Elasticsearch est une solution robuste et appréciée pour stocker des données volumineuses, non structurées et semi-structurelles. Il s'agit purement d'une base de données NoSQL et utilise une approche totalement différente pour stocker, gérer et récupérer des données. Il stocke les données dans un document au format JSON et utilise des API de repos pour effectuer différentes opérations sur les données stockées.
Dans ce blog, nous allons démontrer :
- Comment fonctionne Elasticsearch pour stocker et rechercher des données ?
- Qu'est-ce qu'un document Elasticsearch ?
- Comment stocker des données dans un document Elasticsearch ?
Comment fonctionne Elasticsearch pour stocker et rechercher des données ?
Les principaux composants ou hiérarchie d'Elasticsearch utilisés pour stocker les données sont répertoriés ci-dessous :
- Document: Le document est la partie principale d'Elasticsearch qui stocke les données au format JSON. Comme
- Indices : Les indices sont appelés indices. C'est une collection de documents. Comme dans SQL, on l'appelle une base de données.
- Index inversés : Il prend en charge la recherche en texte intégral très rapide. Il stocke le mot comme index et le nom du document comme référence.
Qu'est-ce qu'un document Elasticsearch ?
Le document Elasticsearch est une unité de stockage de données au format JSON. Comme dans les bases de données relationnelles, le document peut être appelé une table ou une ligne d'une base de données stockée dans un index. L'index peut contenir plusieurs documents et est appelé une base de données comportant plusieurs tables. Il stocke généralement une structure de données complexe et stérilise les données au format JSON.
De plus, chaque document peut contenir plusieurs champs qui sont ' valeur clé ” paires pour stocker les données tout comme une table a plusieurs colonnes ou champs dans une base de données relationnelle. Ensuite, ces paires clé-valeur sont censées être indexées de manière à déterminer le mappage du document. Le mappage définit ensuite le type de données du document en fonction des données de champ telles que le texte, le flottant, le point géographique, l'heure et bien d'autres.
Elasticsearch ne nous a jamais obligés à prédéfinir la structure du champ d'index et les documents peuvent avoir une structure de champ différente dans un index. Toutefois, si le mappage du champ est défini pour un type de données spécifique, tous les documents Elasticsearch d'un index doivent suivre le même type de mappage. Pour vérifier le fonctionnement du document pour stocker des données dans Elasticsearch, passez à la section suivante.
Comment stocker des données dans un document Elasticsearch ?
Pour stocker des données dans Elasticsearch, l'utilisateur doit d'abord créer un index. Ensuite, spécifiez les champs pour stocker les données dans le document Elasticsearch. Pour la démonstration, suivez les étapes répertoriées.
Étape 1 : Démarrer Elasticsearch
Pour exécuter la base de données ou le moteur Elasticsearch sur le système, lancez le terminal système tel que l'invite de commande. Après cela, visitez le ' poubelle ' dossier d'Elasticsearch via le ' CD ' commande:
CD C:\Users\Dell\Documents\Elk stack\elasticsearch-8.7.0\bin
Après cela, exécutez le fichier batch d'Elasticsearch pour exécuter la base de données sur le système :
elasticsearch.bat
Étape 2 : Démarrez Kibana
Ensuite, exécutez le Kibana sur le système. Pour cela, rendez-vous sur son « poubelle ' dossier à partir de l'invite de commande :
CD C:\Users\Dell\Documents\Elk stack\kibana-8.7.0\bin
Ensuite, exécutez la commande ci-dessous pour commencer à exécuter Kibana :
kibana.bat
Note: Si vous n'avez pas installé et configuré Elasticsearch et Kibana sur le système, accédez à nos publications et consultez la procédure étape par étape pour les installer sur le système.
Pour Elasticsearch, visitez notre « Installer et configurer Elasticsearch avec .zip sous Windows ' article. Pour configurer Kibana sur Windows, suivez les instructions ' Configurer Kibana pour Elasticsearch ' article.
Étape 3 : Connectez-vous à Kibana
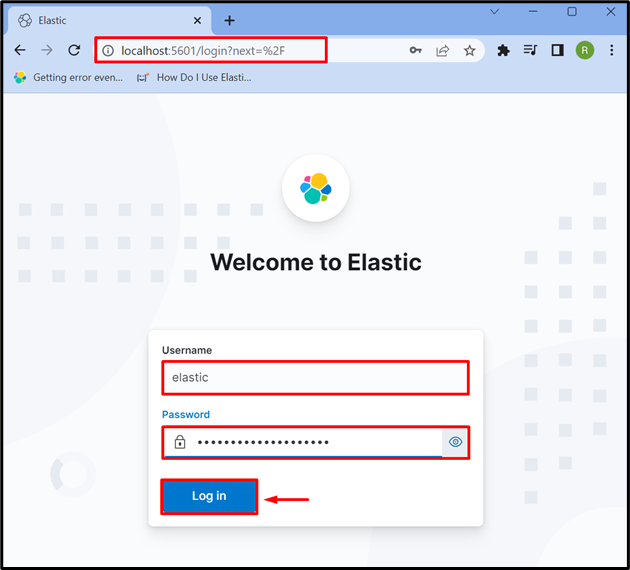
Après avoir démarré Kibana sur le système, accédez à l'adresse par défaut de Kibana ' hôte local : 5601 ' dans le navigateur, et fournissez les identifiants de connexion d'Elasticsearch tels que ' élastique ” utilisateur et mot de passe. Après cela, appuyez sur le ' Se connecter ' bouton:
Étape 4 : Ouvrir l'outil de développement Kibana
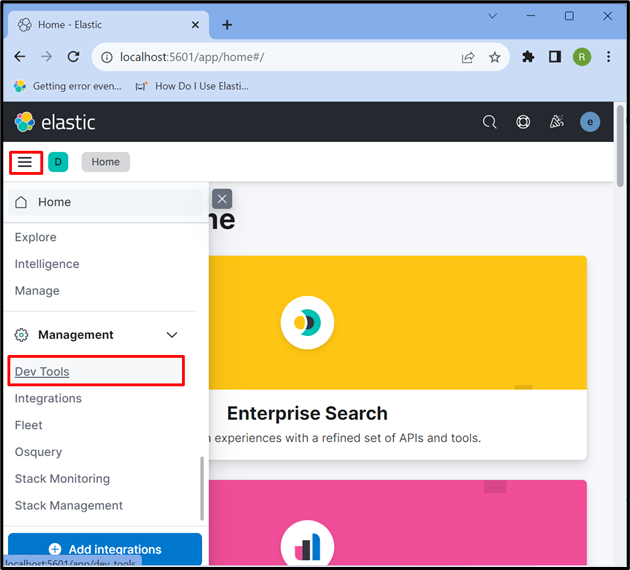
Après cela, cliquez sur le ' Trois barres horizontales ' icône et ouvrez le Kibana ' Outil de développement ” pour utiliser des API pour stocker, récupérer et mettre à jour les données :
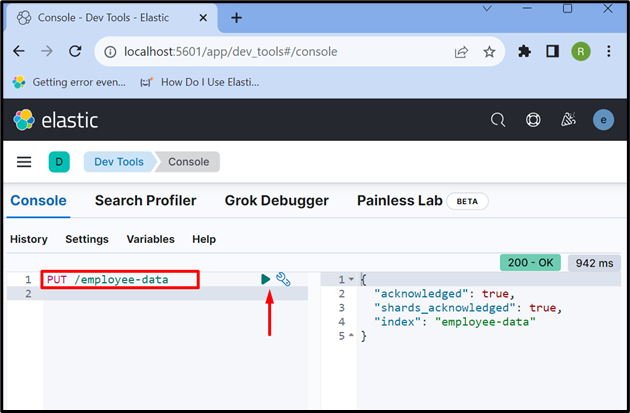
Étape 5 : Créer un index
Maintenant, créez un nouvel index en utilisant ' PUT /
La sortie montre que le ' données-employé ” l'index est créé avec succès :
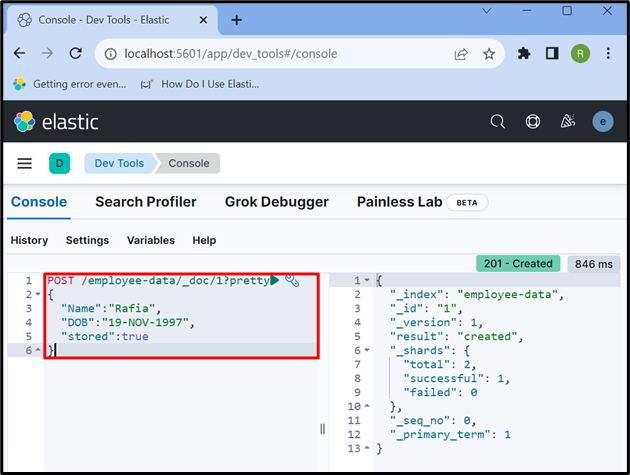
Étape 6 : Insérer des données dans le document
Maintenant, utilisez le ' POSTE ” API pour stocker les données dans l'index. Dans la demande ci-dessous, ' données-employé ' est un index d'Elasticsearch, ' _doc ' est utilisé pour stocker des données dans le document Elasticsearch, et ' 1 ' est l'identifiant :
POSTE / données-employé / _doc / 1 ?joli{
'Nom' : 'Raphia' ,
'date de naissance' : '19-NOV-1997' ,
'stocké' :vrai
}
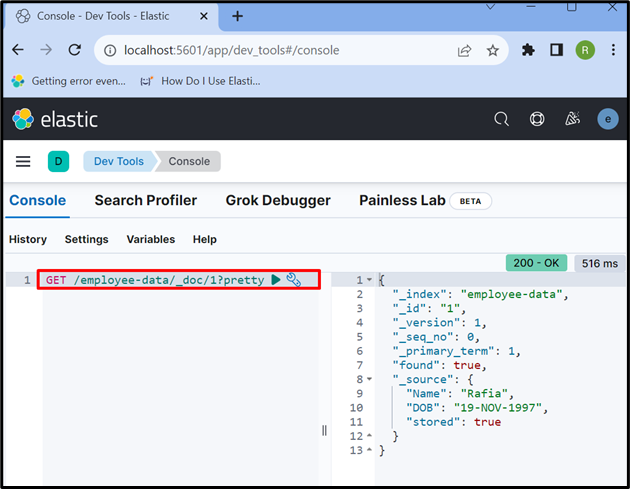
Étape 7 : Récupérer les données du document Elasticsearch
Pour accéder aux données de l'index ou du document Elasticsearch, utilisez le ' OBTENIR ” API tel qu'utilisé ci-dessous :
OBTENIR / données-employé / _doc / 1 ?joli
La sortie montre que nous avons réussi à extraire les données du document Elasticsearch ayant l'id ' 1 ” :
C'est tout sur le document Elasticsearch.
Conclusion
Le document Elasticsearch est généralement utilisé pour stocker des données au format JSON. Comme dans les bases de données relationnelles, le document peut être appelé une ligne stockée dans un index. Ces index peuvent avoir plusieurs documents, tout comme les bases de données ont des tables différentes. Ces documents contiennent plusieurs champs qui sont ' valeur clé ” paires pour stocker les données. Cet article a expliqué ce que sont les documents Elasticsearch et comment ils fonctionnent dans Elasticsearch.