La méthode 'Series.to_csv()' dans Pandas génère l'objet série spécifié dans une notation de valeurs séparées par des virgules (csv). Cette fonction prend simplement les valeurs d'une série et modifie leur format en ajoutant des virgules pour la séparation des valeurs d'index et de colonne.
Pour utiliser cette fonction, nous devons utiliser la syntaxe suivante :

Cet article vous fournira deux techniques différentes pour apprendre comment utiliser cette méthode dans un programme python.
Exemple # 1 : Utilisation de la méthode Series.to_csv() pour convertir une série avec DatetimeIndex en valeurs séparées par des virgules
Pour modifier une série au format CSV, nous utiliserons la fonction 'Series.to_csv()'. Cette illustration générera une série avec un DatetimeIndex, puis la convertira dans un format de valeurs séparées par des virgules.
Pour mettre cette méthode en service, nous devons disposer d'un outil prenant en charge la programmation python. L'outil 'Spyder' est choisi pour compiler les codes. Pour écrire le script dessus, nous avons d'abord lancé l'outil installé dans notre système. Le programme python a besoin d'une bibliothèque pour exercer ses méthodes afin d'atteindre le résultat requis. La bibliothèque que nous avons chargée ici est le 'Pandas'. Dans la même ligne de code, l'alias de cette bibliothèque est identifié comme 'pd'. Ainsi, partout dans le programme, nous devons écrire des 'pandas' pour accéder à une fonction. Nous écrirons plutôt 'pd'.
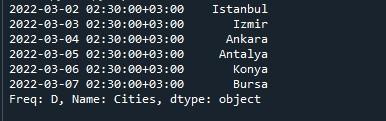
La première étape pour commencer avec le code est de générer une série Pandas. Nous devons écrire 'pd' pour utiliser la méthode de création de séries à partir de pandas. La fonction 'pd.Series()' est appelée pour construire une série avec les valeurs spécifiées. Les valeurs que nous avons fournies pour la série sont « Istanbul », « Izmir », « Ankara », « Ankara », « Antalya », « Konya » et « Bursa ». Si vous souhaitez donner un nom à ce tableau de valeurs, vous pouvez le faire en utilisant le paramètre 'nom'. Ici, nous avons nommé ce tableau de valeurs 'Cities' car il contient les noms de 6 villes. Pour stocker cette série, un objet de série 'Turquie' a été créé.
Pour créer un DatetimeIndex, nous avons invoqué la méthode 'pd.date_range()'. Entre les parenthèses de cette fonction, nous avons passé 4 arguments qui sont : 'start', 'freq', 'periods', et 'tz'.
L'argument 'début' prend une date et une heure pour commencer à générer une plage de dates à partir de celle-ci. Ici, nous avons spécifié la date et l'heure de début comme '2022-03-02 02:30'. Le paramètre 'freq' classe la fréquence pour la plage de dates. Nous lui avons donc attribué la valeur 'D'. Maintenant, il va créer une plage de dates sur la fréquence quotidienne. L'argument 'période' est défini sur '6', ce qui signifie qu'il générera une plage de dates de 6 jours. Le dernier paramètre est 'tz' qui spécifie le fuseau horaire pour la zone spécifiée. Nous avons spécifié le fuseau horaire pour 'Asie/Istanbul'.
Pour stocker cette plage de dates, nous avons créé une variable 'Datetime'. Pour définir le DatetimeIndex, nous avons utilisé la propriété 'Series.index'. Le nom de la série « Turquie » est fourni avec la propriété « .index » et lui est affecté la plage horaire de date stockée dans la variable « Datetime ». Ainsi, la propriété 'index' prendra les valeurs de la variable 'Datetime' et en fera la liste d'index de la série 'Turquie'. Enfin, pour afficher la série de sortie, nous avons utilisé la méthode 'print ()' et passé la série 'Turquie' en entrée pour afficher son contenu.
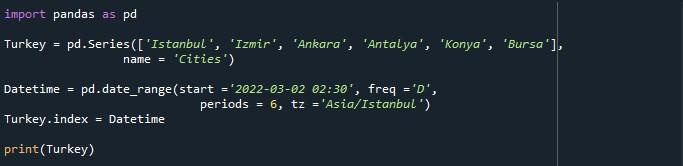
Nous venons d'appuyer sur l'option 'Exécuter le fichier' pour exécuter le script. Par conséquent, nous pouvons voir une série avec le DatetimeIndex commençant par '2022-03-02 02:30:00+03:00' et se terminant à '2022-03-07 02:30:00+03:00' créant une période de 6 jours. Sous la série, la « Fréq : D », le nom de la liste de tableaux « Villes » et le dtype « objet » sont également mentionnés.
Maintenant, nous allons apprendre à convertir cette série que nous venons de voir dans l'instantané ci-dessus au format CSV. Pour modifier la série en valeurs séparées par des virgules, nous avons une méthode fournie par le module pandas qui est 'Series.to_csv()'. Cette méthode prend les valeurs de la série fournie et ajoute des virgules entre les valeurs de la colonne.
La fonction 'Series.to_csv()' est appelée. Le nom de la série que nous voulons convertir est mentionné avec la méthode comme 'Turkey.to_csv()'. Pour conserver les valeurs séparées par des virgules, nous avons créé une variable 'Comma_Separated' puis mis son contenu sur la fenêtre de sortie en invoquant la fonction 'print()'.

Voici notre série au format csv. Nous pouvons voir dans l'instantané que l'index et les valeurs de série ont été séparés à l'aide de virgules.

Exemple # 2 : Utilisation de la méthode Series.to_csv() pour convertir une série avec des valeurs NaN en valeurs séparées par des virgules
La deuxième technique pour exercer la méthode 'Series.to_csv()' consiste à appliquer cette méthode pour convertir une série contenant des entrées nulles au format CSV.
Nous avons initialement importé les packages nécessaires. Le 'pd' devient un alias pour pandas et 'np' un alias pour numpy. La boîte à outils numpy est chargée ici car nous allons créer des entrées nulles dans notre série en utilisant 'np.NaN' lors de sa création à l'aide de la méthode pandas 'pd.Series ()'.
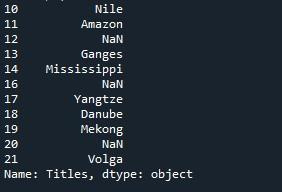
La fonction 'pd.Series()' est invoquée pour construire une série de pandas avec ces valeurs : 'Nile', 'Amazon', np.NaN, 'Ganges', 'Mississippi', 'np.NaN', 'Yangtze', « Danube », « Mékong », « np.NaN » et « Volga ». Il y a un total de 21 valeurs définies pour la série dont 3 entrées contiennent des valeurs 'np.NaN', ce qui signifie que 3 valeurs manquent dans la série. La propriété 'name' spécifie le nom de ce tableau de valeurs que nous avons fourni 'Titres'. La propriété 'index' est utilisée pour définir la liste d'index définie par l'utilisateur au lieu d'aller avec la liste par défaut.
Ici, nous voulons la liste d'index avec les valeurs '10', '11', '12', '13', '14', '16', '17', '18', '19', '20', et 21'. Maintenant, notre série aura la liste d'index commençant par '10' au lieu de '0'. Maintenant, stockez cette série afin que nous puissions l'utiliser plus tard dans le programme. Nous avons initialisé un objet de série 'Rivers' et lui attribuons la série de sortie générée à partir de l'appel de la méthode 'pd.Series()'. La série peut être vue en l'affichant à l'aide de la fonction 'print()' de python.
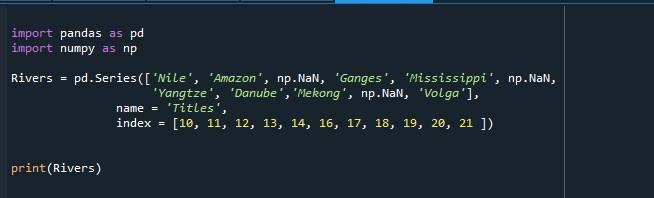
La sortie rendue sur le terminal a imprimé une série dont la liste d'index commence à 10 et se termine à 21, ce qui signifie que la série a 21 valeurs.
La série sera transformée au format CSV avec la méthode 'Series.to_csv()'.
Nous avons invoqué la méthode 'Series.to_csv()' avec notre série 'Turquie'. Par conséquent, cette méthode prendra les valeurs de la série 'Turquie' et les convertira dans un format de valeurs séparées par des virgules. Le résultat est enregistré dans la variable 'Converted_csv'. Et finalement, la série convertie est imprimée à l'aide de la fonction 'print()'.

Dans l'instantané du résultat ci-dessous, vous pouvez voir que les valeurs de la série sont maintenant modifiées d'une manière où une virgule est utilisée pour les séparer de la liste d'index. De plus, là où les valeurs manquent, seul le numéro d'index est imprimé avec une virgule.

Conclusion
La modification d'une série de pandas au format CSV est une approche pratique. Ceci peut être réalisé en utilisant la fonction pandas 'Series.to_csv()'. Ce guide a mis en pratique deux techniques pour employer cette méthode. Dans la première illustration, nous avons invoqué cette méthode pour convertir une série avec un DatetimeIndex en un format de valeurs séparées par des virgules. La deuxième instance a utilisé la fonction 'Series.to_csv()' pour modifier une série avec des entrées manquantes dans un format CSV. Les deux techniques ont été pratiquement mises en œuvre à l'aide de l'outil 'Spyder' sur le système d'exploitation Windows.