{ nom: 'Alexa Bill' , grade: 'UN' , cours: 'python' },
{ nom: 'Jeanne Marques' , grade: 'B' , cours: 'Java' },
{ nom: 'Paul Ken' , grade: 'C' , cours: 'C#' },
{ nom: 'Emily Jeo' , grade: 'D' , cours: 'php' }
]);
Nous pouvons également créer un champ d'index unique lorsque la collection est présente avec certains documents à l'intérieur. Pour cela, nous insérons le document dans la nouvelle collection qui est « candidats » dont la requête d'insertion est donnée comme suit :
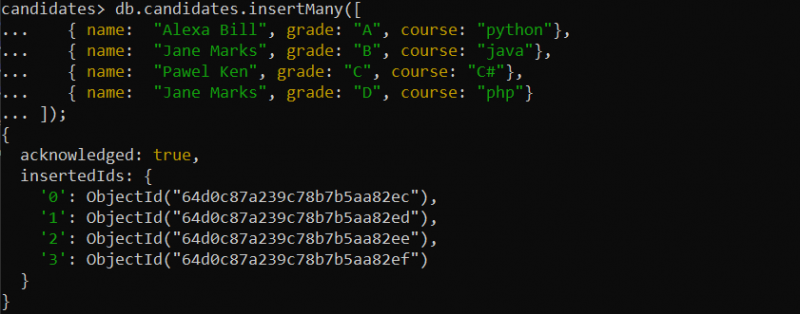
Exemple 1 : créer un index unique d'un seul champ
Nous pouvons créer l'index en utilisant la méthode createIndex() et nous pouvons rendre ce champ unique en spécifiant l'option unique avec le booléen « true ».
db.candidates.createIndex( { note : 1 }, { unique : vrai } )
Ici, nous lançons la méthode createIndex() sur la collection « candidats » pour créer un index unique d'un champ spécifique. Ensuite, nous fournissons le champ « grade » avec la valeur « 1 » pour la spécification de l'index. La valeur de « 1 » représente ici l’index ascendant de la collection. Ensuite, nous spécifions l'option « unique » avec la valeur « true » pour renforcer l'unicité du champ « grade ».
Le résultat indique que l'index unique sur le champ « note » est créé pour la collection « candidats » :

Exemple 2 : créer un index unique de plusieurs champs
Dans l'exemple précédent, un seul champ est créé en tant qu'index unique. Mais nous pouvons également créer simultanément deux champs comme index unique en utilisant la méthode createIndex().
db.candidates.createIndex( { note : 1 , cours: 1 }, { unique : vrai } )
Ici, nous appelons la méthode createIndex() sur la même collection « candidats ». Nous spécifions deux champs à la méthode createIndex() – « grade » et « course » – avec la valeur « 1 » comme première expression. Ensuite, nous définissons l'option unique avec la valeur « true » pour créer ces deux champs uniques.
Le résultat représente deux index uniques, « grade_1 » et « course_1 », pour la collection « candidats » suivante :

Exemple 3 : Créer un index unique composé des champs
Cependant, nous pouvons également créer simultanément un index composé unique au sein de la même collection. Nous y parvenons grâce à la requête suivante :
db.candidates.createIndex( { nom : 1 , grade: 1 , cours: 1 }, { unique : vrai }Nous utilisons à nouveau la méthode createIndex() pour créer l'index unique composé pour la collection « candidats ». Cette fois, nous transmettons trois champs – « note », « nom » et « cours » – qui font office de champs d'index ascendant pour la collection « candidats ». Ensuite, nous appelons l'option « unique » pour rendre le champ unique car « vrai » est attribué à cette option.
La sortie affiche les résultats qui montrent que les trois champs constituent désormais l'index unique de la collection spécifiée :

Exemple 4 : Créer un index unique de valeurs de champ en double
Maintenant, nous essayons de créer l'index unique pour la valeur du champ en double, ce qui déclenche une erreur afin de maintenir la contrainte d'unicité.
db.candidates.createIndex({nom : 1 },{unique:true})Ici, nous appliquons les critères d'index unique pour le champ qui contient des valeurs similaires. Dans la méthode createIndex(), nous appelons le champ « name » avec la valeur « 1 » pour en faire un index unique et définissons l'option unique avec la valeur « true ». Les deux documents ayant le champ « nom » avec des valeurs identiques, nous ne pouvons pas faire de ce champ un index unique de la collection « candidats ». L'erreur de clé en double est déclenchée lors de l'exécution de la requête.
Comme prévu, la sortie génère les résultats car le champ de nom a les mêmes valeurs pour deux documents différents :

Ainsi, nous mettons à jour la collection « candidats » en donnant une valeur unique à chaque champ « nom » du document puis créons le champ « nom » comme index unique. L'exécution de cette requête crée généralement le champ « nom » comme index unique, comme indiqué dans ce qui suit :

Exemple 5 : Créer un index unique d'un champ manquant
Alternativement, nous appliquons la méthode createIndex() sur le champ qui n’existe dans aucun des documents de la collection. Par conséquent, l'index stocke une valeur nulle pour ce champ et l'opération échoue en raison d'une violation de la valeur du champ.
db.candidates.createIndex( {e-mail : 1 }, { unique : vrai } )Ici, nous utilisons la méthode createIndex() où le champ « email » reçoit la valeur « 1 ». Le champ « email » n'existe pas dans la collection « candidats » et nous essayons d'en faire un index unique pour la collection « candidats » en définissant l'option unique sur « true ».
Lorsque la requête est exécutée, nous obtenons l'erreur dans la sortie car le champ « email » est manquant dans la collection « candidats » :

Exemple 6 : Créer un index unique d'un champ avec une option clairsemée
Ensuite, l'index unique peut également être créé avec l'option clairsemée. La fonctionnalité d'un index clairsemé est qu'il inclut uniquement les documents comportant le champ indexé, à l'exclusion des documents ne possédant pas le champ indexé. Nous avons fourni la structure suivante pour configurer l'option sparse :
db.candidates.createIndex( { cours : 1 },{ nom: 'unique_sparse_course_index' , unique : vrai, clairsemé : vrai } )
Ici, nous fournissons la méthode createIndex() où le champ « cours » est défini avec la valeur « 1 ». Après cela, nous spécifions l'option supplémentaire pour définir un champ d'index unique qui est « cours ». Les options incluent le « nom » qui définit l'index « unique_sparse_course_index ». Ensuite, nous avons l'option « unique » qui est spécifiée avec la valeur « true » et l'option « sparse » est également définie sur « true ».
La sortie crée un index unique et clairsemé sur le champ « cours », comme indiqué ci-dessous :

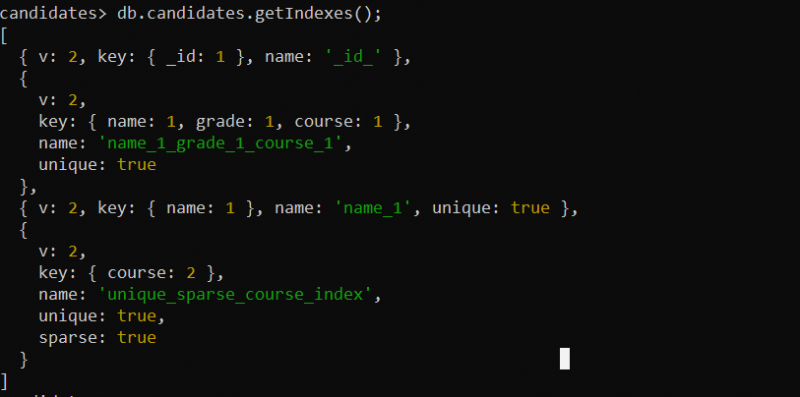
Exemple 7 : afficher l'index unique créé à l'aide de la méthode GetIndexes()
Dans l'exemple précédent, seul un index unique a été créé pour la collection fournie. Pour visualiser et obtenir les informations sur les index uniques de la collection « candidats », nous utilisons la méthode getIndexes() suivante :
db.candidates.getIndexes();Ici, nous appelons la fonction getIndexes() sur la collection « candidats ». La fonction getIndexes() renvoie tous les champs d'index de la collection « candidats » que nous avons créée dans les exemples précédents.
La sortie affiche l'index unique que nous avons créé pour la collection : soit un index unique, un index composé ou un index fragmenté unique :
Conclusion
Nous avons tenté de créer un index unique pour les champs spécifiques de la collection. Nous avons exploré les différentes manières de créer un index unique pour un seul champ et plusieurs champs. Nous avons également tenté de créer un index unique où l'opération échoue en raison d'une violation de contrainte unique.