Premiers pas avec Apache Kafka
Avant d'installer Apache Kafka, vous devez avoir Java installé et un compte utilisateur avec des privilèges sudo. De plus, il est recommandé d'avoir une RAM de 2 Go et plus pour le bon fonctionnement de Kafka.
Les étapes suivantes vous guideront sur la façon d'installer Apache Kafka.
Installation de Java
Java est requis pour installer Kafka. Vérifiez si votre Ubuntu a un Java installé en vérifiant la version à l'aide de la commande suivante :
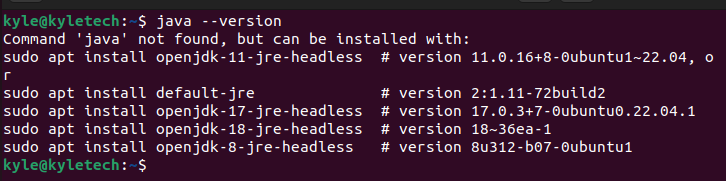
$ Java --version
Si Java n'est pas installé, utilisez les commandes suivantes pour installer Java OpenJDK.
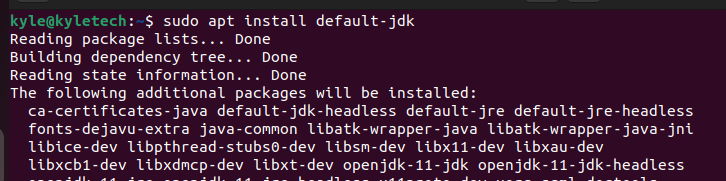
$ sudo apte installer par défaut-jdk
Création d'un compte utilisateur
Avec Java déjà installé, créez un compte utilisateur non root. Nous devons également lui donner des privilèges sudo en ajoutant l'utilisateur au groupe sudo à l'aide de la commande suivante :
$ sudo adduser linuxhint
$ sudo adduser linuxhint sudo

Connectez-vous au compte utilisateur nouvellement créé.

Installer Kafka
Vous devez télécharger la dernière version d'Apache Kafka à partir de la page de téléchargement officielle. Téléchargez ses fichiers binaires en utilisant le wget commande comme indiqué ci-dessous :
$ wget https : // downloads.apache.org / kafka / 3.2.3 / kafka_2.12-3.2.3.tgz 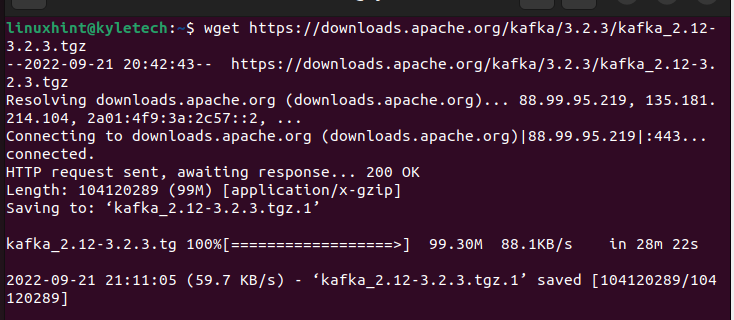
Une fois le fichier binaire téléchargé, extrayez-le en utilisant le prend commande et déplacez le répertoire extrait vers le /opt/kafka.
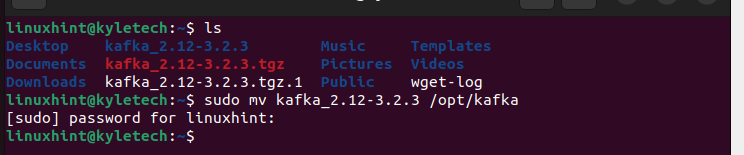
Ensuite, créez le scripts systemd pour le Gardien de zoo et le Kafka services qui aident au démarrage et à l'arrêt des services.
Utilisez un éditeur de choix pour créer les scripts systemd et collez le contenu suivant. Commencez par le gardien du zoo :
$ sudo nano / etc / systemd / système / zookeeper.serviceCollez ce qui suit :
[ Unité ]La description =Serveur Apache Zookeeper
Documentation = http : // zookeeper.apache.org
A besoin =network.target remote-fs.target
Après =network.target remote-fs.target
[ Service ]
Taper =simple
ExecStart = / opter / kafka / poubelle / zookeeper-server-start.sh / opter / kafka / configuration / zookeeper.properties
ExecStop = / opter / kafka / poubelle / zookeeper-server-stop.sh
Redémarrer =sur-anormal
[ Installer ]
RecherchéPar =multi-utilisateur.cible
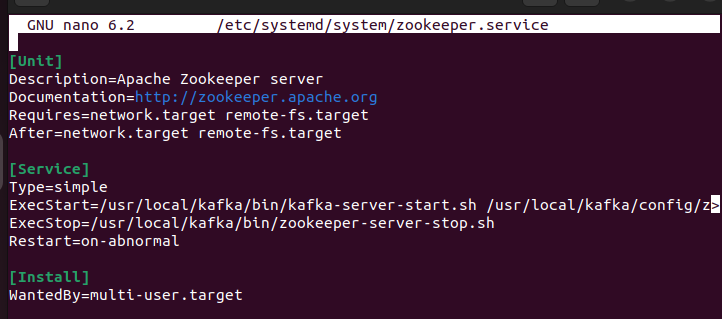
Enregistrez le fichier. Créez le fichier systemd pour Kafka et collez le contenu suivant :
Lors du collage, assurez-vous de définir le bon chemin pour le Java que vous avez installé sur votre système.
[ Unité ]La description = Serveur Apache Kafka
Documentation = http : // kafka.apache.org / documentation.html
A besoin =zookeeper.service
[ Service ]
Taper =simple
Environnement = 'JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64'
ExecStart = / opter / kafka / poubelle / kafka-server-start.sh / opter / kafka / configuration / serveur.propriétés
ExecStop = / opter / kafka / poubelle / kafka-server-stop.sh
Redémarrer =sur-anormal
[ Installer ]
RecherchéPar =multi-utilisateur.cible
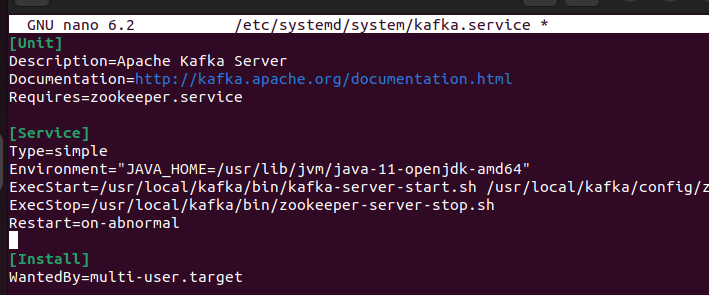
Une fois cela fait, appliquez les modifications en rechargeant le démon systemd :

Ensuite, activez le service Zookeeper et démarrez-le à l'aide des commandes suivantes :
$ sudo systemctl démarrer zookeepe < fort > r fort >

Vous devez également faire la même chose pour le Kafka :
$ sudo systemctl démarrer kafka

Une fois que vous démarrez les services, vous pouvez vérifier leur statut avant de créer un sujet dans Kafka.


La bonne chose avec Kafka est qu'il existe plusieurs scripts que vous pouvez utiliser.
Créons un nouveau sujet nommé linuxhint1 en utilisant le kafka-topics.sh script avec une partition et une réplication. Utilisez la commande suivante :
$ sudo -dans linuxhint / opter / kafka / poubelle / kafka-topics.sh --créer --bootstrap-serveur hôte local : 9092 --replication-facteur 1 --partitions 1 --sujet linuxhint1 
Notez que notre sujet est créé. Nous pouvons voir le message précédent pour le vérifier.
Vous pouvez également répertorier les rubriques disponibles à l'aide de la -liste option dans la commande suivante. Il devrait renvoyer le sujet que nous avons créé :S
$ sudo -dans linuxhint / opter / kafka / poubelle / kafka-topics.sh --liste --bootstrap-serveur hôte local : 9092 
Une fois le sujet Kafka créé, vous pouvez commencer à écrire les données des flux sur le Kafka-console-producer.sh et vérifiez si cela se reflète dans votre consommateur.sh.
Ouvrez votre shell et accédez au sujet que nous avons créé en utilisant le fichier Producer.sh comme indiqué ci-dessous :
$ sudo -dans linuxhint / opter / kafka / poubelle / kafka-console-producteur.sh --liste des courtiers hôte local : 9092 --sujet linuxhint1 
Ensuite, ouvrez un autre shell et accédez au sujet Kafka à l'aide de consumer.sh.

Avec les deux shells ouverts, vous pouvez envoyer un message sur la console du producteur. Tout ce que vous tapez est reflété dans la console consommateur confirmant que notre Apache Kafka est opérationnel.
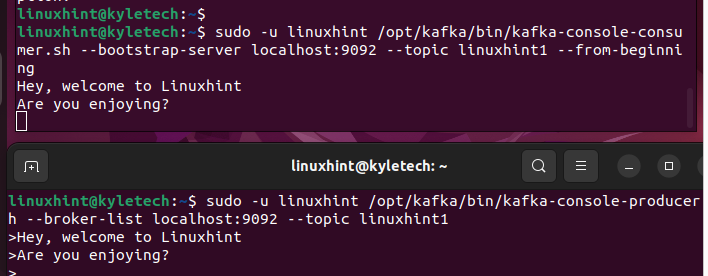
Conclusion
Avec ce guide, vous avez maintenant toutes les étapes que vous pouvez suivre pour installer Apache Kafka dans votre Ubuntu 22.04. J'espère que vous avez réussi à suivre chaque étape et à installer votre Apache Kafka et à créer des sujets pour exécuter une simple production consommateur et producteur. Vous pouvez implémenter la même chose dans une grande production.