- Il n'écrase pas les données récupérées mais comble les lacunes en cas de récupération itérative. Cependant, il peut être tronqué si l'outil est invité à le faire explicitement.
- Récupérez des données dans un seul fichier à partir de plusieurs fichiers ou blocs.
- Prend en charge plusieurs types d'interfaces de périphériques telles que les lecteurs SATA, ATA, SCSI, MFM, les disquettes et les cartes SD.
Dans ce guide, j'explorerai cet outil de récupération de données incroyablement utile. Je discuterai également de son processus d'installation et de la façon de l'utiliser pour récupérer un périphérique ou une partition bloc.
- Installation de Ddrescue
- Comprendre les bases
- Considérations importantes
- Utiliser ddrescue
- Récupérer le bloc corrompu
- Restauration du fichier image dans un nouveau bloc
- Récupération d'un bloc vers un autre bloc
- Récupération de données spécifiques à partir des fichiers image récupérés
- Fonctionnalités avancées
- Comment fonctionne le sauvetage
- Conclusion
Note: J'utilise la distribution Linux (Ubuntu 22.04) pour les instructions de ce guide. Le processus d'installation de l'utilitaire ddrescue peut différer, mais les instructions seront les mêmes dans toutes les distributions Linux.
Installation de Ddrescue
Pour installer ddrescue sous Linux, notamment Ubuntu et ses saveurs ou Basé sur Debian distributions, utilisez :
sudo apte installer gddrescue
Pour l'installer sur REHL , Feutre , et CentOS , activez d'abord le CHAUD (Packages supplémentaires pour Enterprise Linux).
sudo miam, installe libération chaude
La commande ci-dessus concerne les versions plus récentes de la distribution respective.
Exécutez ensuite la commande suivante pour installer le ddrescue :
sudo miam, installe sauvetagePour les distributions Linux basées sur Arch telles que Arch-Linux et Manjaro , utilisez la commande ci-dessous pour installer l'utilitaire de récupération ddrescue.
sudo Pac-Man -S sauvetage
Puisque j'utilise Ubuntu 22.04, j'utiliserai le gestionnaire de packages APT pour l'installer.
Comprendre les bases
Avant d'utiliser l'outil ddrescue pour récupérer des données, je recommanderais aux utilisateurs novices dans le processus de récupération de comprendre certaines conventions de dénomination de Linux.
Linux reconnaît les blocs (périphériques) comme des fichiers et les place dans le /dév annuaire. Pour lister les fichiers du répertoire /dev, utilisez le ls /dev commande.
Le disques durs (blocs de stockage) sont représentés par Dakota du Sud suivi des alphabets; dans le cas de plusieurs périphériques de stockage, les fichiers seront représentés comme /dev/sd un, /dev/sd b, et ainsi de suite.
Si le périphérique de stockage a cloisons , ils seront alors représentés par un numéro avec le nom du fichier de lecteur respectif, tel que /dev/sda 1 , /dev/sda 2 , et ainsi de suite.
Pour lister tous les blocs et autres appareils connectés au système, utilisez le bloc liste lsblk commande:
lsblk 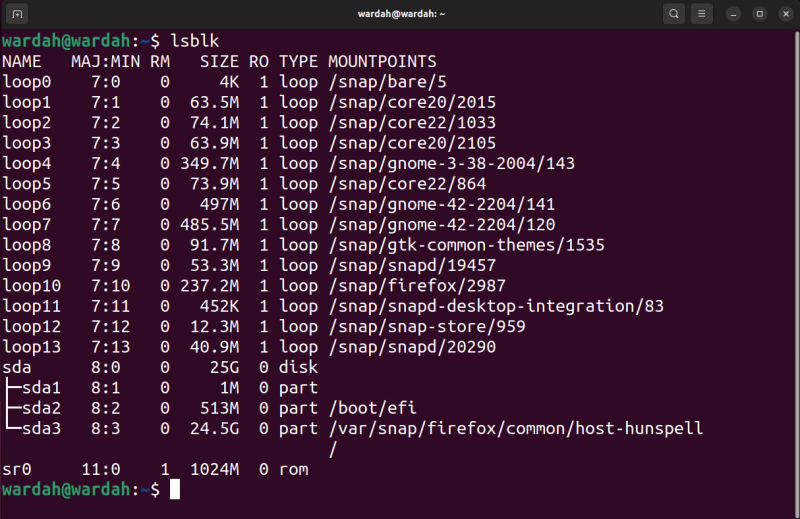
La commande ddrescue peut également récupérer le bloc entier (contenant le MBR et les partitions) ou une partition. D'un autre côté, si vous devez récupérer uniquement des fichiers spécifiques à partir d'une partition spécifique, il est préférable de récupérer la partition plutôt que le bloc entier.
Considérations importantes
Avant d'utiliser l'utilitaire ddrescue, certains points très clés doivent être pris en compte :
- N'essayez pas de récupérer un bloc monté, le bloc ne doit même pas être en mode lecture seule.
- N'essayez pas de réparer un bloc comportant des erreurs d'E/S.
- Le système peut modifier les noms des périphériques d'entrée et de sortie au redémarrage. Assurez-vous que les noms des périphériques sont corrects avant de démarrer le processus de copie.
- Si vous utilisez un bloc séparé comme périphérique de sortie, toutes les données présentes sur le périphérique seront écrasées.
Utiliser ddrescue
Après avoir installé l'utilitaire ddrescue et compris les conventions de dénomination, l'étape suivante consiste à identifier le disque défaillant et à le récupérer à l'aide de l'outil ddrescue.
Récupérer le bloc corrompu
Le premier exemple englobera le processus de récupération de l’intégralité du bloc. Tout d’abord, listez les blocs à l’aide du lsblk commande:
lsblk -O NOM, TAILLE, TYPE DE FSLe -O flag est utilisé pour spécifier le type d’informations (champs) que la commande doit générer. J'ai mentionné le NOM , TAILLE , et TYPEFS ou le type de système de fichiers.
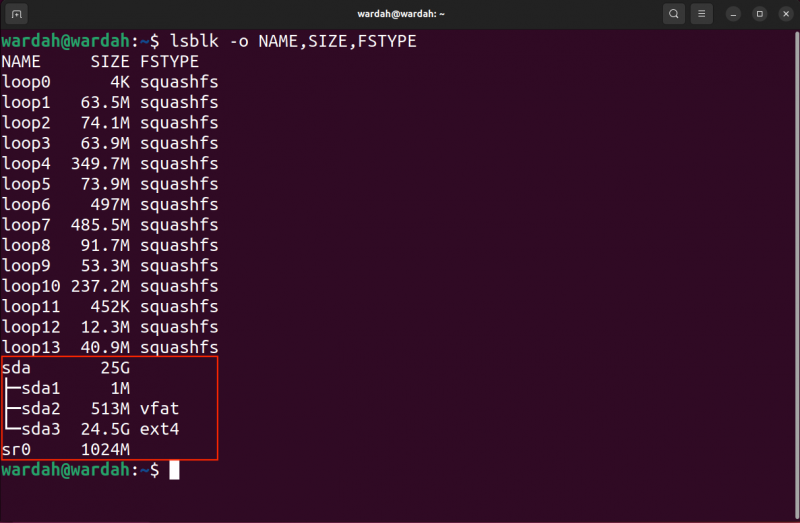
Vous pouvez désormais identifier le bloc cible, la partition et l'emplacement pour enregistrer le fichier image récupéré.
Une autre chose importante à noter est que sous Linux, le nom du bloc est attribué dynamiquement au démarrage et après le redémarrage, les noms des blocs peuvent changer. Soyez donc prudent lorsque vous notez les noms des blocs.
Maintenant, utilisez la syntaxe suivante pour récupérer le bloc en tant que fichier image avec un fichier journal dans le répertoire racine.
sudo sauvetage -d -rX / développeur / [ bloc ] [ chemin / nom ] .img [ nom_fichier_journal ] .enregistrerNote: Remplacer [bloc] , [chemin/nom] du fichier image, et [nom_fichier journal] avec les noms préférés en conséquence.
Dans cet exemple, je récupère le /dev/sda dans le répertoire racine avec le nom du fichier image récupération.img . Le fichier journal, également appelé fichier map, est essentiel si vous souhaitez reprendre la récupération à tout moment.
sudo sauvetage -d -r2 / développeur / sda2 recovery.img recovery.logDeux indicateurs importants sont utilisés dans la commande ci-dessus.
| d | -indirect | Est utilisé pour indiquer à l'outil d'accéder directement au disque en ignorant le cache du noyau |
| rX | –réessayer-passes | Utilisé pour indiquer à l'outil de réessayer le secteur défectueux X nombre de fois |
En exécutant la commande ci-dessus, vous remarquerez deux fichiers apparaissant dans le navigateur de fichiers avec les noms récupération.img et journal de récupération .
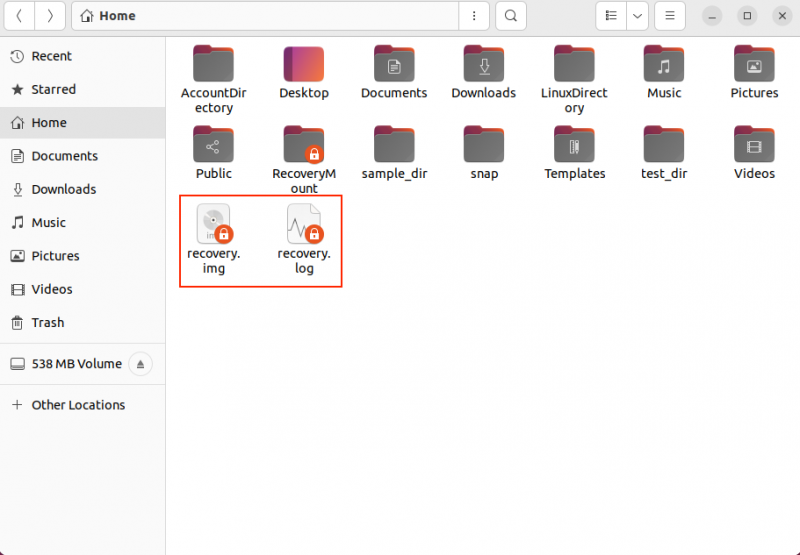
Le temps de récupération dépend de la taille du bloc d'entrée et des dégâts. Si vous récupérez un bloc volumineux, je vous recommande d'avoir un fichier journal car le processus peut prendre plusieurs heures, voire plusieurs jours.
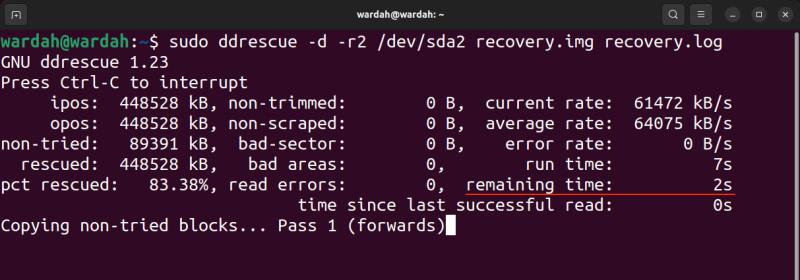
Le résultat de la commande ci-dessus est donné ci-dessous :
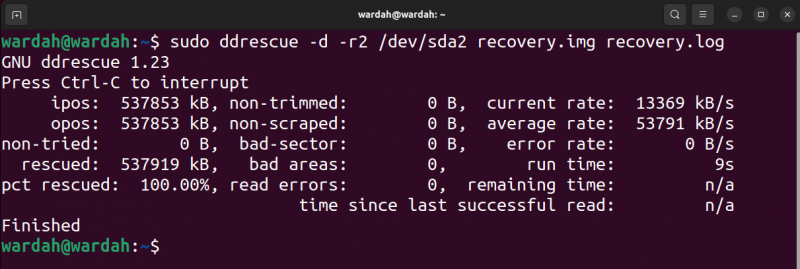
Dans l'image de sortie, ipos est la position d'entrée du fichier d'entrée à partir de laquelle la copie commence et le ulcères est la position de sortie sur le fichier de sortie où les données sont en cours d'écriture.
Le non essayé c'est la taille du bloc qui n'est pas en attente d'être essayée. Le sauvé indique la taille du bloc récupéré avec succès. Le PCT sauvé indique la récupération réussie des données en pourcentage. Les termes, non découpé , non mis au rebut , mauvais secteur , et mauvaises zones sont explicites. Cependant, le lire les erreurs Le terme indique les tentatives de lecture ayant échoué en chiffres.
Le Durée indique le temps nécessaire à l'outil pour terminer le processus, tandis que le temps restant est le temps restant pour terminer le processus de récupération. La sortie ci-dessus montre le temps restant 0 car le processus est terminé, lisez la sortie dans l'image suivante d'un processus inachevé.
Voyons ce que nous obtenons dans le fichier journal ; pour ouvrir le fichier journal généré, utilisez le vim recovery.log commande.
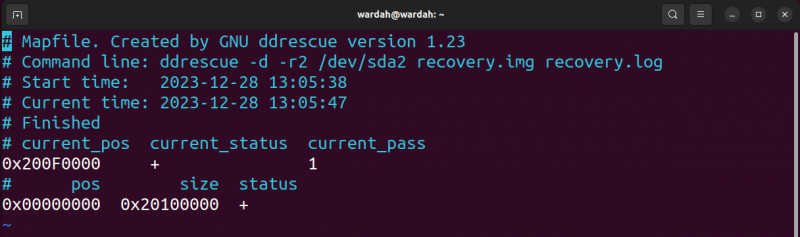
Le statut actuel est + ce qui signifie que le processus est terminé, tandis que le pos_actuel est la position sur le bloc.
Une liste des statuts actuels est donnée dans le tableau suivant :
| ? | Copier |
| * | Garniture |
| / | Mise au rebut |
| – | Réessayer |
| F | Remplir les blocs spécifiés |
| g | Génération du fichier journal |
| + | Le processus est terminé |
En dessous, le fichier journal contient des indications d'état des blocs précédemment sauvés sous la forme des caractères répertoriés ci-dessous :
| ? | Le bloc n'est pas essayé |
| * | Le bloc défaillant non tronqué |
| / | Le bloc défaillant non supprimé |
| – | Le bloc défaillant du secteur défectueux |
| + | Bloc terminé |
Restauration du fichier image dans un nouveau bloc
Une fois que vous avez terminé le processus de récupération et que vous disposez du fichier image. Vous souhaiterez peut-être maintenant qu'il soit déplacé vers le nouveau lecteur à partir d'un lecteur corrompu. Pour déplacer le fichier image vers un nouveau bloc, connectez d'abord ce bloc au système, puis identifiez le nom du bloc à l'aide du lsblk commande.
Supposons que ce soit le cas /dev/sdb , utilisez la commande suivante pour copier l'image dans un nouveau bloc.
sudo sauvetage -F récupération.img / développeur / fichier journal sdb.logLe -F L'indicateur est utilisé pour écraser le nouveau bloc s'il y a des données. Gardez à l’esprit que le nom du fichier journal doit être différent pour le distinguer du fichier journal précédemment stocké.
L'opération ci-dessus peut également être effectuée à l'aide du jj , une autre commande puissante utilisée pour copier les fichiers.
sudo jj si =récupération.img de = / développeur / SDBAvant d'effectuer une restauration, gardez à l'esprit que le nouveau bloc doit être suffisamment grand pour conserver l'intégralité du bloc récupéré ; par exemple, si le bloc de récupération est de 5 Go, le nouveau bloc doit être supérieur à 5 Go.
Si le fichier image récupéré présente un grand nombre d'erreurs, elles peuvent alors être réparées à l'aide du fsck commande sous Linux dans une certaine mesure. Sous Windows, vous pouvez utiliser le CHKDSK ou SFC commandes pour ce faire. Cependant, la récupération dépend du nombre d'erreurs générées par le fichier corrompu.
Maintenant, le processus de récupération et de restauration est terminé. Une autre chose importante à noter est que vous pouvez récupérer un bloc corrompu directement sur un autre bloc, au lieu de créer un fichier image puis de le copier dans le nouveau bloc. Eh bien, dans la section suivante, je couvre ce processus en détail.
Récupération d'un bloc vers un autre bloc
Pour récupérer un bloc directement sur un nouveau bloc, connectez d'abord le bloc au système et utilisez à nouveau lsblk commande pour identifier le nom du bloc. Des noms de blocs incorrects peuvent gâcher l'ensemble du processus et vous risquez de perdre des données.
Après avoir identifié le bloc source et le bloc destination, utilisez la commande suivante pour récupérer le bloc :
sudo sauvetage -d -F -r2 / développeur / [ source ] / développeur / [ destination ] sauvegarde.logAssumons /dev/sdb est le bloc de destination, donc pour copier le /dev/sda répertoire vers le nouveau bloc utiliser :
sudo sauvetage -d -F -r2 / développeur / sda / développeur / sauvegarde sdb.logEncore une fois, consultez les considérations critiques mentionnées dans les sections précédentes avant de tenter ce processus.
Récupération de données spécifiques à partir des fichiers image récupérés
Dans de nombreux cas, le but de la récupération de données est de trouver les fichiers spécifiques des lecteurs corrompus. Pour accéder au fichier spécifique, vous devez monter le fichier image. Sous Linux, le fichier image récupéré peut être exploré en utilisant le monter commande.
Avant de monter le fichier image, créez un dossier ou un répertoire dans lequel vous souhaitez extraire le contenu du fichier image.
mkdir Montage de récupérationEnsuite, montez le fichier image en utilisant :
sudo monter -O récupération de boucle.img ~ / Montage de récupérationL'indicateur -o indique les options, tandis que l'option de boucle est utilisée pour traiter le fichier image comme un périphérique bloc.
Vous avez maintenant accès au contenu du fichier image, comme indiqué dans la capture d'écran suivante.
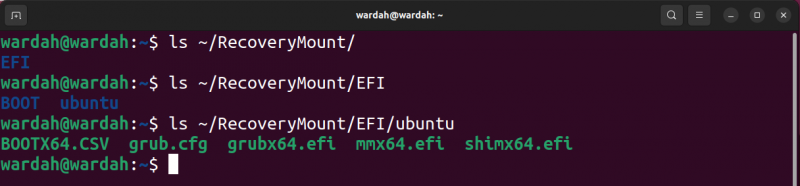
Pour démonter le bloc, utilisez le démonter commande.
sudo démonter ~ / Montage de récupérationFonctionnalités avancées
Pour démarrer la récupération à partir d'un point spécifique, utilisez le -je drapeau ou –position d'entrée . Il doit être en octets, par défaut c'est le cas 0 octets. Ceci est important pour reprendre la copie à partir d’un point précis. Par exemple, si vous souhaitez commencer le processus de copie à partir du point de 10 Go, utilisez la commande suivante.
sudo sauvetage -i10Gio / développeur / sda imagefile.img logfile.logPour définir la taille maximale du périphérique d'entrée, le -s le drapeau sera utilisé. Le -s signifie la taille et peut également être utilisé comme -taille en octets. Si l'outil ne parvient pas à reconnaître la taille du fichier d'entrée, utilisez cette option pour la spécifier.
sudo sauvetage -s10Gio / développeur / sda imagefile.img logfile.logLe -demander L'option peut être très pratique, car elle demande la confirmation des blocs d'entrée et de sortie avant de commencer le processus de copie. Comme indiqué précédemment, le système attribue dynamiquement des noms aux blocs et ils changent au redémarrage. Donc, dans ce cas, cette option peut être utile.
sudo sauvetage --demander / développeur / sda imagefile.img logfile.logDe plus, une liste de quelques autres options est mentionnée ci-dessous :
| -R | -inverse | Pour inverser le sens de la copie |
| -q | -assez | Pour supprimer tous les messages de sortie |
| -dans | -verbeux | Pour élaborer, tous les messages de sortie |
| -p | –préallouer | Pour pré-allouer de l'espace de stockage pour le fichier de sortie |
| -P | –aperçu des données | Les lignes d'affichage des dernières données lues par défaut sont 3 lignes |
Comment fonctionne le sauvetage
Le ddrescue utilise un puissant algorithme de récupération divisé en quatre phases :
1. Copie
2. Découpage
3. Grattage
4. Réessayer
L'exécution de l'algorithme ddrescue est illustrée dans l'image suivante.

Conclusion
Le sauvetage est un outil de récupération puissant utilisé pour récupérer les données d'un disque corrompu ou défaillant vers un autre disque en copiant les données. Il peut être installé sans effort sur n'importe quelle distribution Linux à l'aide du gestionnaire de packages par défaut. Notez la considération importante avant d’utiliser cet outil mentionnée dans ce guide. Le processus de copie des données est simple, démontez le lecteur et utilisez la commande ddrescue avec le nom du lecteur source et le nom du lecteur de destination. N'oubliez pas d'utiliser le fichier journal, car il devient très utile pour reprendre le processus de récupération.