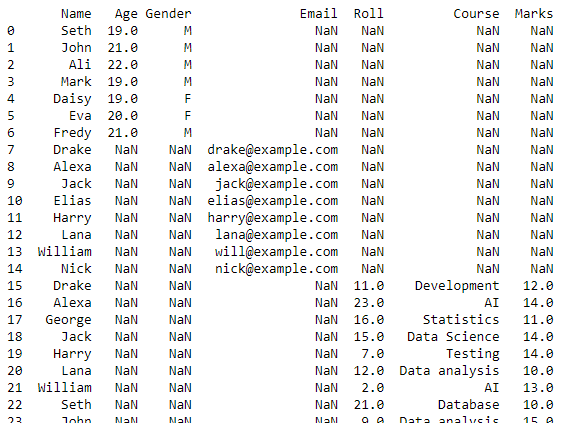
Cette trame de données sera transformée en un fichier CSV, et la fonction to_csv() sera utilisée pour cette conversion. Ce nouveau fichier CSV sera les fichiers CSV combinés créés à partir de tous les fichiers CSV stockés dans le répertoire de travail actuel.
Conclusion
Dans cet article, nous avons expliqué pourquoi nous devons combiner des fichiers CSV. Nous avons expliqué comment deux fichiers CSV ou plus peuvent être combinés en Python. Nous avons divisé ce tutoriel en deux sections. Dans la première section, nous avons expliqué comment utiliser les fonctions append() et concat() pour combiner des fichiers CSV de même structure ou noms de colonne. Dans la deuxième section, nous avons utilisé la méthode merge(), os.path.join() et la méthode glob pour combiner des fichiers CSV de différentes colonnes et structures.