Amazon Redshift est une solution cloud proposée par AWS qui remplit l'objectif d'un entrepôt de données. Un entrepôt de données est un grand espace dans le cloud qui stocke d'énormes quantités de données. La différence entre un entrepôt de données et une base de données est que le premier ne stocke pas seulement les données actuelles mais également l'historique complet des données.
Cet article présente Amazon Redshift par AWS et les types de données pris en charge par ce service.
Qu'est-ce qu'Amazon RedShift ?
Il s'agit d'une solution cloud d'entreposage de données basée sur 'PostgreSQL' . Il utilise une technologie appelée 'Traitement massivement parallèle (MPP)' pour traiter des pétaoctets de données à la vitesse de l'éclair. Cela fournit une solution simple pour la prédiction en temps réel basée sur des données historiques et des solutions de streaming.
La figure suivante montre le mécanisme de fonctionnement d'Amazon Redshift :
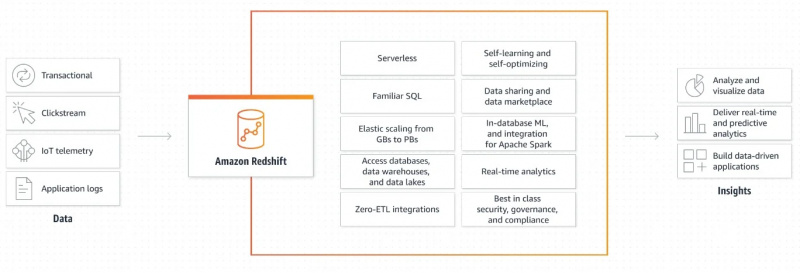
Cette explication graphique du fonctionnement d'Amazon Redshift est très simple et claire. Il nous donne des informations sur la façon dont les données sont récupérées et traitées ultérieurement pour générer des sorties et créer des applications basées sur les données.
L'architecture d'entrepôt de données d'Amazon Redshift peut également être vue dans la figure ci-dessous :
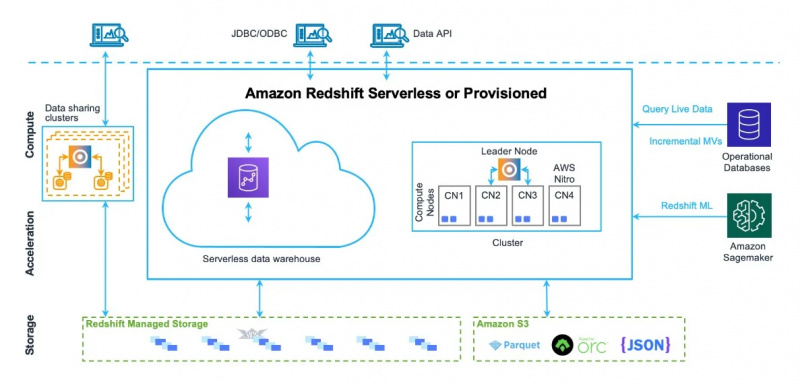
Maintenant, nous allons nous diriger vers les utilisations et les fonctionnalités de ce service.
Caractéristiques
Comme déjà mentionné, Amazon Redshift est basé sur PostgreSQL et utilise une technologie appelée Massively Parallel Processing qui lui permet de traiter des pétaoctets de données en un rien de temps. Par conséquent, Redshift offre un bon nombre de fonctionnalités et d'utilisations. Certaines de ces fonctionnalités sont ci-dessous :
- Sécurité et cryptage des données.
- Analytique commerciale.
- Support d'application basé sur les données.
- Analyse prédictive.
- Répétition automatisée des tâches.
- Mise à l'échelle simultanée des données.
- Entreposage de données.
Certaines fonctionnalités supplémentaires de ce service peuvent être vues dans la figure ci-dessous :
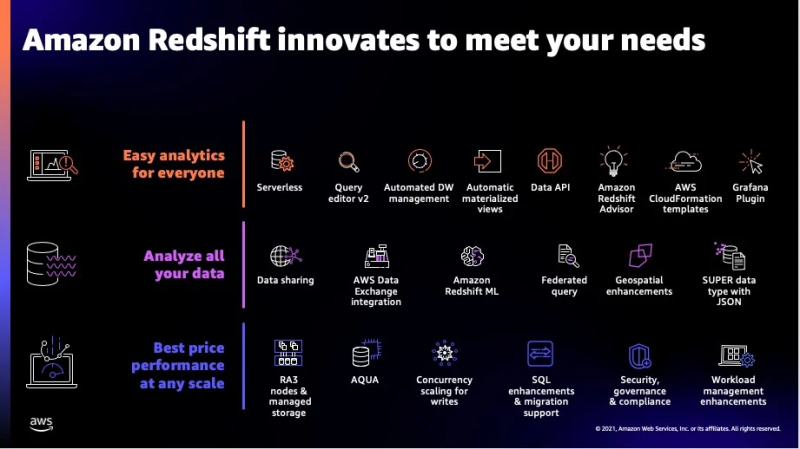
C'étaient la plupart des fonctionnalités offertes par Redshift et nous allons maintenant passer aux types de données pris en charge par ce service.
Types de données
Amazon Redshift est une solution d'entreposage de données avec un grand nombre de fonctionnalités. Il prend en charge les types de données structurés et non structurés. Comme il est basé sur PostgreSQL, les données peuvent être manipulées via de simples requêtes SQL.
Maintenant, une autre question se pose, à savoir, en quoi ces formats de données diffèrent les uns des autres ? Discutons de ces deux formats de données.
Données structurées
Un type de données hautement formaté qui est facilement traduit par des algorithmes d'apprentissage automatique est appelé données structurées. Une base de données SQL fonctionne avec des données structurées. Les données structurées sont sous forme de tableau, telles que les données utilisées par les bases de données relationnelles
L'un des systèmes de gestion de base de données SQL les plus utilisés est MYSQL. Son architecture peut être vue ci-dessous dans la figure donnée :
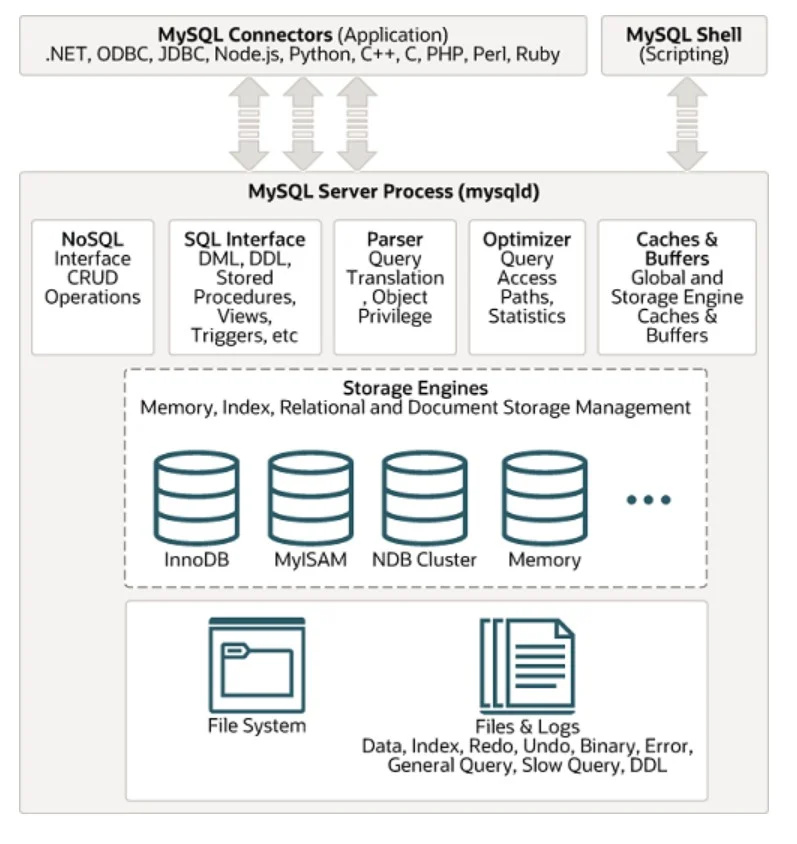
Données non structurées
Les données non structurées sont sans modèle et formatent moins de données telles que les données utilisées dans les bases de données non relationnelles. MongoDB est une célèbre base de données non relationnelle. Les requêtes SQL ne fonctionnent pas sur les bases de données non relationnelles, ces bases de données sont donc également appelées bases de données NoSQL.
Comme déjà mentionné, MongoDB est un système de gestion de base de données non structuré et son architecture peut être vue ci-dessous dans la figure donnée :
Nous avons parcouru les deux types de données fondamentaux utilisés dans les bases de données et nous allons maintenant nous diriger vers les types de données réels pris en charge par Amazon Redshift. Ces types de données sont :
- Données numériques
- Données de caractère
- Données de date et d'heure
- Données booléennes
- Données HLLSKETCH
- SUPER données
- Données de REMPLACEMENT
Discutons de ces types de données :
Données numériques
Ce type de données est explicite. Il prend en charge les données sous forme d'entiers, de décimales, de virgule flottante et d'autres types de données numériques.
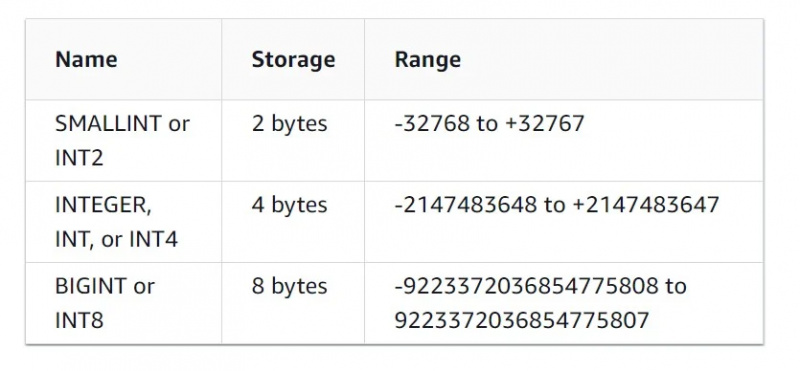
Les caractéristiques du type de données entier peuvent être vues dans la figure ci-dessous :
Le type de données décimal stocke les données en fonction de la précision de l'utilisateur. Ses caractéristiques sont les suivantes :

Données de caractère
Les types de données CHAR et VARCHAR appartiennent à la catégorie des types de données basés sur des caractères. NCHAR et NVARCHAR sont également des types de données de type caractère. Contrairement à CHAR et VARCHAR, ces deux types de données stockent des caractères Unicode de longueur fixe. Examinons les propriétés de ces types de données, telles que :
- CHAR, CHARACTER, NCHAR ont une plage de 4 Ko.
- VARCHAR, NVARCHAR a une plage de 64 Ko.
- BPCHAR a une plage de 256 octets.
- TEXT a une plage de 260 octets.
Données de date et d'heure
Les types de données datetime sont DATE, TIME, TIMETZ, TIMESTAMP, TIMESTAMPTZ. Les capacités fonctionnelles de ces types de données sont les suivantes :
- DATE stocke simplement les dates du calendrier.
- TIME stocke l'heure sans référence à aucun fuseau horaire. Il s'agit de l'UTC, par défaut.
- TIMETZ stocke l'heure en référence au fuseau horaire. Il s'agit de l'UTC dans les tables utilisateur et les tables système, par défaut.
- TIMESTAMP comprend non seulement l'heure, mais également les dates. Il s'agit de l'UTC dans les tables utilisateur et les tables système, par défaut.
- TIMESTAMPTZ inclut non seulement l'heure mais aussi les dates. Il s'agit de l'UTC uniquement dans les tables utilisateur, par défaut.
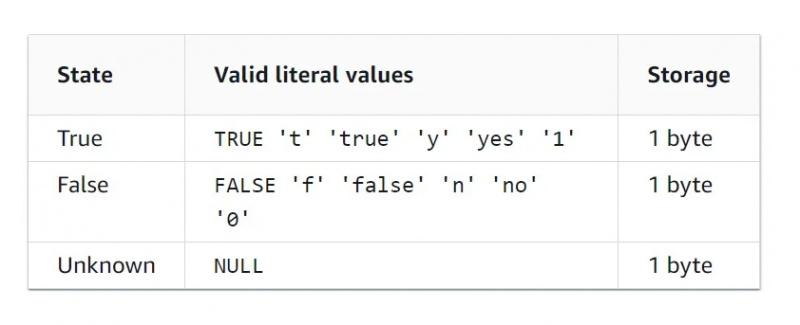
Données booléennes
Le type de données booléen est un type de données binaire, ce qui signifie qu'il n'y a que deux valeurs. Le tableau des caractéristiques pour le type de données booléen est donné ci-dessous dans la figure :
Données HLLSKETCH
Ce type de données est utilisé pour stocker des esquisses. Redshift peut représenter les esquisses sous une forme clairsemée ou dense. Les croquis commencent comme clairsemés et deviennent progressivement denses lorsqu'un format dense offre plus d'efficacité en suivant le lien.
SUPER données
Ce type de données traite des données non structurées qui peuvent se présenter sous la forme de tableaux, de structures imbriquées ou de JSON. Il n'y a pas de modèle ou de format des données. Les utilisateurs peuvent explorer plus d'informations en naviguant sur le lien.
Données de REMPLACEMENT
Ce type de données stocke également des caractères. Cependant, la longueur est limitée. Amazon Redshift permet de convertir les données VARBYTE en données de type entier ou caractère. Pour obtenir plus d'informations sur ce type de données, suivez le lien ci-dessous.
C'est tout ce qu'il y a à Amazon Redshift et aux types de données qu'il prend en charge.
Conclusion
Amazon Redshift est un service AWS qui, dans sa forme de base, sert l'objectif d'un entrepôt de données, mais constitue une solution très puissante et fonctionnelle pour l'analyse et la prédiction. Cet article a traité de Redshift et des types de données qu'il prend en charge. Ces types de données ont été expliqués brièvement ainsi que leurs caractéristiques.