La comparaison de données en SQL est une tâche courante que chaque développeur de bases de données rencontrera occasionnellement. Heureusement, la comparaison de données se présente sous une grande variété de formats tels que la comparaison littérale, la comparaison booléenne, etc.
Cependant, l'un des scénarios de comparaison de données réels que vous pourriez rencontrer est la comparaison entre deux tables. Il joue un rôle crucial dans des tâches telles que la validation des données, l'identification des erreurs, la duplication ou la garantie de l'intégrité des données.
Dans ce didacticiel, nous explorerons toutes les différentes méthodes et techniques que nous pouvons utiliser pour comparer deux tables de base de données en SQL.
Exemple de configuration des données
Avant de plonger dans chacune des méthodes, configurons une configuration de données de base à des fins de démonstration.
Nous avons deux tableaux avec des exemples de données, comme indiqué dans l'exemple.
Exemple de tableau 1 :
Ce qui suit contient les requêtes permettant de créer la première table et d'insérer les exemples de données dans la table :
CRÉER UNE TABLE sample_tb1 (
employe_id INT CLÉ PRIMAIRE AUTO_INCREMENT,
prénom VARCHAR ( cinquante ) ,
nom VARCHAR ( cinquante ) ,
département VARCHAR ( cinquante ) ,
salaire DÉCIMAL ( dix , 2 )
) ;
INSÉRER DANS sample_tb1 ( prénom, nom, département, salaire )
VALEURS
( 'Pénélope' , 'Chasse' , 'HEURE' , 55000.00 ) ,
( 'Matthieu' , 'Cage' , 'IL' , 60000.00 ) ,
( 'Jeniffer' , 'Davis' , 'Finance' , 50000.00 ) ,
( 'Kirsten' , 'Fawcet' , 'IL' , 62000.00 ) ,
( 'Cameron' , 'costner' , 'Finance' , 48000.00 ) ;
Cela devrait créer une nouvelle table appelée « sample_tb1 » avec diverses informations telles que les noms, le département et le salaire.
Le tableau résultant est le suivant :

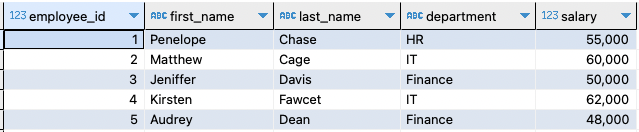
Exemple de tableau 2 :
Continuons et créons deux exemples de tableaux. Supposons qu'il s'agisse d'une copie de sauvegarde de la première table. Nous pouvons créer le tableau et insérer un exemple de données comme indiqué ci-dessous :
CRÉER UNE TABLE sample_tb2 (employe_id INT CLÉ PRIMAIRE AUTO_INCREMENT,
prénom VARCHAR ( cinquante ) ,
nom VARCHAR ( cinquante ) ,
département VARCHAR ( cinquante ) ,
salaire DÉCIMAL ( dix , 2 )
) ;
INSÉRER DANS sample_tb2 ( prénom, nom, département, salaire )
VALEURS
( 'Pénélope' , 'Chasse' , 'HEURE' , 55000.00 ) ,
( 'Matthieu' , 'Cage' , 'IL' , 60000.00 ) ,
( 'Jeniffer' , 'Davis' , 'Finance' , 50000.00 ) ,
( 'Kirsten' , 'Fawcet' , 'IL' , 62000.00 ) ,
( 'Audrey' , 'Doyen' , 'Finance' , 48000.00 ) ;
Cela devrait créer une table et insérer les exemples de données comme spécifié dans la requête précédente. Le tableau résultant est le suivant :
Comparez deux tables en utilisant Sauf
L'un des moyens les plus courants de comparer deux tables en SQL consiste à utiliser l'opérateur EXCEPT. Cela recherche les lignes qui existent dans le premier tableau mais pas dans le deuxième tableau.
Nous pouvons l'utiliser pour effectuer une comparaison avec les exemples de tableaux comme suit :
SÉLECTIONNER *DE sample_tb1
SAUF
SÉLECTIONNER *
FROM sample_tb2 ;
Dans cet exemple, l'opérateur EXCEPT renvoie toutes les lignes distinctes de la première requête (sample_tb1) qui n'apparaissent pas dans la deuxième requête (sample_tb2).
Comparez deux tables à l’aide de Union
La deuxième méthode que nous pouvons utiliser est l'opérateur UNION en conjonction avec la clause GROUP BY. Cela permet d'identifier les enregistrements qui existent dans une table, pas dans l'autre, tout en préservant les enregistrements en double.
Prenez la requête illustrée ci-dessous :
SÉLECTIONNERid_employé,
prénom,
nom de famille,
département,
salaire
DEPUIS
(
SÉLECTIONNER
id_employé,
prénom,
nom de famille,
département,
salaire
DEPUIS
échantillon_tb1
UNION TOUS
SÉLECTIONNER
id_employé,
prénom,
nom de famille,
département,
salaire
DEPUIS
échantillon_tb2
) AS données_combinées
PAR GROUPE
id_employé,
prénom,
nom de famille,
département,
salaire
AYANT
COMPTER ( * ) = 1 ;
Dans l'exemple donné, nous utilisons l'opérateur UNION ALL pour combiner les données des deux tables tout en conservant les doublons.
Nous utilisons ensuite la clause GROUP BY pour regrouper les données combinées par toutes les colonnes. Enfin, nous utilisons la clause HAVING pour garantir que seuls les enregistrements avec un nombre de un (pas de doublons) sont sélectionnés.
Sortir:

Cette méthode est un peu plus complexe, mais elle fournit un bien meilleur aperçu car vous obtenez les données réelles qui manquent dans les deux tableaux.
Comparez deux tables à l'aide de INNER JOIN
Si vous avez réfléchi, pourquoi ne pas utiliser un INNER JOIN ? Vous seriez au point. Nous pouvons utiliser un INNER JOIN pour comparer les tables et trouver les enregistrements communs.
Prenons par exemple la requête suivante :
SÉLECTIONNERéchantillon_tb1. *
DEPUIS
échantillon_tb1
JOINTURE INTÉRIEURE sample_tb2 ON
sample_tb1.employee_id = sample_tb2.employee_id ;
Dans cet exemple, nous utilisons un SQL INNER JOIN pour rechercher les enregistrements qui existent dans les deux tables en fonction d'une colonne donnée. Bien que cela fonctionne, cela peut parfois être trompeur car vous ne savez pas si les données sont réellement manquantes ou présentes dans les deux tableaux ou dans un seul.
Conclusion
Dans ce didacticiel, nous avons découvert toutes les méthodes et techniques que nous pouvons utiliser pour comparer deux tables en SQL.