Ce guide illustrera le processus d'exécution de LLMChains dans LangChain.
Comment exécuter des LLMChains dans LangChain ?
LangChain fournit les fonctionnalités ou dépendances permettant de créer des LLMChains à l'aide des LLM/Chatbots et des modèles d'invite. Pour apprendre le processus de création et d'exécution des LLMChains dans LangChain, suivez simplement le guide étape par étape suivant :
Étape 1 : Installer les packages
Tout d’abord, lancez le processus en installant le module LangChain pour obtenir ses dépendances pour créer et exécuter LLMChains :
pip installer langchain
Installez le framework OpenAI à l'aide de la commande pip pour que les bibliothèques utilisent la fonction OpenAI() pour créer des LLM :
pip installer openai
Après l'installation des modules, il suffit mettre en place l'environnement variables utilisant la clé API du compte OpenAI :
importer toi
importer obtenir un laissez-passer
toi . environ [ 'OPENAI_API_KEY' ] = obtenir un laissez-passer . obtenir un laissez-passer ( « Clé API OpenAI : » )
Étape 2 : Importer des bibliothèques
Une fois la configuration terminée et tous les packages requis installés, importez les bibliothèques requises pour créer le modèle d'invite. Après cela, créez simplement le LLM à l'aide de la méthode OpenAI() et configurez le LLMChain à l'aide des LLM et du modèle d'invite :
depuis chaîne de langue importer Modèle d'invitedepuis chaîne de langue importer OpenAI
depuis chaîne de langue importer LLMChaîne
invite_template = 'Donnez-moi un bon titre pour une entreprise qui fabrique du {produit} ?'
llm = OpenAI ( température = 0 )
llm_chain = LLMChaîne (
llm = llm ,
rapide = Modèle d'invite. à partir du modèle ( invite_template )
)
llm_chain ( 'des vêtements colorés' )
Étape 3 : Exécuter des chaînes
Récupérez la liste d'entrée contenant les différents produits fabriqués par l'entreprise et exécutez la chaîne pour afficher la liste à l'écran :
liste_entrée = [{ 'produit' : 'chaussettes' } ,
{ 'produit' : 'ordinateur' } ,
{ 'produit' : 'chaussures' }
]
llm_chain. appliquer ( liste_entrée )
Exécutez la méthode generate() en utilisant le liste_entrée avec LLMChains pour obtenir le résultat lié à la conversation générée par le modèle :
llm_chain. générer ( liste_entrée ) 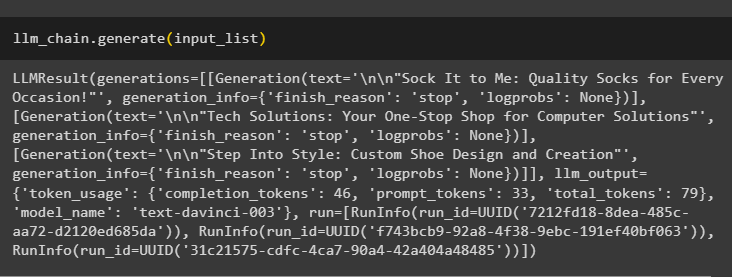
Étape 4 : Utilisation d'une entrée unique
Ajoutez un autre produit pour exécuter les LLMChains en utilisant une seule entrée, puis prédisez la LLMChain pour générer la sortie :
llm_chain. prédire ( produit = 'chaussettes colorées' )Étape 5 : Utilisation de plusieurs entrées
Maintenant, créez le modèle pour utiliser plusieurs entrées pour fournir la commande au modèle avant d'exécuter la chaîne :
modèle = '''Raconte-moi une blague sur {adjectif} sur {sujet}.'''rapide = Modèle d'invite ( modèle = modèle , variables_d'entrée = [ 'adjectif' , 'sujet' ] )
llm_chain = LLMChaîne ( rapide = rapide , llm = OpenAI ( température = 0 ) )
llm_chain. prédire ( adjectif = 'triste' , sujet = 'canards' )
Étape 6 : Utilisation de l'analyseur de sortie
Cette étape utilise la méthode d'analyseur de sortie pour exécuter LLMChain afin d'obtenir la sortie en fonction de l'invite :
depuis chaîne de langage. analyseurs_de sortie importer CommaSeparatedListOutputParseranalyseur_de sortie = CommaSeparatedListOutputParser ( )
modèle = '''Liste toutes les couleurs d'un arc-en-ciel'''
rapide = Modèle d'invite ( modèle = modèle , variables_d'entrée = [ ] , analyseur_de sortie = analyseur_de sortie )
llm_chain = LLMChaîne ( rapide = rapide , llm = llm )
llm_chain. prédire ( )
L'utilisation de la méthode parse() pour obtenir le résultat générera une liste de toutes les couleurs de l'arc-en-ciel, séparées par des virgules :
llm_chain. prédire_et_parse ( ) 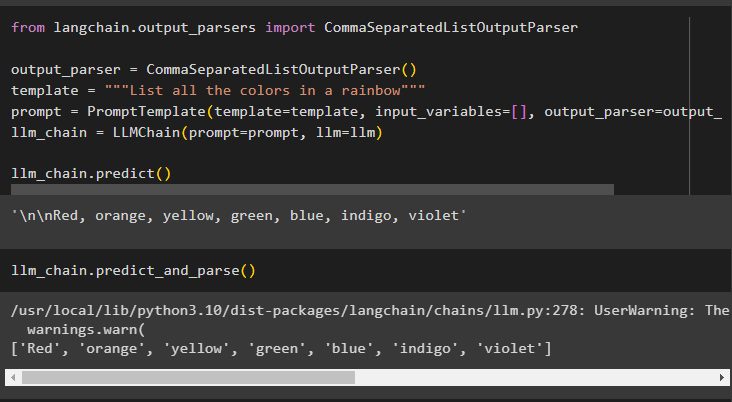
Étape 7 : initialisation à partir de chaînes
Cette étape explique le processus d'utilisation d'une chaîne comme invite pour exécuter LLMChain à l'aide du modèle et du modèle LLM :
modèle = '''Raconte-moi une blague sur {adjectif} sur {sujet}'''llm_chain = LLMChaîne. from_string ( llm = llm , modèle = modèle )
Fournissez les valeurs des variables dans l'invite de chaîne pour obtenir la sortie du modèle en exécutant LLMChain :
llm_chain. prédire ( adjectif = 'triste' , sujet = 'canards' )Il s’agit d’exécuter les LLMChains à l’aide du framework LangChain.
Conclusion
Pour créer et exécuter les LLMChains dans LangChain, installez les prérequis tels que les packages et configurez l'environnement à l'aide de la clé API d'OpenAI. Après cela, importez les bibliothèques requises pour configurer le modèle d'invite et le modèle d'exécution de LLMChain à l'aide des dépendances LangChain. L'utilisateur peut utiliser des analyseurs de sortie et des commandes de chaîne pour exécuter LLMChains comme démontré dans le guide. Ce guide a expliqué le processus complet d'exécution des LLMChains dans LangChain.