Dans cet article, nous verrons comment allouer DIFFÉRENT mémoire via le ' pytorch_cuda_alloc_conf ' méthode.
Qu'est-ce que la méthode « pytorch_cuda_alloc_conf » dans PyTorch ?
Fondamentalement, le « pytorch_cuda_alloc_conf » est une variable d'environnement dans le framework PyTorch. Cette variable permet une gestion efficace des ressources de traitement disponibles, ce qui signifie que les modèles s'exécutent et produisent des résultats dans le moins de temps possible. Si ce n'est pas fait correctement, le ' DIFFÉRENT ' La plateforme de calcul affichera le ' Mémoire insuffisante ' erreur et affecter le temps d'exécution. Modèles qui doivent être entraînés sur de grands volumes de données ou qui ont de grandes « tailles de lots ' peut produire des erreurs d'exécution car les paramètres par défaut peuvent ne pas leur suffire.
Le ' pytorch_cuda_alloc_conf 'La variable utilise ce qui suit' choix ' pour gérer l'allocation des ressources :
- indigène : Cette option utilise les paramètres déjà disponibles dans PyTorch pour allouer de la mémoire au modèle en cours.
- max_split_size_mb : Il garantit que tout bloc de code plus grand que la taille spécifiée n'est pas divisé. Il s’agit d’un outil puissant pour prévenir « fragmentation ». Nous utiliserons cette option pour la démonstration de cet article.
- roundup_power2_divisions : Cette option arrondit la taille de l’allocation au « » le plus proche. puissance de 2 » division en mégaoctets (Mo).
- roundup_bypass_threshold_mb : Il peut arrondir la taille d'allocation pour toute demande listant plus que le seuil spécifié.
- garbage_collection_threshold : Il évite la latence en utilisant la mémoire disponible du GPU en temps réel pour garantir que le protocole de récupération de tout n'est pas lancé.
Comment allouer de la mémoire à l'aide de la méthode « pytorch_cuda_alloc_conf » ?
Tout modèle avec un ensemble de données important nécessite une allocation de mémoire supplémentaire supérieure à celle définie par défaut. L'allocation personnalisée doit être spécifiée en tenant compte des exigences du modèle et des ressources matérielles disponibles.
Suivez les étapes ci-dessous pour utiliser le « pytorch_cuda_alloc_conf ' dans l'IDE Google Colab pour allouer plus de mémoire à un modèle d'apprentissage automatique complexe :
Étape 1 : Ouvrez Google Colab
Rechercher Google Collaboratif dans le navigateur et créez un ' Nouveau cahier » pour commencer à travailler :
Étape 2 : configurer un modèle PyTorch personnalisé
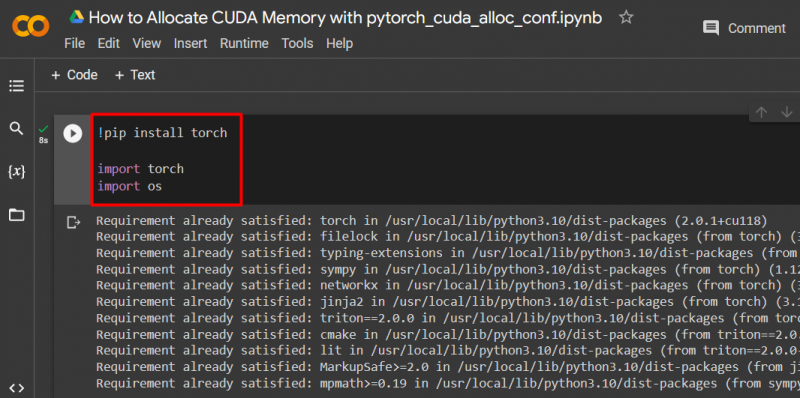
Configurez un modèle PyTorch en utilisant le « !pépin ' package d'installation pour installer le ' torche ' bibliothèque et le ' importer « commande pour importer » torche ' et ' toi ' bibliothèques dans le projet :
importer une torche
importez-nous
Les bibliothèques suivantes sont nécessaires pour ce projet :
- Torche – Il s’agit de la bibliothèque fondamentale sur laquelle est basé PyTorch.
- TOI - Le ' système opérateur ' La bibliothèque est utilisée pour gérer les tâches liées aux variables d'environnement telles que ' pytorch_cuda_alloc_conf » ainsi que le répertoire système et les autorisations de fichiers :
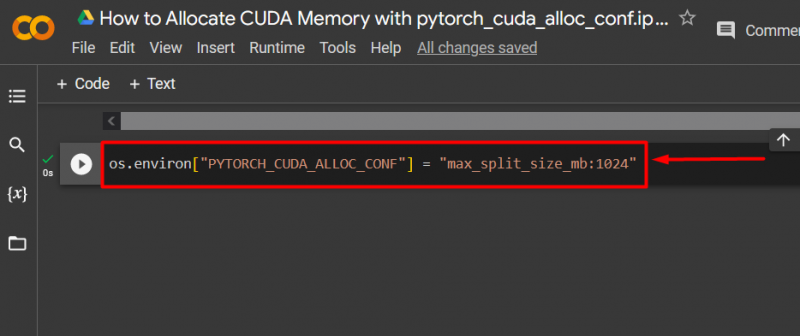
Étape 3 : allouer de la mémoire CUDA
Utilisez le ' pytorch_cuda_alloc_conf ' méthode pour spécifier la taille de division maximale à l'aide de ' max_split_size_mb » :
Étape 4 : Continuez votre projet PyTorch
Après avoir précisé « DIFFÉRENT ' attribution d'espace avec le ' max_split_size_mb ', continuez à travailler sur le projet PyTorch comme d'habitude sans craindre le ' Mémoire insuffisante ' erreur.
Note : Vous pouvez accéder à notre bloc-notes Google Colab à cette adresse lien .
Conseil de pro
Comme mentionné précédemment, le « pytorch_cuda_alloc_conf ' La méthode peut prendre n'importe laquelle des options fournies ci-dessus. Utilisez-les en fonction des exigences spécifiques de vos projets de deep learning.
Succès! Nous venons de démontrer comment utiliser le « pytorch_cuda_alloc_conf ' méthode pour spécifier un ' max_split_size_mb » pour un projet PyTorch.
Conclusion
Utilisez le ' pytorch_cuda_alloc_conf ' méthode pour allouer de la mémoire CUDA en utilisant l'une de ses options disponibles selon les exigences du modèle. Ces options visent chacune à atténuer un problème de traitement particulier dans les projets PyTorch pour de meilleurs temps d'exécution et des opérations plus fluides. Dans cet article, nous avons présenté la syntaxe pour utiliser le « max_split_size_mb » pour définir la taille maximale du fractionnement.