LangChain est le framework qui peut être utilisé pour importer des bibliothèques et des dépendances pour créer des grands modèles linguistiques ou LLM. Les modèles de langage utilisent la mémoire pour stocker des données ou un historique dans la base de données à titre d'observation afin d'obtenir le contexte de la conversation. La mémoire est configurée pour stocker les messages les plus récents afin que le modèle puisse comprendre les invites ambiguës données par l'utilisateur.
Ce blog explique le processus d'utilisation de la mémoire dans LLMChain via LangChain.
Comment utiliser la mémoire dans LLMChain via LangChain ?
Pour ajouter de la mémoire et l'utiliser dans LLMChain via LangChain, la bibliothèque ConversationBufferMemory peut être utilisée en l'important depuis LangChain.
Pour apprendre le processus d'utilisation de la mémoire dans LLMChain via LangChain, parcourez le guide suivant :
Étape 1 : Installer les modules
Tout d’abord, démarrez le processus d’utilisation de la mémoire en installant LangChain à l’aide de la commande pip :
pip installer langchain
Installez les modules OpenAI pour obtenir ses dépendances ou bibliothèques afin de créer des LLM ou des modèles de chat :
pip installer openai
Configurer l'environnement pour l'OpenAI en utilisant sa clé API en important les bibliothèques os et getpass :
importez-nousimporter getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('Clé API OpenAI :')
Étape 2 : Importer des bibliothèques
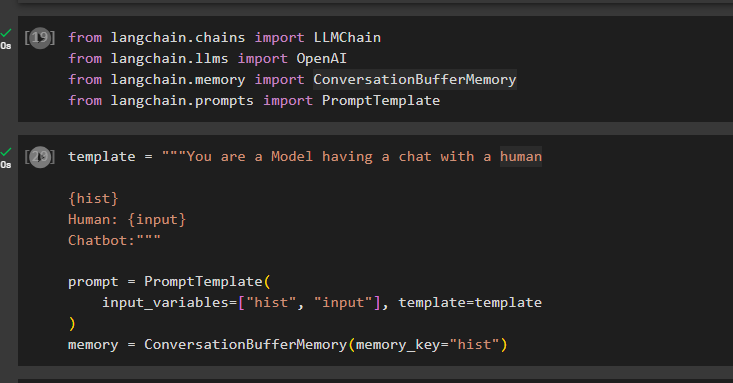
Après avoir configuré l'environnement, importez simplement les bibliothèques comme ConversationBufferMemory depuis LangChain :
à partir de langchain.chains importer LLMChainà partir de langchain.llms, importer OpenAI
à partir de langchain.memory importer ConversationBufferMemory
à partir de langchain.prompts, importez PromptTemplate
Configurez le modèle pour l'invite en utilisant des variables telles que « input » pour obtenir la requête de l'utilisateur et « hist » pour stocker les données dans la mémoire tampon :
template = '''Vous êtes un modèle en train de discuter avec un humain{historique}
Humain : {entrée}
Chatbot :'''
invite = Modèle d'invite (
input_variables=['hist', 'input'], template=modèle
)
mémoire = ConversationBufferMemory(memory_key='hist')
Étape 3 : configuration de LLM
Une fois le modèle de requête créé, configurez la méthode LLMChain() à l'aide de plusieurs paramètres :
llm = OpenAI()llm_chain = LLMChain(
llm=llm,
invite = invite,
verbeux = Vrai,
mémoire = mémoire,
)
Étape 4 : tester LLMChain
Après cela, testez LLMChain à l'aide de la variable d'entrée pour obtenir l'invite de l'utilisateur sous forme textuelle :
llm_chain.predict(input='Salut mon ami') 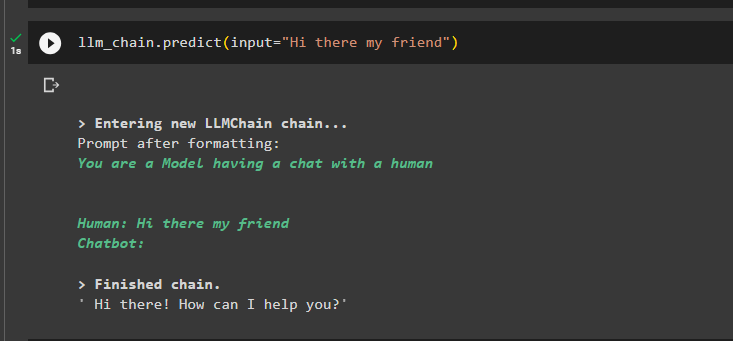
Utilisez une autre entrée pour obtenir les données stockées dans la mémoire afin d'extraire la sortie à l'aide du contexte :
llm_chain.predict(input='Bien ! Je vais bien - comment vas-tu') 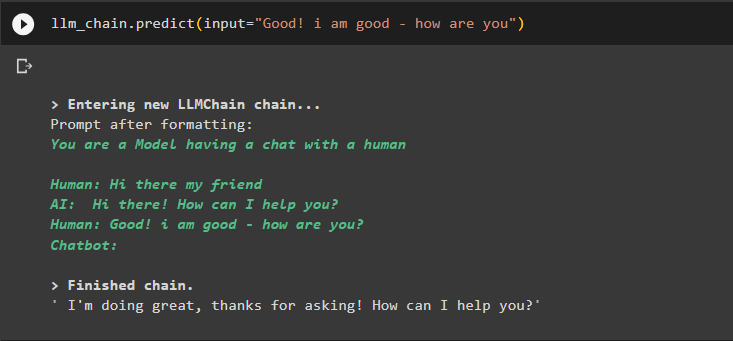
Étape 5 : Ajout de mémoire à un modèle de discussion
La mémoire peut être ajoutée à la LLMChain basée sur un modèle de discussion en important les bibliothèques :
depuis langchain.chat_models importer ChatOpenAIà partir de langchain.schema importer SystemMessage
à partir de langchain.prompts, importez ChatPromptTemplate, HumanMessagePromptTemplate, MessagesPlaceholder
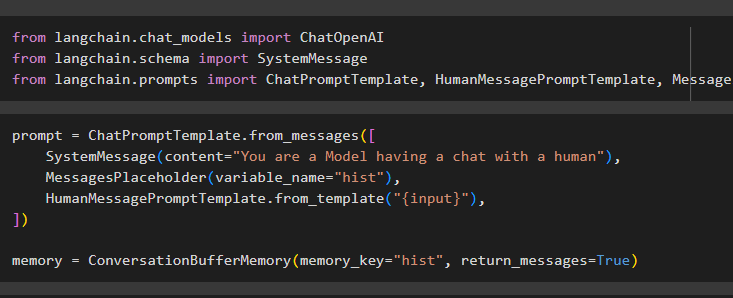
Configurez le modèle d'invite à l'aide de ConversationBufferMemory() en utilisant différentes variables pour définir l'entrée de l'utilisateur :
prompt = ChatPromptTemplate.from_messages([SystemMessage(content='Vous êtes un modèle en train de discuter avec un humain'),
MessagesPlaceholder(variable_),
HumanMessagePromptTemplate.from_template('{input}'),
])
mémoire = ConversationBufferMemory(memory_key='hist', return_messages=True)
Étape 6 : Configuration de LLMChain
Configurez la méthode LLMChain() pour configurer le modèle à l'aide de différents arguments et paramètres :
llm = ChatOpenAI()chat_llm_chain = LLMChain(
llm=llm,
invite = invite,
verbeux = Vrai,
mémoire = mémoire,
)
Étape 7 : tester LLMChain
À la fin, testez simplement le LLMChain en utilisant l'entrée afin que le modèle puisse générer le texte en fonction de l'invite :
chat_llm_chain.predict(input='Salut mon ami') 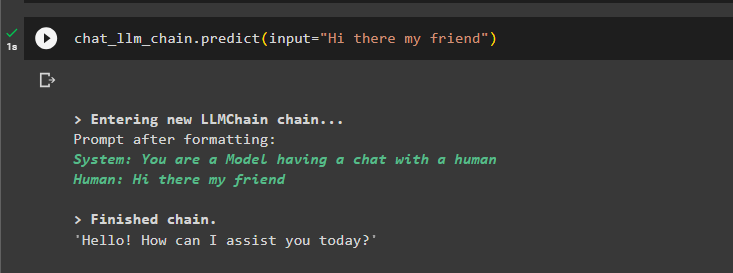
Le modèle a stocké la conversation précédente dans la mémoire et l'affiche avant la sortie réelle de la requête :
llm_chain.predict(input='Bien ! Je vais bien - comment vas-tu') 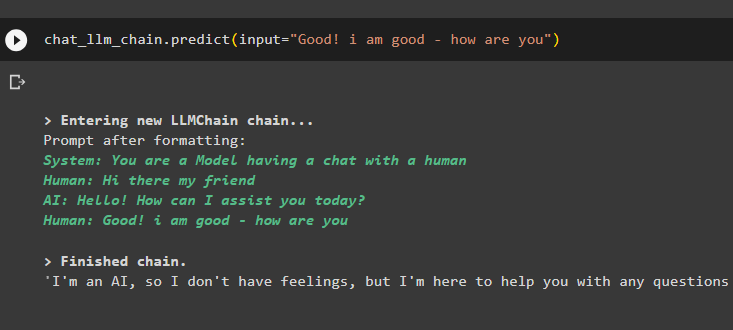
Il s’agit d’utiliser la mémoire dans LLMChain en utilisant LangChain.
Conclusion
Pour utiliser la mémoire de LLMChain via le framework LangChain, installez simplement les modules pour configurer l'environnement afin d'obtenir les dépendances des modules. Après cela, importez simplement les bibliothèques de LangChain pour utiliser la mémoire tampon pour stocker la conversation précédente. L'utilisateur peut également ajouter de la mémoire au modèle de discussion en créant la LLMChain, puis en testant la chaîne en fournissant l'entrée. Ce guide a expliqué le processus d'utilisation de la mémoire dans LLMChain via LangChain.