Ce guide explique la validation croisée et son fonctionnement à l'aide du service AWS.
Qu'est-ce que la validation croisée ?
La validation croisée permet aux développeurs de comparer différents modèles d'apprentissage automatique et d'avoir une idée de leur fonctionnement dans la vie réelle. Il aide l'utilisateur à déterminer quel modèle d'apprentissage automatique (ML) ou d'apprentissage en profondeur (DL) fonctionnera le mieux pour une donnée ou un scénario particulier. Il existe des situations où plusieurs modèles peuvent être utilisés pour un ensemble de données. Ici, les développeurs utilisent la validation croisée pour obtenir un modèle adapté afin d'obtenir des résultats optimisés :
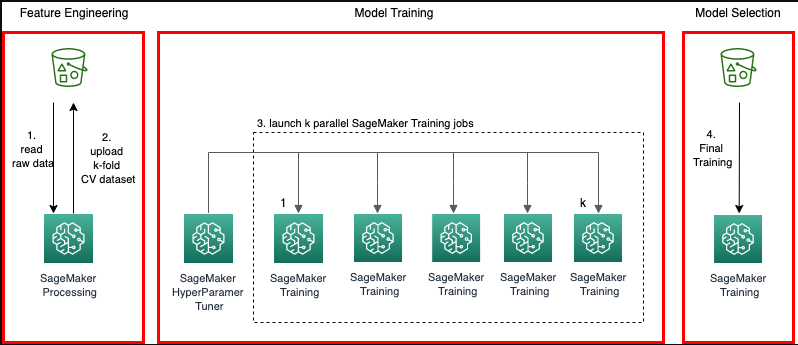
Comment fonctionne la validation croisée ?
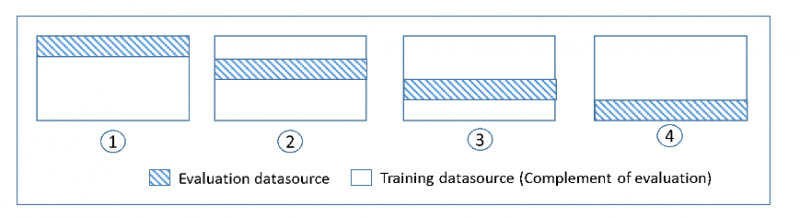
Pour vérifier les modèles ML sur un ensemble de données, l'utilisateur doit estimer les caractéristiques du modèle, ce que l'on appelle l'apprentissage de l'algorithme. Une autre chose à vérifier est l'évaluation du modèle pour déterminer ses performances et cela s'appelle le test du modèle. Ce n'est pas une bonne idée de tester le modèle sur toutes les données, cependant, nous utilisons 75 % des données pour la formation et 25 % pour les tests afin d'obtenir de meilleurs résultats. La validation croisée effectue des tests sur tous les 25 % des données pour vérifier quel bloc fonctionne le mieux :
Qu'est-ce qu'Amazon SageMaker ?
La validation croisée dans AWS peut être effectuée à l'aide du service Amazon SageMaker, car il est conçu pour créer, former et déployer des modèles d'apprentissage automatique. Il aide les data scientists et les développeurs à préparer les données pour créer des modèles ML ou DL efficaces en réunissant des fonctionnalités spécialement conçues. Ces capacités sont utiles pour construire des modèles optimisés et précis qui pourront s'améliorer au fil du temps :

Fonctionnalités d'Amazon SageMaker
Amazon SageMaker est un service géré et ne nécessite pas la gestion d'environnements ML. Il a besoin de beaucoup de données pour former et créer des modèles ML afin qu'il se connecte bien aux services Amazon S3 ou Amazon Redshift pour collecter des données. Les données brutes peuvent être difficiles à obtenir, elles nécessitent donc également des fonctionnalités pour créer des modèles. Utilisez ensuite les données pour former des modèles, puis effectuez des tests dessus en utilisant tous les 25 % des données pour obtenir de meilleurs résultats/prédictions :
Tout tourne autour de la validation croisée dans AWS.
Conclusion
La validation croisée est le processus permettant d'obtenir le modèle optimal d'apprentissage automatique ou d'apprentissage en profondeur pour que les données obtiennent de meilleurs résultats. Il effectuera des tests pour chaque section de 25 % des données afin de comprendre quel bloc fournit la sortie maximale, ce qui en fait un modèle d'ajustement approprié. AWS fournit le service SageMaker pour effectuer une validation croisée et créer des modèles d'apprentissage automatique sur le cloud. Ce guide a expliqué le processus de validation croisée et son fonctionnement dans AWS.