Table des matières
- Introduction
- Qu'est-ce que le tri par fusion en C++
- Approche Diviser pour mieux régner
- Algorithme de tri par fusion
- Implémentation de Merge Sort en C++
- Conclusion
1. Introduction
Les algorithmes de tri en informatique sont utilisés pour classer les données par ordre croissant ou décroissant. Il existe plusieurs algorithmes de tri avec des propriétés distinctes disponibles. Le tri par fusion est l'une des méthodes en C++ qui peut trier les tableaux.
2. Qu'est-ce que le tri par fusion en C++
Le tri par fusion utilise la technique diviser pour régner qui peut organiser les éléments d'un tableau. Il peut également trier la liste des éléments en C++. Il divise l'entrée en deux moitiés, trie chaque moitié indépendamment, puis les fusionne dans le bon ordre.
3. Approche Diviser pour mieux régner
L'algorithme de tri applique une stratégie de division pour régner, qui implique de partitionner le tableau d'entrée en sous-tableaux plus petits, de les résoudre séparément, puis de fusionner les résultats pour produire une sortie triée. Dans le cas du tri par fusion, le tableau est divisé récursivement en deux moitiés jusqu'à ce qu'il ne reste qu'un seul élément dans chaque moitié.
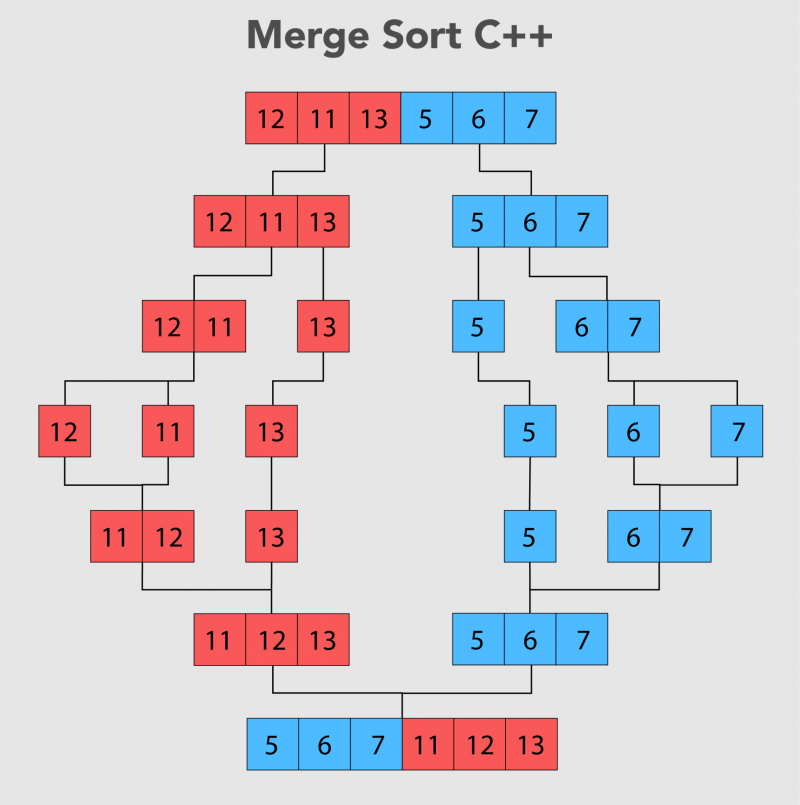
4. Algorithme de tri par fusion
L'algorithme de tri par fusion se compose de deux étapes principales : diviser et fusionner. Les étapes sont les suivantes:
4.1 Diviser
L'algorithme de tri par fusion suit une stratégie de division pour régner pour trier les éléments dans un tableau.
- La première étape de l'algorithme vérifiera les éléments du tableau. S'il contient un élément, il est déjà considéré comme trié et l'algorithme renverra le même tableau sans aucun changement.
- Si le tableau contient plus d'un élément, l'algorithme le divise en deux moitiés : la moitié gauche et la moitié droite.
- L'algorithme de tri par fusion est ensuite appliqué de manière récursive aux moitiés gauche et droite du tableau, les divisant efficacement en sous-tableaux plus petits et les triant individuellement.
- Ce processus récursif se poursuit jusqu'à ce que les sous-tableaux ne contiennent qu'un seul élément chacun (selon l'étape 1), auquel cas ils peuvent être fusionnés pour produire un tableau de sortie trié final.
4.2 Fusionner
Nous allons maintenant voir les étapes pour fusionner les tableaux :
- La première étape de l'algorithme de tri par fusion consiste à créer un tableau vide.
- L'algorithme procède ensuite à la comparaison des premiers éléments des moitiés gauche et droite du tableau d'entrée.
- Le plus petit des deux éléments est ajouté au nouveau tableau, puis supprimé de sa moitié respective du tableau d'entrée.
- Les étapes 2 et 3 sont ensuite répétées jusqu'à ce que l'une des moitiés soit vidée.
- Tous les éléments restants dans la moitié non vide sont ensuite ajoutés au nouveau tableau.
- Le tableau résultant est maintenant entièrement trié et représente la sortie finale de l'algorithme de tri par fusion.
5. Implémentation de Merge Sort en C++
Pour implémenter le tri par fusion en C++, deux méthodes différentes sont suivies. La complexité temporelle des deux méthodes est équivalente, mais leur utilisation des sous-réseaux temporaires diffère.
La première méthode pour le tri par fusion en C++ utilise deux sous-tableaux temporaires, tandis que la seconde n'en utilise qu'un seul. Il convient de noter que la taille totale des deux sous-réseaux temporaires dans la première méthode est égale à la taille du réseau d'origine dans la seconde méthode, de sorte que la complexité spatiale reste constante.
- Méthode 1 - Utilisation de deux sous-tableaux temporaires
- Méthode 2 - Utilisation d'un sous-réseau Temp
Méthode 1 - Utilisation de deux sous-tableaux temporaires
Voici un exemple de programme pour le tri par fusion en C++ utilisant la méthode 1, qui utilise deux sous-tableaux temporaires :
#includeen utilisant l'espace de noms std ;
annuler fusionner ( entier arr [ ] , entier je , entier m , entier r )
{
entier n1 = m - je + 1 ;
entier n2 = r - m ;
entier L [ n1 ] , R [ n2 ] ;
pour ( entier je = 0 ; je < n1 ; je ++ )
L [ je ] = arr [ je + je ] ;
pour ( entier j = 0 ; j < n2 ; j ++ )
R [ j ] = arr [ m + 1 + j ] ;
entier je = 0 , j = 0 , k = je ;
alors que ( je < n1 && j < n2 ) {
si ( L [ je ] <= R [ j ] ) {
arr [ k ] = L [ je ] ;
je ++ ;
}
autre {
arr [ k ] = R [ j ] ;
j ++ ;
}
k ++ ;
}
alors que ( je < n1 ) {
arr [ k ] = L [ je ] ;
je ++ ;
k ++ ;
}
alors que ( j < n2 ) {
arr [ k ] = R [ j ] ;
j ++ ;
k ++ ;
}
}
annuler tri par fusion ( entier arr [ ] , entier je , entier r )
{
si ( je < r ) {
entier m = je + ( r - je ) / 2 ;
tri par fusion ( arr , je , m ) ;
tri par fusion ( arr , m + 1 , r ) ;
fusionner ( arr , je , m , r ) ;
}
}
entier principal ( )
{
entier arr [ ] = { 12 , onze , 13 , 5 , 6 , 7 } ;
entier arr_size = taille de ( arr ) / taille de ( arr [ 0 ] ) ;
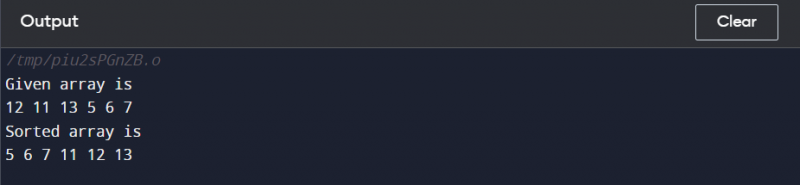
écoute << 'Le tableau donné est \n ' ;
pour ( entier je = 0 ; je < arr_size ; je ++ )
écoute << arr [ je ] << ' ' ;
tri par fusion ( arr , 0 , arr_size - 1 ) ;
écoute << ' \n Le tableau trié est \n ' ;
pour ( entier je = 0 ; je < arr_size ; je ++ )
écoute << arr [ je ] << ' ' ;
retour 0 ;
}
Dans ce programme, la fonction de fusion prend trois arguments arr, l et r, qui représentent le tableau à trier et montrent les indices du sous-tableau qui doit être fusionné. La fonction trouve d'abord les tailles des deux sous-tableaux à fusionner, puis crée deux sous-tableaux temporaires L et R pour stocker les éléments de ces sous-tableaux. Il compare ensuite les éléments de L et R et les fusionne dans le tableau d'origine nommé arr Dans l'ordre croissant.
La technique diviser pour régner est utilisée par la fonction mergeSort pour diviser le tableau en deux moitiés de manière récursive jusqu'à ce qu'il ne reste qu'un seul élément dans le sous-tableau. Il fusionne ensuite les deux sous-tableaux en un sous-tableau trié. La fonction continue de fusionner les sous-tableaux à moins qu'elle ne trie le tableau complet.
Dans la fonction principale, nous définissons un tableau arr avec 6 éléments et appelons la fonction mergeSort pour le trier. A la fin du code, le tableau trié est imprimé.
Méthode 2 - Utilisation d'un sous-réseau Temp
Voici un exemple de programme pour le tri par fusion en C++ utilisant la méthode 2, qui utilise un seul sous-tableau temporaire :
#includeen utilisant l'espace de noms std ;
annuler fusionner ( entier arr [ ] , entier je , entier m , entier r )
{
entier je , j , k ;
entier n1 = m - je + 1 ;
entier n2 = r - m ;
// Créer des sous-tableaux temporaires
entier L [ n1 ] , R [ n2 ] ;
// Copie les données dans les sous-tableaux
pour ( je = 0 ; je < n1 ; je ++ )
L [ je ] = arr [ je + je ] ;
pour ( j = 0 ; j < n2 ; j ++ )
R [ j ] = arr [ m + 1 + j ] ;
// Fusionner les sous-tableaux temporaires dans le tableau d'origine
je = 0 ;
j = 0 ;
k = je ;
alors que ( je < n1 && j < n2 ) {
si ( L [ je ] <= R [ j ] ) {
arr [ k ] = L [ je ] ;
je ++ ;
}
autre {
arr [ k ] = R [ j ] ;
j ++ ;
}
k ++ ;
}
// Copie les éléments restants de L[]
alors que ( je < n1 ) {
arr [ k ] = L [ je ] ;
je ++ ;
k ++ ;
}
// Copie les éléments restants de R[]
alors que ( j < n2 ) {
arr [ k ] = R [ j ] ;
j ++ ;
k ++ ;
}
}
annuler tri par fusion ( entier arr [ ] , entier je , entier r )
{
si ( je < r ) {
entier m = je + ( r - je ) / 2 ;
// Trier les moitiés gauche et droite récursivement
tri par fusion ( arr , je , m ) ;
tri par fusion ( arr , m + 1 , r ) ;
// Fusionner les deux moitiés triées
fusionner ( arr , je , m , r ) ;
}
}
entier principal ( )
{
entier arr [ ] = { 12 , onze , 13 , 5 , 6 , 7 } ;
entier arr_size = taille de ( arr ) / taille de ( arr [ 0 ] ) ;
cout << 'Le tableau donné est \n ' ;
pour ( entier je = 0 ; je < arr_size ; je ++ )
cout << arr [ je ] << ' ' ;
tri par fusion ( arr , 0 , arr_size - 1 ) ;
cout << ' \n Le tableau trié est \n ' ;
pour ( entier je = 0 ; je < arr_size ; je ++ )
cout << arr [ je ] << ' ' ;
retour 0 ;
}
Ce programme est comme le précédent, mais au lieu d'utiliser deux sous-tableaux temporaires L et R, il utilise un seul sous-tableau temporaire temp. La fonction de fusion fonctionne de la même manière qu'avant, mais au lieu de copier les données vers L et R, elle les copie vers temp. Il fusionne ensuite les éléments du tableau temporaire dans le arr qui est le tableau d'origine.
La fonction mergeSort est la même qu'avant, sauf qu'elle utilise temp au lieu de L et R pour stocker le sous-tableau temporaire.
Dans la fonction principale, nous définissons un tableau arr avec 6 éléments et appelons la fonction mergeSort pour le trier. L'exécution du code se termine par l'affichage du tableau trié à l'écran.
Conclusion
Le tri par fusion est un algorithme qui trie les éléments d'un tableau. Il utilise la technique diviser pour mieux régner et effectue des comparaisons entre les éléments. Le tri par fusion en C++ a une complexité temporelle de O(n log n) et est particulièrement efficace pour trier de grands tableaux. Bien qu'il nécessite de la mémoire supplémentaire pour stocker les sous-réseaux fusionnés, sa stabilité en fait un choix populaire pour le tri.