Les pandas sont parmi les outils les plus populaires utilisés aujourd'hui par les data scientists pour analyser les données tabulaires. Pour gérer le contenu tabulaire, il propose une API plus rapide et plus efficace. Chaque fois que nous visualisons des blocs de données pendant l'analyse, Pandas définit automatiquement divers comportements d'affichage sur les valeurs par défaut. Ces comportements d'affichage incluent le nombre de lignes et de colonnes à afficher, la précision des flottants dans chaque bloc de données, la taille des colonnes, etc. En fonction des besoins, nous pouvons parfois être amenés à modifier ces valeurs par défaut. Les pandas ont une variété d'approches pour modifier le comportement par défaut. Tirer parti de l'attribut 'options' des pandas nous a permis de changer ce comportement.
Les pandas affichent le nombre maximum de lignes
Chaque fois que vous essayez d'imprimer un bloc de données volumineux contenant plus de lignes et de colonnes que le seuil prédéfini, la sortie sera rognée. Pour afficher toutes les lignes du DataFrame, vous apprendrez à modifier les options d'affichage de Pandas dans ce didacticiel. Les pandas imposent par défaut une limite au nombre de colonnes et de lignes qu'ils présentent. Bien que cela puisse être utile pour lire du contenu, cela provoque souvent de la frustration si les informations que vous devez afficher ne s'affichent pas. Ici, nous allons utiliser les méthodes données ci-dessous avec leur syntaxe pour afficher toutes les colonnes du dataframe.
to_string()

set_option()

option_context()

Nous apprendrons l'utilisation de toutes ces méthodes avec une mise en œuvre pratique pour afficher un maximum de lignes dans la base de données fournie.
Exemple # 1 : Utilisation de la méthode Pandas to_string()
Cette démonstration nous apprendra à afficher un maximum de lignes dans une dataframe sur le terminal en utilisant la méthode pandas 'to_string()'.
Pour la compilation et l'exécution des exemples de programmes, nous avons choisi l'outil « Spyder ». Dans ce guide, nous utiliserons cet outil pour l'exécution de tous nos exemples. Nous avons lancé l'outil 'Spyder' pour commencer à écrire le script python. En commençant par le code, nous devons d'abord charger les bibliothèques nécessaires dans notre fichier python afin que nous soyons autorisés à utiliser ses fonctionnalités. La bibliothèque de modules dont nous avons besoin ici est le 'Pandas'. Donc, nous l'avons importé dans notre fichier python et l'avons alias 'pd'.
Comme l'opération principale de cet article est d'afficher le maximum de lignes d'un dataframe, nous avons d'abord besoin d'un dataframe. C'est maintenant à vous de décider si vous préférez générer une dataframe ou importer un fichier CSV. Nous avons importé un exemple de fichier CSV. Pour lire un fichier CSV dans le programme python, nous avons utilisé la fonction pandas 'pd.read_csv()'. Entre les parenthèses de cette fonction, nous avons fourni le fichier CSV dont nous voulons lire l'affichage, qui est 'industry.csv'. Nous avons construit une variable 'df' pour stocker la sortie générée à partir de la lecture du fichier CSV fourni. Ensuite, nous avons invoqué la méthode 'print ()' pour afficher le dataframe.
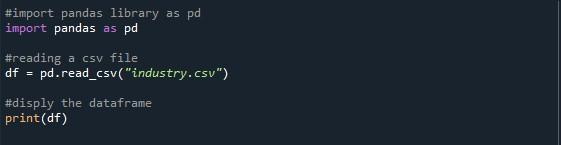
Lorsque nous exécutons ce programme python en appuyant sur l'option 'Exécuter le fichier', une trame de données est affichée sur la console. Vous pouvez observer qu'il y a 43 lignes dans le résultat ci-dessous mais seulement dix sont affichées. En effet, la valeur par défaut de la bibliothèque Pandas n'est que de 10 lignes.
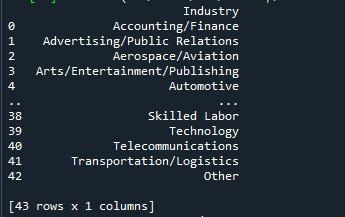
Nous utiliserons la méthode pandas 'to_string' pour afficher toutes les lignes ici. Le moyen le plus simple d'afficher le nombre maximal de lignes à partir d'un bloc de données consiste à utiliser cette technique. Cependant, comme il transforme la trame de données complète en une seule chaîne, il n'est pas recommandé pour les très grands ensembles de données (par millions). Néanmoins, cela fonctionne efficacement pour les ensembles de données qui se comptent par milliers.
Nous avons suivi la syntaxe fournie ci-dessus pour la fonction 'to_string()'. Nous avons simplement invoqué la méthode 'to_string()' avec le nom de notre dataframe. Ensuite, nous avons placé cette méthode dans la fonction 'print ()' pour l'afficher lorsqu'elle est appelée.

L'instantané de sortie nous montre une trame de données avec toutes les lignes affichées sur le terminal.
Exemple # 2 : Utilisation de la méthode set_option de Pandas
La deuxième méthode que nous allons pratiquer dans ce guide est les pandas 'set_option()' pour afficher le maximum de lignes de la dataframe fournie.
Dans le fichier python, nous avons importé la bibliothèque pandas pour accéder à la fonction mentionnée ci-dessus. Nous avons utilisé les pandas 'pd.read_csv()' pour lire le fichier CSV fourni. Nous avons invoqué la fonction 'pd.read_CSV()' avec le nom du fichier CSV que nous voulons utiliser entre ses parenthèses qui est 'Sampledata.csv'. Lors de l'importation du fichier CSV, gardez à l'esprit le répertoire de travail actuel du programme Python. Votre fichier CSV doit être placé dans le même répertoire ; sinon, vous obtiendrez un message d'erreur 'fichier introuvable'. Nous avons créé une variable 'échantillon' pour stocker la trame de données du fichier CSV. Nous avons appelé la méthode 'print()' pour afficher cette trame de données.
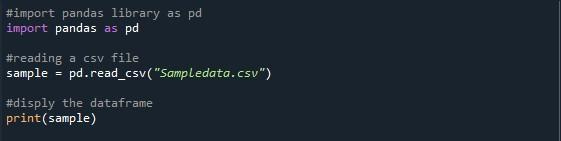
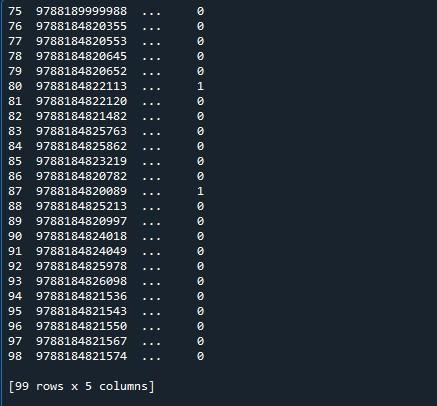
Ici, nous avons notre sortie où seulement dix lignes sont affichées. Le nombre maximum de lignes indiqué est de 99. Toutes les autres lignes entre les 5 premières et les 5 dernières lignes sont tronquées.

Pour afficher le maximum de lignes qui sont 99 pour cette dataframe, nous allons utiliser la fonction « set_option() » du module pandas. Les pandas sont livrés avec un système d'exploitation qui vous permet de modifier le comportement et l'affichage. Cette méthode nous permet de régler l'affichage pour qu'il présente une trame de données complète plutôt qu'une trame tronquée. Les pandas fournissent la fonction 'set_option()' pour afficher toutes les lignes du bloc de données.
Nous avons invoqué le 'pd.set_option()'. Cette fonction a des paramètres 'display.max_rows'. Le 'display.max_rows' spécifie le nombre maximum de lignes qui seront exposées lors de l'affichage d'un dataframe. La valeur de 'max_rows' est définie sur 10 par défaut. Si 'Aucun' est sélectionné, cela signifie toutes les lignes du bloc de données. Comme nous voulons afficher toutes les lignes, nous l'avons donc défini sur 'Aucun'. Enfin, nous avons utilisé la fonction 'print ()' pour afficher le dataframe avec un maximum de lignes.

Cela donne le résultat fourni dans l'instantané ci-dessous.
Exemple # 3 : Utilisation de la méthode Pandas option_context()
La dernière méthode dont nous discutons ici est la 'option_context ()' pour afficher toutes les lignes de la trame de données. Pour cela, nous avons importé le package pandas dans le fichier python et avons commencé à écrire le code. Nous avons utilisé la fonction 'pd.read_csv()' pour lire le fichier CSV que nous avons spécifié. Nous avons créé une variable 'dalta' pour stocker la trame de données du fichier CSV spécifié. Ensuite, nous avons simplement imprimé le dataframe avec la méthode « print() ».
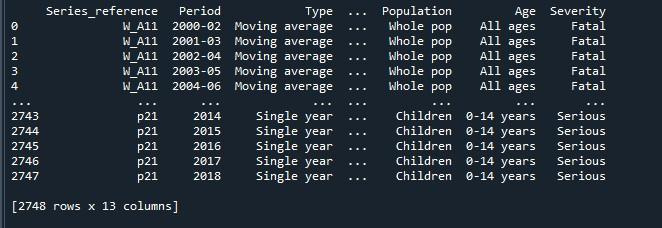
Le résultat que nous avons obtenu en exécutant le code ci-dessus nous montre une trame de données avec des lignes tronquées.
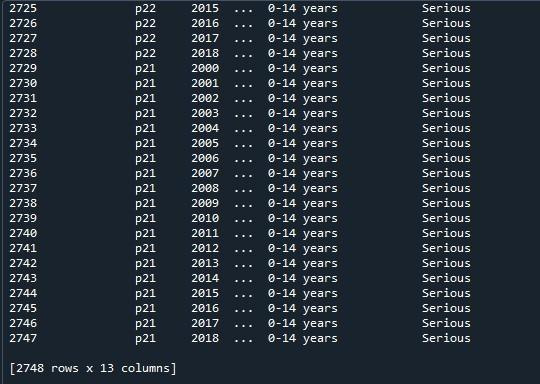
Nous allons maintenant appliquer les pandas 'pd.option_context()' sur cette dataframe. Cette fonction est identique à 'set_option()'. La seule différence entre les deux approches est que 'set_option()' modifie les paramètres de manière permanente, alors que 'option _context()' les a simplement modifiés dans son champ d'application. Cette méthode prend également les lignes display.max comme paramètre, que nous définissons sur 'Aucun' pour afficher toutes les lignes du bloc de données. Après avoir appelé cette fonction, nous l'avons simplement affichée via la méthode 'print ()'.

Ici, nous pouvons voir la trame de données complète avec ses lignes maximales qui sont 2747.
Conclusion
Cet article se concentre sur les options d'affichage des pandas. Nous pourrions parfois avoir besoin de visualiser la trame de données complète sur le terminal. Les pandas nous offrent une variété d'options à cette fin. Dans ce guide, nous avons utilisé trois de ces stratégies. Le premier exemple était basé sur l'utilisation de la méthode 'to_string()'. Notre seconde instance nous apprend à implémenter la méthode « set_option() » tandis que la dernière illustration exécute la méthode « option_context() ». Toutes ces techniques sont démontrées pour vous familiariser avec les moyens alternatifs que les pandas nous offrent pour atteindre le résultat requis.