'Python fournit une large gamme de structures de données et d'opérations pour gérer les données numériques et chronologiques. Le DataFrame que nous avons créé ou importé dans Pandas peut être utilisé à diverses fins. Les colonnes du bloc de données peuvent également être ajustées, ainsi que la source de données. Les pandas simplifient bon nombre des tâches fastidieuses et chronophages associées au traitement des données. Il existe quatre façons d'ajouter une colonne à un DataFrame dans Pandas, mais dans cet article, nous utilisons la fonction 'insert()' de la colonne panda.
Une fois que nous avons construit ou chargé notre dataFrame dans Pandas, il y a une variété de choses que nous pourrions vouloir accomplir. Par exemple, nous pourrions continuer à manipuler des données, par exemple, en modifiant les colonnes du bloc de données. Ensuite, nous devons comprendre comment inclure des colonnes dans une trame de données Si la majorité des données proviennent d'un fournisseur de données, mais que certaines données proviennent d'un autre. Une colonne peut être facilement ajoutée à un DataFrame Pandas.
Méthode pandas insert()
La dernière colonne du bloc de données est générée par une fonction différente. En utilisant la méthode DataFrame 'insert ()', vous pouvez ajouter des colonnes entre les colonnes actuelles plutôt que de les ajouter au bas du pandas DataFrame. Il nous offre la possibilité d'ajouter une colonne n'importe où, plutôt que simplement à la conclusion. De plus, il offre de nombreuses façons d'ajouter les valeurs des colonnes. Lorsque vous devez ajouter une colonne à une position ou à un index spécifié, la fonction pandas 'insert ()' est utile.
Syntaxe de la colonne Pandas insert()

Exemple 1 : Insertion d'une colonne dans un bloc de données à l'aide de la méthode Pandas insert()
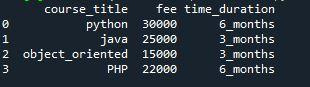
Commencez par le premier exemple de l'article, dans lequel nous expliquerons comment insérer une colonne dans un bloc de données. En utilisant l'outil 'spyder', nous pouvons prouver ce code. Tout d'abord, nous générons un bloc de données nommé 'course'. Nous avons deux colonnes dans ce bloc de données, 'course_title' et 'fee'. Dans la colonne « course_title » nous avons une liste de cours « python », « java », « object_oriented » et « PHP ». Dans la deuxième colonne 'frais', nous avons la liste des frais de cours qui est '30000', '25000', '15000' et '22000'. Afficher notre dataFrame, 'course', en utilisant 'pd. Trame de données'.
Ensuite, nous discuterons de la fonction principale du code, qui est pandas 'insert() column'. C'est une méthode efficace pour inclure une nouvelle liste dans le bloc de données. Vous pouvez ajouter la nouvelle colonne à n'importe quel endroit spécifié à l'aide de la méthode d'insertion. Cette méthode permet également l'ajout manuel d'une colonne à un bloc de données, mais il y a moins d'adaptabilité.
Tout au long de l'insertion signifie que le DataFrame source est directement mis à jour pendant le processus et qu'aucun nouveau DataFrame n'est créé. Dans ce cas, nous avons ajouté une nouvelle colonne à notre bloc de données avec le nom 'Time_duration' en utilisant la fonction 'insert()'. La liste des valeurs que nous avons dans cette colonne est '6_months', '3_months', '3months' et '6_months'. Nous avons une colonne 'Time_duration' avec un index défini comme '2' dans le programme ci-dessous. Depuis l'index spécifié, le DataFrame recevrait une plage qui commence à 0 et augmente par étapes, cela signifie donc que cette colonne est affichée comme une troisième colonne dans le bloc de données. Le DataFrame ajoute une nouvelle colonne nommée 'Time _duration' en utilisant la fonction 'pd.insert()'.
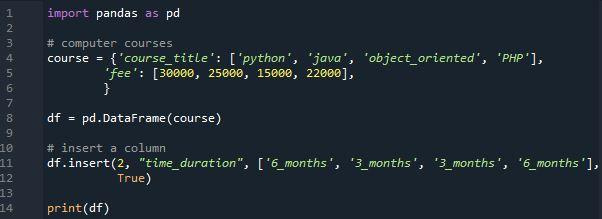
Et maintenant, discutons de la sortie du programme ci-dessus. Sa sortie montre un bloc de données qui a trois colonnes. La colonne supplémentaire est ajoutée à la fin du bloc de données. En utilisant la méthode 'pd.DataFrame.insert()', vous pouvez ajouter une colonne parmi d'autres colonnes au lieu de les ajouter à la fin des pandas DataFrame. 'Time_ duration' est une nouvelle colonne que nous avons ajoutée à l'aide de la fonction 'insertion'. fonction. La position '2' fait référence à la troisième colonne du DataFrame puisque la position commence à 0. La colonne est ajoutée à la dernière place du bloc de données.
Exemple 2 : Ajouter des colonnes dans un bloc de données à l'aide de la fonction insert() de Pandas
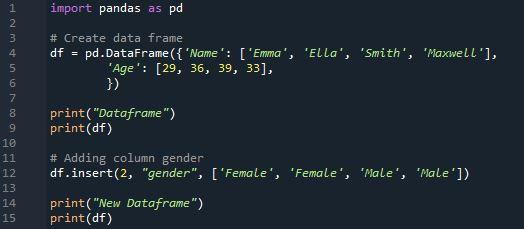
Nous utiliserons la méthode 'insert ()' pour ajouter de nouvelles colonnes au bloc de données. Au lieu d'ajouter des colonnes supplémentaires à la fin des pandas, vous pouvez les insérer entre les colonnes existantes. Pour générer un bloc de données similaire à l'exemple précédent, nous avons pris trois colonnes et leur avons attribué des valeurs. Dans la première colonne, 'Nom', nous avons une liste de noms qui incluent 'Emma', 'Ella', 'Smith' et 'Maxwell'. Dans la deuxième colonne « Âge », la liste des valeurs contient « 29 », « 36 », « 39 » et « 33 ».
Après cela, nous imprimons une déclaration 'DataFrame'. Nous allons afficher le bloc de données sous l'instruction « bloc de données ». Nous créons une colonne supplémentaire pour le bloc de données Pandas à l'aide de la fonction 'insert()'. Une liste doit être créée afin qu'elle puisse être ajoutée en tant que nouvelle colonne à notre ensemble de données donné. La méthode 'assign()' du pandas DataFrame peut également être utilisée pour ajouter plus de colonnes. Nous insérons une nouvelle colonne en utilisant 'df. insérer'. La colonne supplémentaire nommée « Sexe » affiche le sexe sous la forme « Male » ou « Female ».
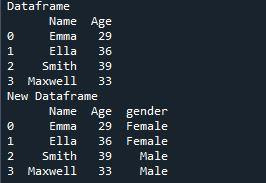
Imprimons simplement une autre déclaration, 'New Dataframe'. Une nouvelle trame de données sera maintenant présentée sous l'instruction 'New Dataframe', contenant la colonne supplémentaire que nous avons ajoutée avec le 'pd. fonction insérer()'. La colonne avec un nom similaire ne peut pas être ajoutée à l'aide de la fonction 'insert()'. Dans le cas où une colonne existe déjà dans le bloc de données, une erreur de valeur est générée par défaut.
Dans cette sortie, la colonne que nous avons créée en utilisant la fonction 'insert()' est ajoutée au bloc de données. Sa sortie affiche deux trames de données ; le premier dataFrame a été créé en utilisant 'pd.data frame', dans lequel nous avons deux colonnes, 'Name' et 'Age'. La nouvelle colonne 'gender' que nous avons ajoutée à l'aide de la fonction 'insert()' est affichée dans le deuxième bloc de données affiché ci-dessous. Ce bloc de données montre qu'il y a trois colonnes contenant des données. L'index est de taille '2', ce qui signifie qu'il a des entrées de '0 à 3'. La nouvelle colonne que nous avons attribuée à ce bloc de données a une position d'index de '3'.
Conclusion
Une opération d'analyse et de mise à jour de données couramment utilisée consiste à ajouter des colonnes à DataFrame. Cependant, Pandas vous offre de nombreuses options pour accomplir la tâche en proposant quatre méthodes différentes ; cependant, nous n'utilisons qu'une seule technique, qui est la colonne panadas 'insert()', dans notre article. L'une des parties les plus difficiles de l'extension d'un DataFrame avec de nouvelles colonnes est l'indexation. Décrivons rapidement les deux exemples. Nous avons d'abord créé un bloc de données intitulé cours et ajouté les colonnes 'titre du cours' et 'frais' et attribué des valeurs à cette colonne. À l'aide de la fonction 'insert ()', nous ajoutons ensuite une nouvelle colonne au même bloc de données indiquant sa position en tant que '2' dans l'index. Dans le deuxième exemple, deux dataFrames sont affichés. Nous avons créé deux colonnes et répertorié certaines valeurs dans le premier bloc de données. Ensuite, en utilisant la fonction insert(), nous avons inséré une nouvelle colonne dans le bloc de données nommée « Sexe », elle a également été positionnée comme « 2 » dans l'index ; maintenant, il affiche à nouveau le tableau, comme indiqué dans le deuxième exemple ci-dessus.
Après avoir maîtrisé les techniques ci-dessus, nous pouvons facilement ajouter de nouvelles colonnes au DataFrame.